
はじめに
AIや機械学習ブームの中、最近巷でAutoML(Automated Machine Learning)というワードをよく目にするようになりました。
AutoMLとは、機械学習プロセスを自動化する技術であり、「機械学習の専門的な知識がなくても素早く、そして簡単に機械学習モデルを構築できる」というものです。このワード自体は、前々から言われてはいましたが、ここ最近はAutoMLのサービスも増えてきました。
機械学習のプロセスには、データ収集、データ前処理、モデルの選択、ハイパーパラメータのチューニング、モデルの評価など、いくつかの作業があるわけですが、AutoMLを利用すれば、このプロセスを自動化し、生産性の向上が期待できるため、煩雑な作業に時間がかかっていた機械学習のエンジニアからも注目されているのだと思います。
もちろん、専門的な知識がない人でも、ポチポチっとクリックしながら比較的高精度に結果の出力までできるので、どちらにとっても魅力的なサービスです。
AutoMLの特徴を下にまとめてみました。※サービスによっては異なることもあります。
- 特徴
- 機械学習エンジニアでなくても大丈夫!
- コストが比較的安くすむ
- 基本的にプログラミングが不要
- 少ないデータ数でも簡単に素早く試せる
- 手間のかかる作業の自動化
AutoMLの代表的なサービスだとGoogleのCloud AutoMLが有名ですが、他にもDataRobotやH2O(H2O.ai Documentation、H2O AutoML Tutorial)といったサービスもあります。
今回はいくつかあるサービスの中から、個人的に気になっているNanonetsを取り上げて実際に使ってみたいと思います。
Nanonetsとは
Nanonetsは、導入が容易で最小限のトレーニングデータと機械学習の知識で、機械学習モデルを簡単に構築できるサービスです。
以下、What is Nanonets?より一部引用
※Google翻訳しています
Nanonetsはディープラーニングプラットフォームであり、実際のアプリケーションでこれまで以上に簡単にディープラーニングを使用できる。
Webベースのプラットフォームの利便性とディープラーニングモデルを組み合わせて、ビジネス向けの画像認識およびオブジェクト分類アプリケーションを作成する。
NanonetsのAPIを使用して、ディープラーニングモデルを簡単に構築および統合できる。
また、巨大なデータセットでトレーニングされた事前トレーニング済みモデルを使用して、正確な結果を返すこともできる。Nanonetsは、ディープラーニングの最新の進歩を活用して、タスク間で転送可能なデータの豊富な表現を構築した。
入力をアップロードし、出力を生成し、AIのニーズに合わせて機能する非常に正確なディープラーニングモデルを取得するだけ。
Nanonetsは、大規模なデータセットなしでモデルをトレーニングできるため、革新的。
わずか100枚の画像を使用して、プラットフォームでモデルをトレーニングして、特徴を検出し、高精度で画像を分類できる。Nanonetsは4つの重要な方法であなたに利益をもたらす。
- 深層学習モデルの構築に必要なデータ量を削減する
- Nanonetsは、モデルのホスティングとトレーニング、
および実行時のインフラストラクチャを処理する- モデル間のインフラストラクチャを共有することにより、ディープラーニングモデルの実行コストを削減する
- 誰でも深層学習モデルを構築することが可能
Nanonetsのプラットフォームは、
農業、ソーシャルメディア、eコマース、健康など様々な分野に応用されている。その用途は、空撮から収穫量を検出することから、
ソーシャルメディア上の明示的なコンテンツを識別することまで多岐にわたる。
ここで押さえておきたいポイントとしては、
- APIを使用することで、ディープラーニングのモデルを誰でも簡単に構築、統合できる
- 巨大なデータセットでトレーニングされた事前トレーニング済みモデルを使用しており、
少ないデータセットでも精度の高い結果を返すことができる
ということです!
