
先日、某無料オンライン大学講座にて、「白川フォント」というものが無料で公開されていることを知りました。
これは、甲骨・金文などの古代文字のためのもので、『現代の漢字を入力するのと同じように、簡単に古代文字の入力が出来ます。』(引用:白川フォント)とのことです。つまり、外字ではなく、対応する現代漢字と同じ文字コードが使われているとのことでした。
また、ちょうどOCRについて調べていたこともあり、このフォントで書かれた文字列を読み取ってみたいと思いました。フォントで提供されている文字が外字になっていないということは、甲骨文字フォントの文字認識がうまくいけば、甲骨文字を現在の文字に変換できるはずです。
では、OCRの基本的な処理を、オープンソースの「Tesseract」を用いて、実際にやってみます!
< 実施環境 >
- 実行マシン: Windows 10 Pro 64bit
- 利用した主要なソフトウェア/ライブラリ: Tesseract、PyOCR、jTessBoxEditor
- 言語: python 3.6(Anaconda)
< 進め方 >
- データ準備
- 実行環境の準備
- 認識結果の確認(①:デフォルトの状態での認識結果)
-
Tesseractの学習
- 認識結果の確認(②:学習済みの状態での認識結果)
目次
データ準備
最初に、OCRに認識させたい画像の準備を行います。
(以下で、利用するフォントをインストールしていますが、これは画像の作成だけでなく、後述の学習でも必要となります。)
「白川フォント」のインストール
- まず、下記サイトに遷移し、フォントをダウンロードします。
(今回は「白川甲骨文字」(「ShirakawaKoukotsu_v1.03.ttf」)を利用します。)
http://www.dl.is.ritsumei.ac.jp/Shirakawa/search/?#downloads - フォントをインストールします。
- ダウンロードできたら、そのファイルをダブルクリックして、
開いたウィンドウ上部にある「インストール」をクリックします。
- ダウンロードできたら、そのファイルをダブルクリックして、
「白川フォント」で書かれた文字を含む画像を準備
- ペイントを起動します。
- フォントに「白川甲骨」を指定して、下図のような文字を入力します。
(「山川洋子さん おはようございます」と入力しています。)
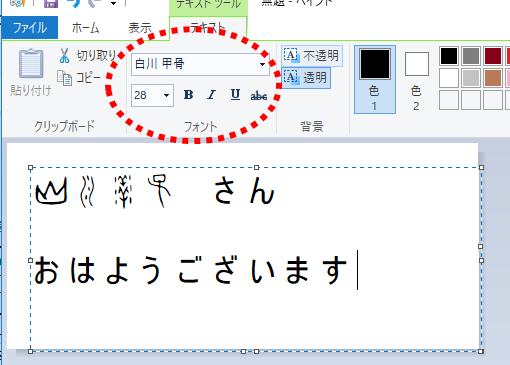
- 上記をpngとして保存します。

実行環境の準備
OCRの実行に必要なTesseractとそれをPythonで利用する為のPyOCRを利用する環境を準備します。
Tesseractのインストール
TesseractはオープンソースのOCRです。
元々は英語を処理する為に作られたようですが、ドイツのマンハイム大学が公開しているWindows環境でのインストーラには、トレーニングツール以外に日本語のトレーニングデータも含まれていますので、今回はこれを利用します。
- インストーラ(「tesseract-ocr-setup-3.05.01.exe」)をダウンロードします。
https://github.com/UB-Mannheim/tesseract/wiki
- インストーラを実行し、ウィザードに従い、インストールを行います。
- 注意点:
- 「Additional language data (download)」から「Japanese」を選択します。
- このインストールフォルダを後で環境変数に追加するので、覚えて下さい。
- 「Additional language data (download)」から「Japanese」を選択します。
- 注意点:
- 環境変数「Path」に上記のパスを追加します。
PyOCRのインストール
PyOCRは他のOCRツールを利用する為のPython用ラッパーです。
今回は、このPyOCRを通して、PythonでTesseractを利用することになります。
-
下記コマンドにてインストールを行います。
1pip install pyocr
認識結果の確認(①:デフォルトの状態での認識結果)
OCRの実行環境が整ったので、デフォルトの状態のままで、認識結果を確認してみます。
- 認識結果
日本語は認識できていますが、甲骨文字をうまく認識できていませんね。- 使用言語:インストール時に追加で導入した日本語トレーニングデータ
※Tessaractが認識したワード(=図中の赤い枠)と
その認識結果(=図の上部に出力している文字列)

