
Googleが開発した機械学習のためのオープンソースソフトウェア、TensorFlow。
TensorFlowで学習するデータをインプットさせる場合、CSVやNumpyなどで用意したデータをそのまま利用することもできますが、TensorFlowが推奨フォーマットとして提供しているTFRecordもあります。
TFRecordは、「メモリに収まらないような大きなデータを処理できるようにしたもので、シンプルなレコード指向のバイナリのフォーマット」ということです。
(参考:TensorFlow Programmer’s Guide – Importing Data – Consuming TFRecord data)
少量のデータで処理する場合は、事前にデータをメモリ上に乗せてしまえばいいですが、ディープラーニングのように大量のデータを扱う場合は、それが出来ないこともあるので、TFRecordを活用することになると思います。
今回は、TFRecordの基本として「作成」と「読み込み」をします。
(次回以降では、TFRecordを実際に学習に用いてみようと思っています。)
<今回の内容>
- 画像ファイルから、TFRecordファイルを作成する
- TFRecordファイルの中身を確認し、もう一度画像ファイルに戻してみる
それでは、始める前に、後述のコード実行に必要なライブラリをインポートしておきます。
|
1 2 3 4 5 6 |
from tensorflow.examples.tutorials.mnist import input_data from PIL import Image import os import numpy as np import tensorflow as tf import glob |
目次
1.画像ファイルから、TFRecordファイルを作成する
1-1.画像の準備 (MNISTから画像を生成する)
画像ファイルとして、TensorFlowが用意しているMNIST(シンプルなコンピュータ・ビジョンのデータセット。手書き数字画像で構成されています。)を利用します。
まずMNISTのデータを読み込みます。
|
1 |
mnist = input_data.read_data_sets("MNIST_data",one_hot=True) |
フォルダ「mnistVisualize」に、ファイル「X-Y.png」(X:0からの連番、Y:0~9の正解ラベル)を作成します。
- MNISTのデータは、単色なので、グレースケールとして処理しています。
- MNISTのデータは、0~1の間におさまるように正規化されているので、255倍しています。
|
1 2 3 4 5 6 7 8 9 |
def matrix_to_image(imageMatrix,imageShape,dirName,labal): imageMatrix = imageMatrix * 255 # 画像データの値を0~255の範囲に変更する for i in range(0,imageMatrix.shape[0]): imageArray = imageMatrix[i].reshape(imageShape) outImg = Image.fromarray(imageArray) outImg = outImg.convert("L") # グレースケール outImg.save(dirName + os.sep + str(i) + "-" + str(np.argmax(labal[i])) + ".jpg", format="JPEG") matrix_to_image(mnist.test.images, imageShape = (28,28), dirName="mnistVisualize", labal = mnist.test.labels ) |
(結果)
以下は、フォルダ「mnistVisualize」に作成された画像をエクスプローラで表示したものです。画像を縮小表示していますが、画像中の数字とファイル名に付与したラベル(Y)が一致していることが分かります。