また、気になるNanonetsの料金体系ですが、Developer、Medium、Large、Enterpriseの4つのプランがあるようです。
Developerだと制限はありますが、無料で利用することも可能です。少し試す程度なら無料枠でもまず大丈夫だと思います。
無料の場合
|
Plan
|
Developer
|
|---|---|
| Operation | 1k |
| Monthly Cost | $0 |
| Response Time | Slow |
| Minimum Throughput Operations/Second |
0.01 |
| Retraining | On Demand |
※一部を抜粋
Nanonetsを使ってみる
では早速Nanonetsを使ってみましょう!
アカウント作成
まずは、アカウントの作成が必要です。サイトのトップページにある「GET STARTED」を押下します。
下部の「Sign Up」を押下します。
GoogleかEmailでのSign Upどちらかを選べますが、今回はGoogleアカウントがあるため、SIGNUP WITH GOOGLE」を押下します。(状況に応じて選択してください!)
無事に登録が終わると以下のダッシュボード画面に遷移します。これでアカウント作成は終わりです。
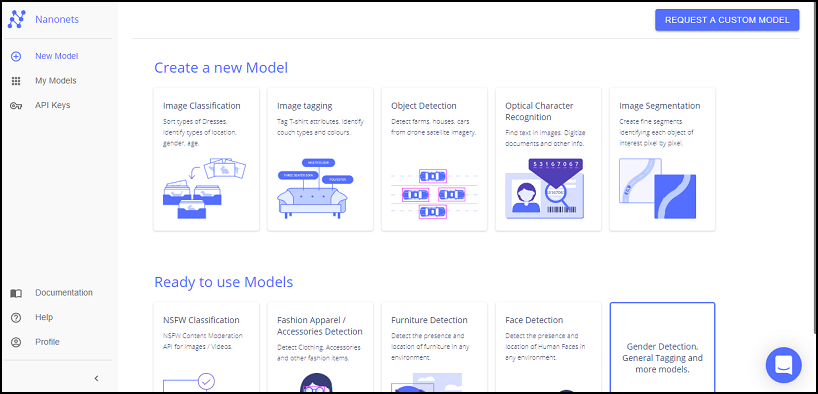
ダッシュボード画面では、大きく分けて Create a new Model と Ready to use Models から選べるようです。
Create a new Model では、オリジナルのモデルを作成でき、Ready to use Models では、既に学習済みのモデルを使えます。
Create a new Model:オリジナルモデル
- Image Classification
- 画像分類
- Image tagging
- 画像へのタグ付け
- Object Detection
- 物体検出
- Optical Character Recognition
- 光学文字認識
- Image Segmentation
- 画像を複数の部分もしくは領域に分割
Ready to use Models:学習済みモデル
- NSFW Classification
- 画像 / 動画用のNSFWコンテンツモデレーションAPI
- Fashion Apparel / Accessories Detection
- 衣類、アクセサリー、その他のファッションアイテムを検出
- Furniture Detection
- あらゆる環境で家具の存在と場所を検出
- Face Detection
- あらゆる環境で人間の顔の存在と位置を検出
- Gender Detection General Tagging and more models.
- X線分類
- 空港画像での歩行者検出
- 性別検出
- 動物の検出
- 衣類の分類
- 一般的なタグ付け
Nanonetsはチュートリアルも公開されているので、興味がある方はまずは以下のリンクからやってみてください。
今回は試しに、Create a new Model の Object Detection をやってみたいと思います。
Object Detectionをやってみよう
最初にダッシュボード画面から Create a new Model の 「Object Detection」を押下します。すると、以下の画面に遷移するので、「Start Building」を押下します。
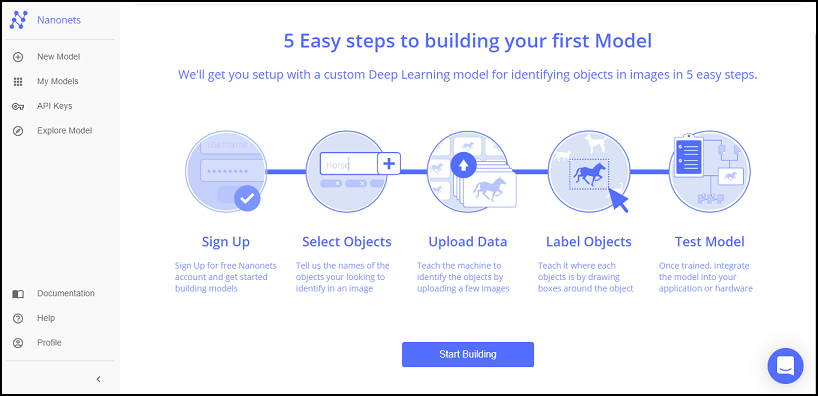
ラベル登録
物体検出したいものの名前(ラベル)を登録します。今回は寿司ネタのマグロとエビを検出させてみようと思うので、マグロとエビで登録してみます。
検出したいものの名前を入力後、「+」ボタンを押下すると追加されます。登録が終わったら、「CREATE MODEL」を押下します。
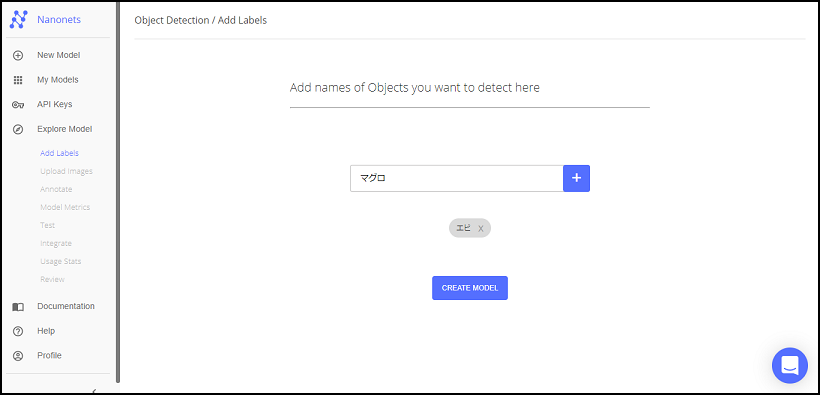
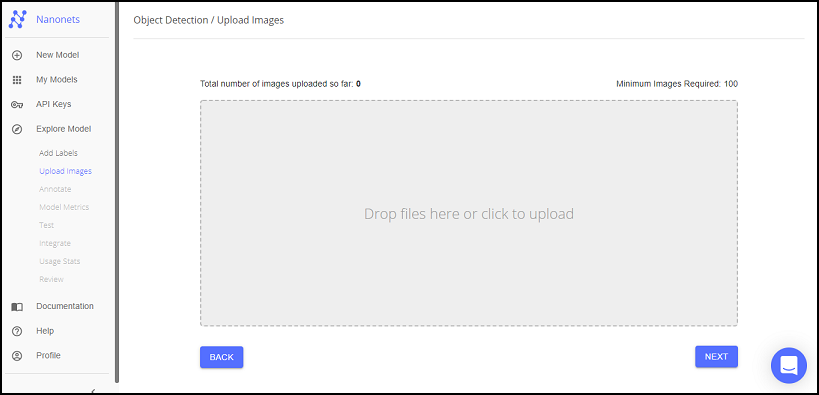
データ登録
次は、学習に使うデータをドラッグ&ドロップでアップロードします。