- 使用言語:インストール時に追加で導入した日本語トレーニングデータ
-
ソースコード
※jupyter notebook で実行したコード1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556# coding: utf-8# In[1]:from PIL import Imageimport pyocrimport cv2import IPython.display as display# In[2]:# OCRツールを指定 (「Tesseract」が[0]に収められていた)tools = pyocr.get_available_tools()tool = tools[0]# そのOCRツールで使用できる言語を確認langs = tool.get_available_languages()# 言語に日本語を指定 (日本語トレーニングデータ「jpn」が、[1]に収められていた)lang_setting = langs[1]# In[3]:# 関数:OpenCVの画像を、jupyter notebook にインライン表示するdef display_cv_image(image, format='.png'):decoded_bytes = cv2.imencode(format, image)[1].tobytes()display.display(display.Image(data=decoded_bytes))# In[4]:# 画像を認識sample_image_file = "test_image.png"with Image.open(sample_image_file) as im1:# ビルダーの設定builder = pyocr.builders.LineBoxBuilder(tesseract_layout=6)# テキスト抽出res = tool.image_to_string(im1,lang=lang_setting, # 言語を指定builder=builder)# 認識範囲を描画out = cv2.imread(sample_image_file)for d in res:print(d.content)print(d.position)cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2)display_cv_image(out)
Tesseractの学習
デフォルトのままでは、うまく認識できなかったので、学習を行います。
まずは、学習に必要なツール「jTessBoxEditor」を準備します。
jTessBoxEditorのインストール
Tesseract用の学習データを作成する為のツール「jTessBoxEditor」をインストールします。
インストール方法
- 下記よりzipファイル「jTessBoxEditor-2.0.zip」をダウンロードします。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ - 上記zipファイルを適当なフォルダに解凍します。
起動方法
-
jTessBoxEditor.jar をダブルクリック or 下記コマンド で起動します。
1java -Xms128m -Xmx1024m -jar jTessBoxEditor.jar※実行には、JRE8以上が必要です。
学習データの作成
iTessBoxEditorを用いて、学習データを作成します。
- 「tif」ファイル、「box」ファイル、「font_properties」ファイルを作成します。
- iTessBoxEditorを起動し、「TIFF/Box Generator 」タブを開きます。
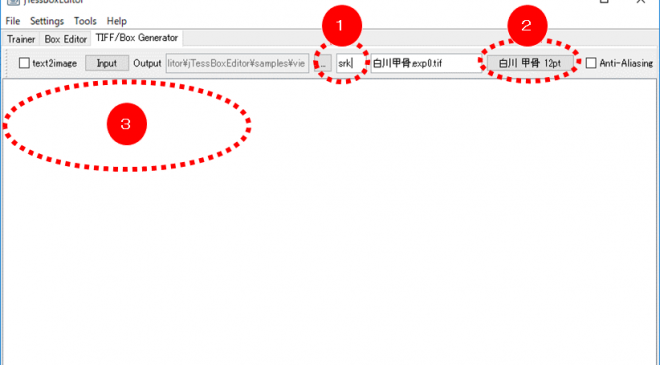
- 上図(1)に学習済み言語を表す英字を入力します。(英字は自分で決めます。今回は「srk」としておきます)
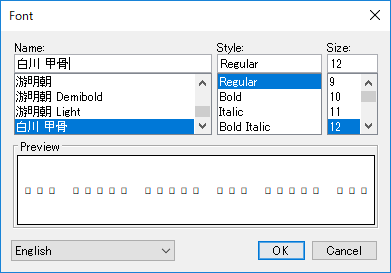
- 上図(2)をクリックすると、下図のウィンドウが表示されるので、「白川フォント」を指定します。
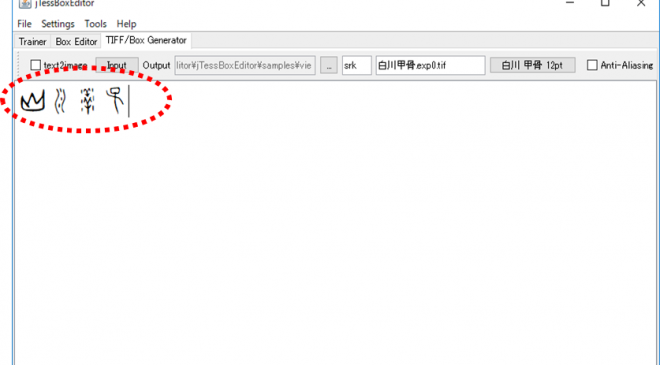
- 上図(3)に学習させたい文字を入力します。
下の例では、「山川洋子」と入力しています。
- 「Generate」ボタンをクリックし、処理を実行します。
※もし下図のように「Generate」ボタンが画面サイズに収まらず、表示できていない場合は、