1-2.画像からTFRecordファイルを作成する
前述で作成した、「mnistVisualize」フォルダにあるファイルを1件ずつ読み込み、TFRecordファイルに書き込みます。
- 数値データは「int64_list」、画像データは「bytes_list」で定義します。
- ラベルはファイル名の一部から取得しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
OUTPUT_TFRECORD_NAME = "test_tf_file.tfrecords" # アウトプットするTFRecordファイル名 def CreateTensorflowReadFile( img_files, out_file): with tf.python_io.TFRecordWriter( out_file ) as writer: for f in img_files: # ファイルを開く with Image.open(f).convert("L") as image_object: # グレースケール image = np.array(image_object) height = image.shape[0] width = image.shape[1] image_raw = image.tostring() label = int( f[ f.rfind("-") + 1 : -4] ) # ファイル名からラベルを取得 example = tf.train.Example(features=tf.train.Features(feature={ "height": tf.train.Feature(int64_list=tf.train.Int64List(value=[height])), "width": tf.train.Feature(int64_list=tf.train.Int64List(value=[width])), "label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label])), "image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_object.tobytes()])) })) # レコード書込 writer.write(example.SerializeToString()) # 書き込み files = glob.glob("mnistVisualize" + os.sep + "*.jpg") CreateTensorflowReadFile( files , OUTPUT_TFRECORD_NAME ) |
(結果)
以下は、処理後の「mnistVisualize」フォルダをエクスプローラで確認しているものです。10000件ある画像データを含んだTFRecordファイルが作成されていることが分かります。
![]()
2.TFRecordファイルの中身を確認し、もう一度画像ファイルに戻してみる
2-1.作成したTFRecordファイルの中身を確認する
2-1-1.データ件数を確認する
それでは、TFRecordが正しく作成されているか、中身を確認をします。まずはデータ件数です。
|
1 2 |
cnt = len(list(tf.python_io.tf_record_iterator(OUTPUT_TFRECORD_NAME))) print("データ件数:{}".format(cnt)) |
(結果)
下図Aは、Pythonでの処理結果です。別途、PythonでMNISTのデータ件数を求めた図Bの結果と一致しているのが分かります。元データのデータ全てが、TFRecordファイルに作成されています。
![]()
[図A]
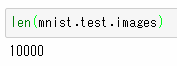 [図B]
[図B]
2-1-2.データの中身を見てみる
次にデータの中身自体を確認します。
|
1 2 |
example = next(tf.python_io.tf_record_iterator(OUTPUT_TFRECORD_NAME)) tf.train.Example.FromString(example) |
(結果)
以下は、上記PythonのコードをJupyter Notebookで実行した結果です。
定義したKey毎に、定義したデータ型と保存した値を保持しているのが分かります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
features { feature { key: "height" value { int64_list { value: 28 } } } feature { key: "image" value { bytes_list { value: "\000\000\ ~ 中略 ~ } } } feature { key: "label" value { int64_list { value: 9 } } } feature { key: "width" value { int64_list { value: 28 } } } } |
2-2.TFRecordファイルを画像に戻す
2-2-1.データを読み込み、もう一度画像にしてみる(1)
フォルダ「check_tfRecords」に、ファイル「tfrecords_X-Y.png」(X:0からの連番、Y:0~9の正解ラベル)を作成します。
画像データは、まずTFRecordファイル作成時に定義した通り、「bytes_list」として取得していますが、数値化にあたり、「dtype=np.uint8」で処理します。別のdtypeを指定すると、reshape後の形状が異なってきますので、注意して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
count = 0 for record in tf.python_io.tf_record_iterator(OUTPUT_TFRECORD_NAME): example = tf.train.Example() example.ParseFromString(record) # バイナリデータからの読み込み height = example.features.feature["height"].int64_list.value[0] width = example.features.feature["width"].int64_list.value[0] label = example.features.feature["label"].int64_list.value[0] image = example.features.feature["image"].bytes_list.value[0] image = np.fromstring(image, dtype=np.uint8) image = image.reshape([height, width]) img = Image.fromarray(image, "L") # グレースケール img.save(os.path.join("check_tfRecords", "tfrecords_{0}-{1}.jpg".format(str(count), label))) count += 1 |
(結果)
以下は、「check_tfRecords」フォルダに作成された画像をエクスプローラで表示したものです。画像を縮小表示していますが、画像中の数字とファイル名に付与したラベル(Y)が一致していることが分かります。

2-2-2.データを読み込み、もう一度画像にしてみる(2)
上記「データを読み込み、もう一度画像にしてみる(1)」では、TFRecordファイルから1件ずつ読み込んで、画像ファイルに変換していました。
別の実装方法で、TFRecordファイルを読み込んで、キューに入れて、キューを1件ずつ処理して画像に変換する方法もありますので、下に掲載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def read_and_decode(filename_queue): reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) # 次のレコードの key と value が返ってきます features = tf.parse_single_example( serialized_example, features={ "height": tf.FixedLenFeature([], tf.int64), "width": tf.FixedLenFeature([], tf.int64), "label": tf.FixedLenFeature([], tf.int64), "image": tf.FixedLenFeature([], tf.string), }) image_raw = tf.decode_raw(features["image"], tf.uint8) height = tf.cast(features["height"], tf.int32) width = tf.cast(features["width"], tf.int32) label = tf.cast(features["label"], tf.int32) image = tf.reshape(image_raw, tf.stack([height, width,])) return image, label |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
filename_queue = tf.train.string_input_producer([OUTPUT_TFRECORD_NAME]) # TFRecordファイルからキューを作成 images, labels = read_and_decode(filename_queue) # キューからデコードされた画像データとラベルを取得する処理を定義 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 初期化 try: coord = tf.train.Coordinator() # スレッドのコーディネーター threads = tf.train.start_queue_runners(coord=coord) # グラフで収集されたすべてのキューランナーを開始 for i in range(10000): image, label = sess.run([images, labels]) # 次のキューから画像データとラベルを取得 img = Image.fromarray(image, "L") # グレースケール img.save(os.path.join("check_tfRecords", "tfrecords_{0}-{1}.jpg".format(str(i), label))) # 画像を保存 finally: coord.request_stop() # すべてのスレッドが停止するように要求 coord.join(threads) # スレッドが終了するのを待つ |
今回は、TFRecordフォーマットのファイルを、単純に作成したり、読み込んだりしました。次回以降では、TFRecordを学習に用いる方法を取り扱いたいと思います。


執筆者プロフィール

- tdi デジタルイノベーション技術部
- 入社以来、C/S型の業務システム開発に従事してきました。ここ数年は、SalesforceやOutSystemsなどの製品や、スクラム開発手法に取り組み、現在のテーマは、DeepLearning/機械学習です。
この執筆者の最新記事
 Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて)
Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて) Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩
Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩 RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む!
RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む! AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする
AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする