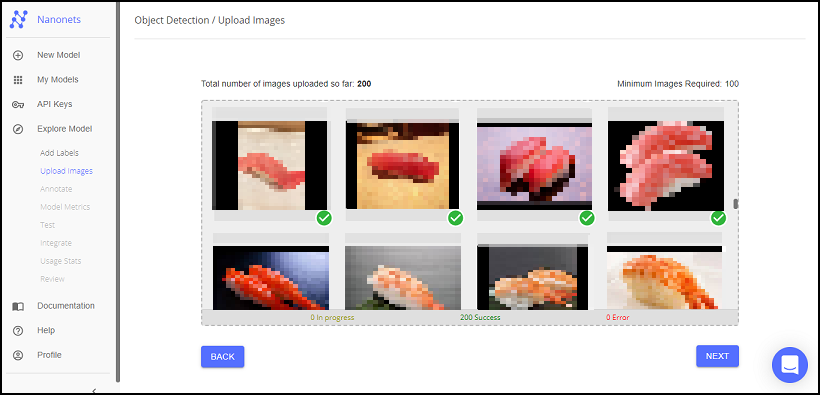
Object Detection をやる上で、最低限必要な画像数(Minimum Images Required)が決まっており、どうやら1ラベルあたり最低50枚は画像が必要なようです。今回は各ラベルごとに100枚ずつアップロードしてみます。(お手元のデータ数に応じて決めてください)
アップロードが完了したら、「NEXT」を押下します。
アノテーション
続いて、アノテーションを行っていきます。
アノテーション画面では、プランをアップグレードすることでアノテーションサービスを使うこともできますが、今回は無料枠でやるため、全て手動でアノテーションを行います。既にアノテーションデータ(xml)をお持ちの方はそちらも使えるようです。
ここでは「ANNOTATE MANUALLY」を押下します。
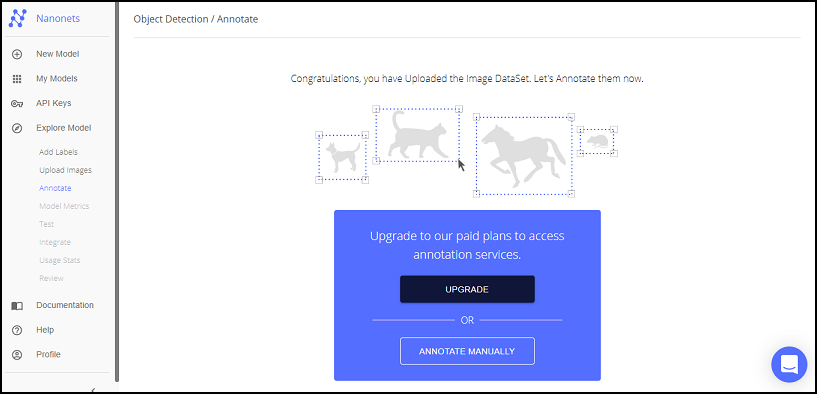
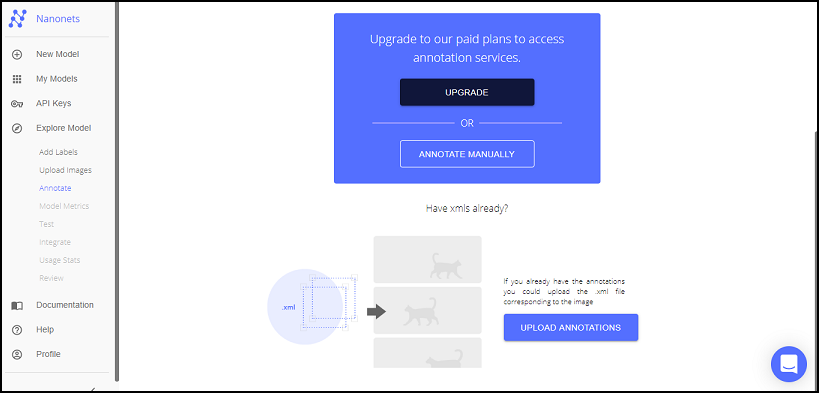
アノテーションはマウスをドラッグしながら対象物を囲むように行います。
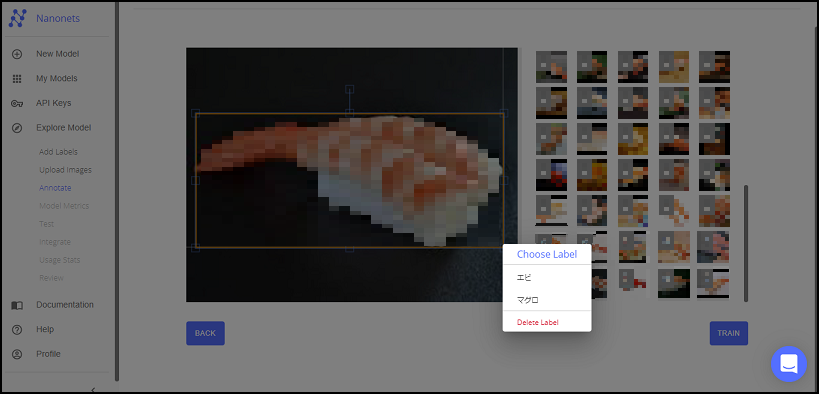
