目次
はじめに
この記事では、オープンソースの大規模言語モデルである Llama 3.1 と、Streamlit を使って AI チャットアプリを作る方法を紹介します。
対象読者は、OpenAI 等の API 利用ではなく、自分で大規模言語モデルをホスティングしたい、という方を想定しております。大規模言語モデルは Llama 3.1 を取り上げていますが、他のモデルでも実施可能です。
ホスティングの環境はクラウド、オンプレミスどちらでも可能です。この記事では AWS EC2 の GPU インスタンスを利用します。
Llama 3.1 とは?
Llama 3.1 は、 Meta 社が開発したオープンソースの大規模言語モデルです。
8B(= 8 Billion = 80億), 70B, 405B という、3つのパラメータサイズのモデルが提供されています。サイズが大きいほど性能がよくなりますが、動かすのに必要な GPU のスペックも高くなります。
今回は 8B モデルの meta-llama/Meta-Llama-3.1-8B-Instruct を利用します。
AI チャットアプリの構成
今回作る AI チャットアプリの構成は次の図のとおりです。
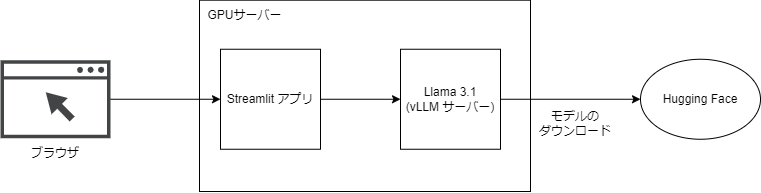
Streamlit のアプリから Llama 3.1 の推論サーバーにリクエストを投げて結果を表示する、という流れです。Llama 3.1 のモデルは Hugging Face からダウンロードされます。
Streamlit は Python のみで Web アプリを開発できるフレームワークです。こちらを使ってチャットアプリを作ります。
vLLM は Python で高速に大規模言語モデルを動かすライブラリです。こちらで Llama 3.1 の推論サーバーを立てます。
Hugging Face は、機械学習のモデルやデータセット等を提供するプラットフォームです。こちらから Llama 3.1 のモデル(meta-llama/Meta-Llama-3.1-8B-Instruct) がダウンロードされます。
GPU サーバーの準備
モデルを動かすためのサーバーを準備していきます。
今回のモデル(meta-llama/Meta-Llama-3.1-8B-Instruct)だと GPU メモリが 16GB ほど必要となります。必要な GPU メモリは、 Hugging Face のモデルのページから「Files and versions」を開いて、パラメータファイル(.safetensors)のサイズを合算して見積もれます。
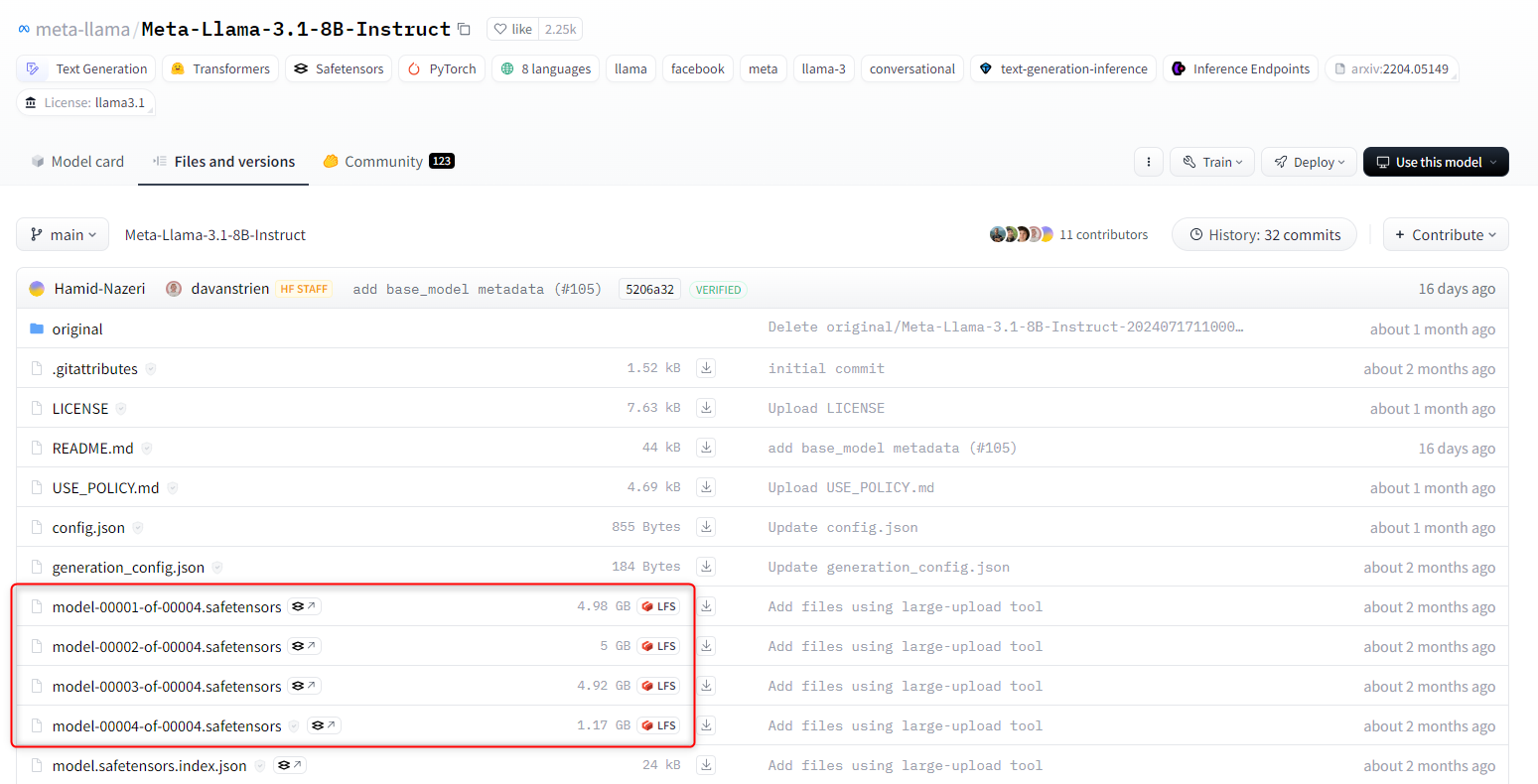
今回は例として AWS EC2 インスタンスの g5.xlarge (GPUメモリ: 24GB) を利用します。g5.xlarge の料金は1時間当たり $1.459 となります(東京リージョン 2024/09/12 時点)。
AWS マネジメントコンソールを開き、下記の設定でインスタンスを起動します。
AMI: Deep Learning Base OSS Nvidia Driver AMI (Amazon Linux 2)
インスタンスタイプ: g5.xlarge
キーペア: 新しく作成
ネットワーク設定: パブリックサブネットに配置して、パブリックIPの自動割り当てを有効化
セキュリティグループ: インバウンドルールで ssh のみ許可、アウトバウンドルールはすべて許可
ストレージ: 100 GB ほど (AMIとモデルのサイズを合わせて 80 ~ 90 GB となるため、余裕をもって設定してください)
キーペアはダウンロードしておきます。
インスタンス起動後、ローカルから ssh で接続できれば OK です。
|
1 |
$ ssh -i {キーペアのファイルパス} ec2-user@{インスタンスのパブリックIPアドレス} |
Python 実行環境の準備
Python の実行環境として uv を使います。
uv は Python のパッケージとプロジェクトを管理するツールです。
ssh で接続したインスタンス上で、次のコマンドで uv をインストールします。
|
1 |
$ curl -LsSf https://astral.sh/uv/install.sh | sh |
一度ターミナルを閉じて、再度インスタンスに ssh すると、uv コマンドが使えるようになります。
|
1 2 |
$ uv --version uv 0.4.5 |
uv でチャットアプリ用のプロジェクトを作ります。
|
1 2 3 4 |
$ uv init llama-3-1-chat-app --python 3.12 # --python オプションで Python のバージョンを指定できる(今回は 3.12) $ cd llama-3-1-chat-app/ |
これで Python のプログラムを動かす準備ができました。
Hugging Face の設定
Llama 3.1 を使うにあたり、Hugging Face でモデルの使用許諾を得る必要があります。
Hugging Face にログインしてモデルのページから使用許諾を得てください。承認まで数分かかります。
また、Hugging Face の設定画面からアクセストークンを作成します。インスタンス上の ~/.bashrc に環境変数 HF_TOKEN を追記します。
|
1 2 3 4 |
$ vim ~/.bashrc # 下記を追記する export HF_TOKEN=アクセストークン $ source ~/.bashrc |
環境変数 HF_TOKEN を設定することで、後述する vLLM による推論サーバーの初回起動時に Hugging Face からモデルがダウンロードされます。
vLLM で推論サーバー起動
vLLM で Llama 3.1 を動かしていきます。
インスタンス上で、uv にて vLLM をインストールします。
|
1 2 |
$ cd llama-3-1-chat-app/ (llama-3-1-chat-app)$ uv add vllm |
vLLM で OpenAI API 準拠のサーバーを起動します。デフォルトではポート8000でサーバーが起動します。自動起動したい場合は systemd でサービス化するとよいでしょう。
初回起動時に Hugging Face からモデルがダウンロードされます。
|
1 |
(llama-3-1-chat-app)$ uv run vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct --max-model-len 16384 |
別セッションを開き、サーバーにリクエストを投げます。
|
1 2 3 4 5 6 7 8 9 |
$ curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Meta-Llama-3.1-8B-Instruct", "messages": [ {"role": "system", "content": "日本語で回答してください。"}, {"role": "user", "content": "カレーの作り方を教えてください。"} ] }' |
レスポンスが返ってくることを確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "id": "chat-123456789", "object": "chat.completion", "created": 1725508756, "model": "meta-llama/Meta-Llama-3.1-8B-Instruct", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "カレーの作り方を紹介します。\n\n** 材料**\n\n* 1 kgの肉(牛、豚、鶏など)\n* 1 匹のトマト(またはト マト缶)\n* 1 匹のナス\n* 2 匹のパプリカ\n* 1 匹のタマリンド\n* 1 匹のココナッツミルク\n* 1 匹のカレー粉(インド風)\n* 1 匹のサフラン\n* 1 匹のコリアンダー\n* 塩と糖\n* 1 匹のオリーブオイル\n\n**作り方**\n\n1. **肉を準備する**: 肉を細かく 切って、混ぜる。\n2. **トマトを準備する**: トマトを細かく切って、混ぜる。\n3. **ナスとパプリカを準備する**: ナスとパプリカを細かく切って、混ぜる。\n4. **タマリンドを準備する**: タマリンドを水に浸けて、浸出させて、混ぜる。\n5. **カレー粉を準備する**: カレー粉を細かく切って、混ぜる。\n6. **ココナッツミルクを準備する**: ココナッツミルクを混ぜる。\n7. **カレーを作る**: オリーブオイルを熱して、肉を炒める。次に、トマト 、ナス、パプリカ、タマリンド、カレー粉、ココナッツミルクを加え る。さらに、サフラン、コリアンダー、塩、糖を加える。\n8. **カレーを混ぜる**: カレーを20分間、低火で混ぜる。\n9. **カレーを完成させる**: カレーが濃厚になるまで、混ぜる。\n\n**完成**\n\nカレーは完成です。カレーを完成させた後、熱いカレーを食べるか、冷蔵庫で冷やすことができます。\n\n**ヒント**\n\n* カレー粉は、インド風のカレーを作る際に重要な材料です。\n* タマリンドは、カレーの風味を強調するために使用します。\n* ココナッツミルクは、カレーの風味を濃厚にするために使用します。\n* カレー粉を細かく切って、混ぜることが重要です。\n\nこのカレーの作り方で、カレーを作ることができます。カレー粉、タマリンド、ココナッツミルクを使用することで、カレーの風味を濃厚にすることができます。", "tool_calls": [] }, "logprobs": null, "finish_reason": "stop", "stop_reason": null } ], "usage": { "prompt_tokens": 53, "total_tokens": 650, "completion_tokens": 597 }, "prompt_logprobs": null } |
Streamlit で AI チャットアプリ作成
Streamlit で AI チャットアプリを作成していきます。
インスタンス上で、uv にてアプリに必要なパッケージをインストールします。
|
1 |
(llama-3-1-chat-app)$ uv add openai streamlit |
アプリのソースコードを書きます。
|
1 |
(llama-3-1-chat-app)$ vim app.py |
次のソースコードをコピペして保存してください。
ソースコード中の os.environ[“OPENAI_API_KEY”] の値は dummy のまま書き換えなくて大丈夫です。vLLM のサーバーで API キーを設定していないため値はなんでもいいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from openai import OpenAI import streamlit as st os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1" os.environ["OPENAI_API_KEY"] = "dummy" model = "meta-llama/Meta-Llama-3.1-8B-Instruct" st.title(f"{model} とチャットするアプリ") st.header("※ 会話をリセットする際はブラウザをリロードしてください") client = OpenAI() if "openai_model" not in st.session_state: st.session_state["openai_model"] = model if "messages" not in st.session_state: st.session_state.messages = [ {"role": "system", "content": "あなたは日本語で回答するアシスタントです。"} ] for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"]) if prompt := st.chat_input("質問を入力する"): st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) with st.chat_message("assistant"): stream = client.chat.completions.create( model=st.session_state["openai_model"], messages=[ {"role": m["role"], "content": m["content"]} for m in st.session_state.messages ], stream=True, ) response = st.write_stream(stream) st.session_state.messages.append({"role": "assistant", "content": response}) |
アプリを起動します。デフォルトではポート8501で Streamlit のサーバーが起動します。こちらも自動起動したい場合は systemd でサービス化するとよいでしょう。
|
1 |
(llama-3-1-chat-app)$ uv run streamlit run app.py |
ローカルからSSHポートフォワードします。
|
1 |
$ ssh -i {キーペアのファイルパス} -L 8501:localhost:8501 ec2-user@{インスタンスのパブリックIPアドレス} |
ブラウザで localhost:8501 にアクセスします。
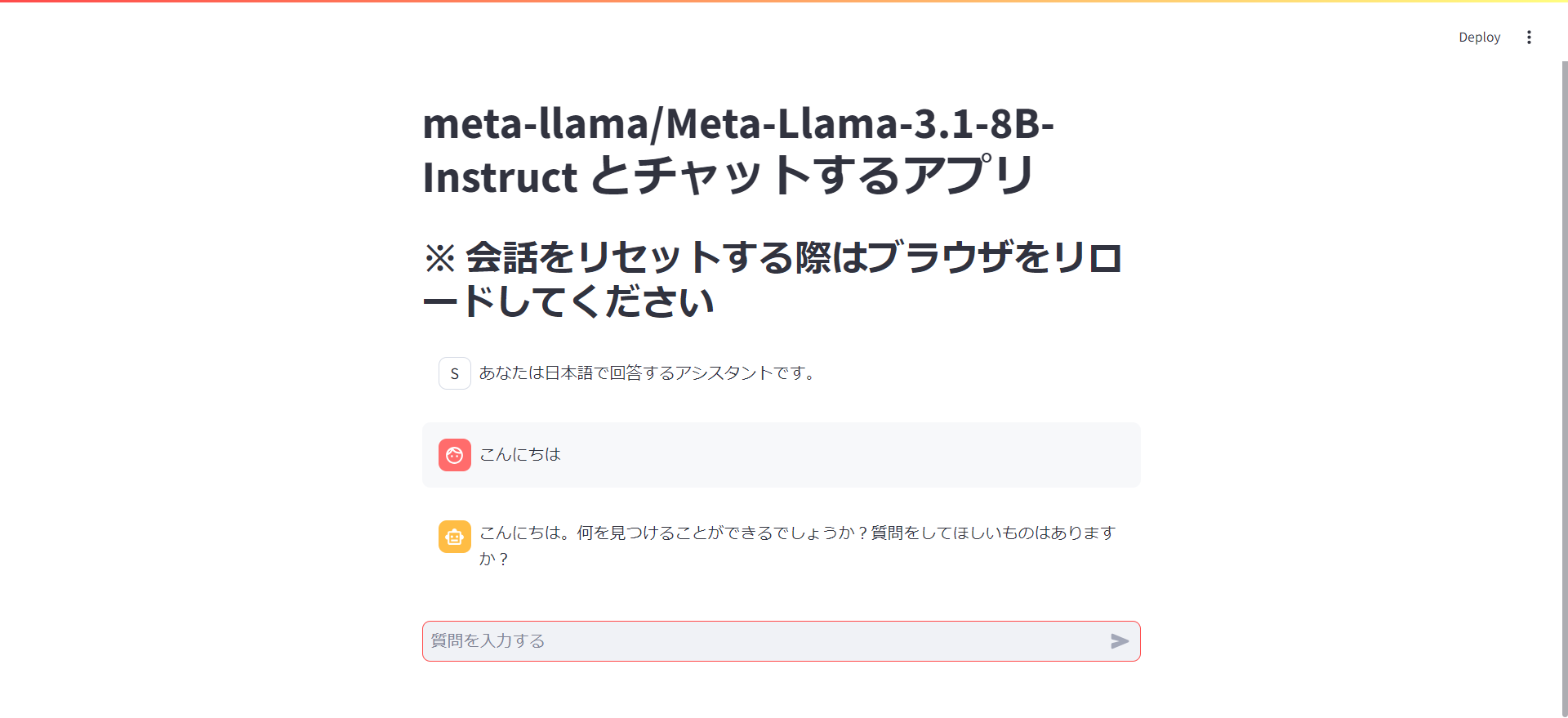
質問を入力して回答が返ってきたら OK です。おつかれさまでした!
おわりに
Llama 3.1 と、Streamlit を使って AI チャットアプリを作る方法を紹介しました。
クラウドやオンプレミス環境で大規模言語モデルをホスティングする際のとっかかりとして、参考になれば幸いです。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- AWS上で使えるツールの開発やフロントエンドの調査、生成系AIの調査等を行っています。最近は AWS の CDK やサーバーレスに興味があります。