図の赤丸で囲んだ箇所をiTessBoxEditorのウィンドウ外にドラッグして、ウィンドウとの結合を解除すると表示されます。

↓
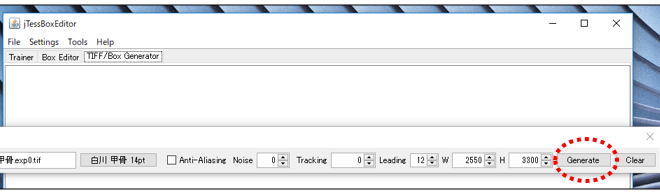
※実行時にエラー「java.lnag.NullPointerException」が表示されましたが、フォントサイズを大きくしたり、iTessBoxEditorを再起動すると、エラーが解消されました。
- 正常に処理が終わると次のようなファイルが生成されます。
※出力先は、「Output」欄にあるフォルダとなります。- srk.白川甲骨.exp0.box
- srk.白川甲骨.exp0.tif
- srk.白川甲骨.font_properties
- iTessBoxEditorを起動し、「TIFF/Box Generator 」タブを開きます。
-
「word_list」ファイル、「frequent_word_list」ファイルを作成します。
-
中身は空のままでよく、ファイル名を次のようにします。
(※「srk」は前手順で指定した任意の文字列です)- srk.words_list
- srk.frequent_words_list
-
- 上記で作った5つのファイルを任意のフォルダを作り、そこに保管します。
学習の実行
学習データができあがったので、学習を行います。
- iTessBoxEditorを起動し、「Trainer 」タブを開きます。
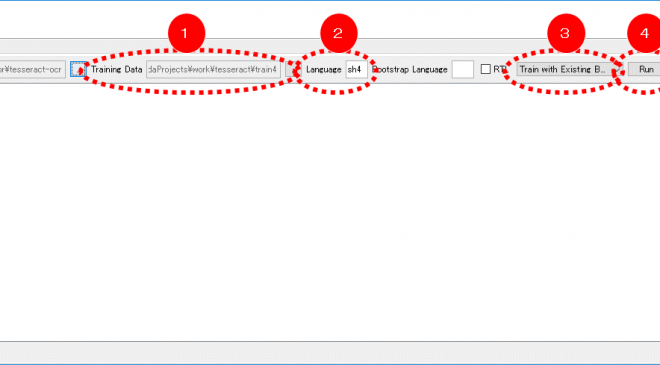
- 次のように入力します。
- Traininig Data(1):上記で生成したファイル「srk.白川甲骨.exp0.box」を選択します。
- Language(2):「skr」と入力します。
- Training Mode(3):「Train with Existing Box」を選択します。
- 入力が完了したら、「Run(4)」ボタンをクリックし、処理を実行します。
- 『** Moving generated traineddata file to tessdata folder ** (改行) ** Training Completed **』と表示されたら、完了です。
- 上記入力で「Traininig Data」に指定したファイルがあるフォルダに、「tessdata」フォルダが作成され、
学習済みデータ「srk.traineddata」が生成されています。
- 次のように入力します。
- 学習済みデータをTesseractの環境にコピーします。
- 例)C:\Users\(ユーザ名)\AppData\Local\Tesseract-OCR\tessdata
認識結果の確認(②:学習済みの状態での認識結果)
学習が終わり、その結果を適用できるようになりましたので、認識結果がどうなるのか確認してみましょう。
-
認識結果
今回は、学習データを何種類か作成してみました。それぞれの結果は以下の通りです。※1 「学習データ」について:
前述のツール「iTessBoxEditor」で「box」ファイル等を作成した時に入力した文字列のことを指します。
※2 フォントに含まれる文字の出力について:
詳しい処理内容は省略しますが、Python用ライブラリである「fontTools」を用いて、フォントデータをXMLに変換して、抜き出しました。
※3 図中の赤い枠は、Tesseractが認識した領域です。図の上部に出力している文字列は、その認識結果です。使用言語学習データ ※1認識結果認識結果(画像)※31 日本語
+
右記学習データ文字列「山川洋子」 日本語しか認識できていない 
2 日本語
+
右記学習データ白川甲骨文字フォントに収録されているほぼ全てである約600個の文字を羅列したもの
(1行に書き出したもの) ※2「山川」は認識できた! 
3 日本語
+
右記学習データ白川甲骨文字フォントに収録されているほぼ全てである約600個の文字を羅列したもの
(文字毎に改行したもの) ※2「山川」は認識できた! 
4 日本語
+
右記学習データ白川甲骨文字フォントに収録されているほぼ全てである約600個の文字を羅列したもの
(文字毎に改行し、それを5回繰り返したもの) ※2すべての認識できた! 
-
ソースコード
今回は何種類かの学習データで結果を確認しました。学習データを用意すると、「tool.get_available_languages()」で取得される結果がその分だけ増加します。その中から、利用したいものを”+”で結合した文字列を言語として設定することで、適用されます。※jupyter notebook での実行用コード