マウスを離すとラベルが表示されるので、該当するラベルを選択します。間違えてつけてしまった場合は、「Delete Label」から削除し、再度ラベルを選択できます。
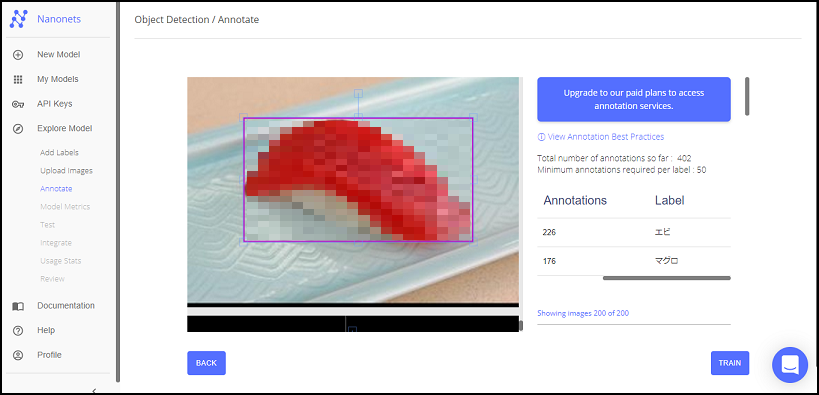
※アノテーションのベストプラクティスも用意されているので、気になる方は見てみてください!
全てのアノテーションが完了したら、右下の「TRAIN」を押下します。
学習
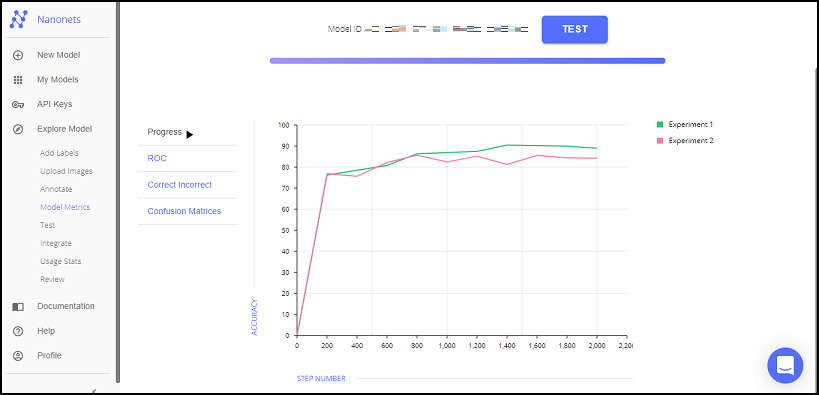
画面が遷移すると学習がスタートします。ここでは学習完了までのおおよその時間と現在の学習状況をグラフで見ることができます。
学習には時間がかかりますが、親切なことに学習が終わったタイミングでメールが飛んでくるみたいです。これは嬉しい!今回は数十分くらいで学習が完了しました。
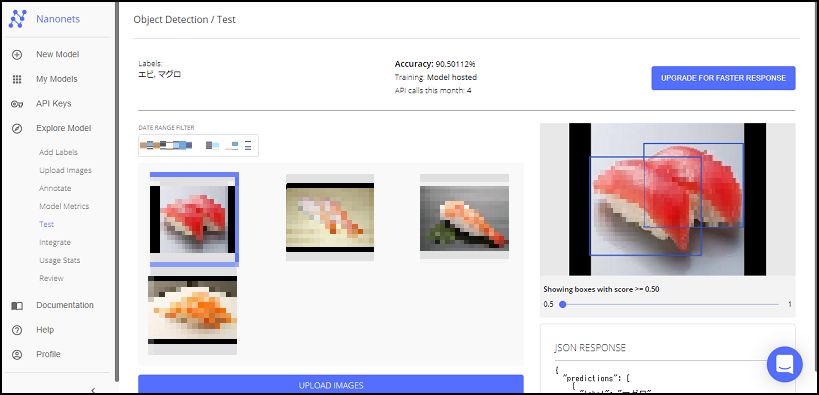
学習が完了したら、画面上部の「TEST」を押下し、推論をしてみましょう!
推論
「UPLOAD IMAGES」を押下し、認識させたい画像をアップロードします。
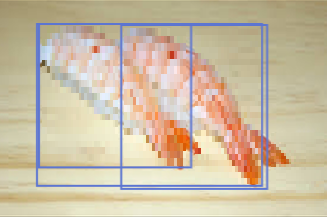
少し待つと結果が画面の右側に表示されます。結果はラベル、座標、スコアがJSONで返ってきます。ちゃんと認識されていますね!
|
ラベル
|
認識結果
|
JSON RESPONSE
|
||
|---|---|---|---|---|
| マグロ |
|
|
||
| エビ |
|
|
||
| エビ |
|
|


スニペット
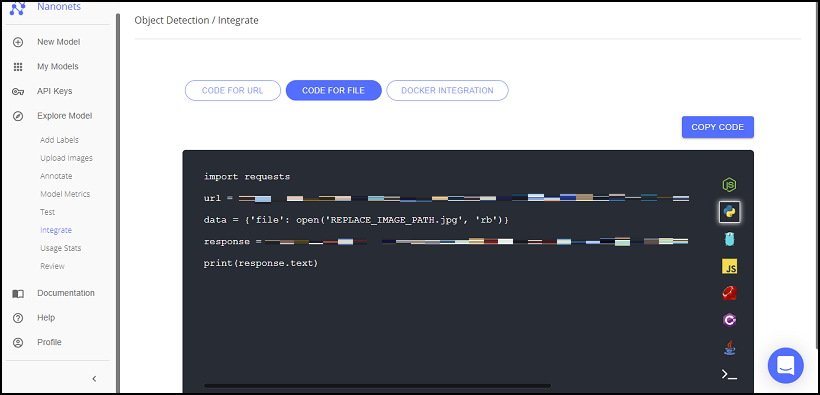
画面左部の「Integrate」を押下すると推論用のコードも提供されており、言語も多様にサポートされているので、すごく便利です!
おわりに
いかがでしたでしょうか?
Nanonetsは個人的に気になっていたサービスでしたが、無料でここまでできるのか!と驚きがありました。
機械学習のエンジニアにもかなりメリットはありますが、「AIをやってみたいけど、今から数学とかの勉強をし直すのは面倒だし」という人でも簡単に使えるAutoMLというサービスは、今後も増えてくる気がしています。
今回は紹介しませんでしたが、他にも機能はいくつかあるので、ぜひみなさんも使ってみてはいかがでしょうか。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 配属後、ロボコン担当として、ETロボコン2017東京地区大会優勝・ITAロボコン2017優勝に貢献。現在は、AIチームの一員として、機械学習、ディープラーニングなどに挑戦しています。