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657# coding: utf-8# In[1]:from PIL import Imageimport pyocrimport cv2import IPython.display as display# In[2]:# OCRツールを指定 (「Tesseract」が[0]に収められていた)tools = pyocr.get_available_tools()tool = tools[0]# そのOCRツールで使用できる言語を確認langs = tool.get_available_languages()# 言語に日本語と今回の学習済みデータを指定lang_setting = langs[1]+"+"+langs[5]# In[3]:# 関数:OpenCVの画像を、jupyter notebook にインライン表示するdef display_cv_image(image, format='.png'):decoded_bytes = cv2.imencode(format, image)[1].tobytes()display.display(display.Image(data=decoded_bytes))# In[4]:print(lang_setting)# 画像を認識sample_image_file = "test_image.png"with Image.open(sample_image_file) as im1:# ビルダーの設定builder = pyocr.builders.LineBoxBuilder(tesseract_layout=6)# テキスト抽出res = tool.image_to_string(im1,lang=lang_setting, # 言語を指定builder=builder)# 認識範囲を描画out = cv2.imread(sample_image_file)for d in res:print(d.content)print(d.position)cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2) # 赤い枠を描画display_cv_image(out)
まとめ
気付いている方もいると思いますが、実は今回、認識しやすいように、画像中の1行目と2行目の間や、甲骨文字とひらがなの間にスペースを作っています。認識精度の向上には学習の前に、画像自体のデータ前処理や、実行時のパラメータ設定での確認も必要になります。それらに関する内容は、次のサイトに公開されていますので、興味のある方は参考にしてみて下さい。
また、今回利用したTesseractのバージョンは、3.05ですが、現時点でベータ版であるバージョン4では「LSTMエンジン」を利用しているということなので、どのような結果になるか楽しみです。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 入社以来、C/S型の業務システム開発に従事してきました。ここ数年は、SalesforceやOutSystemsなどの製品や、スクラム開発手法に取り組み、現在のテーマは、DeepLearning/機械学習です。
この執筆者の最新記事
 Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて)
Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて) Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩
Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩 RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む!
RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む! AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする
AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする


