
目次
はじめに
前回、下記記事で、私がAIチームに配属されてからの学習ステップをご紹介しました。

この記事ではそこで学んだ内容を活かして、画像判別器の実装を行っていきたいと思います。画像判別の分野では一般的な手順だとは思いますが、画像判別器の実装から精度確認まで各ステップごとに紹介していきます。
1.判別テーマ決め
今回の画像判別で扱う判別対象となる画像は、寿司ネタにしました。
サケ、マグロ、サバ、イクラ、ウニ、イカ、ハマチ、タイ、タコ、エビ
の計10種類の判別に挑戦してみます!
2.トレーニングおよびテストデータとなる画像の収集
画像判別の分野では、トレーニング時に使用するデータ枚数は一般的にカテゴリーごとに数千枚くらいはあったほうが良いと言われますが、この画像を集めるところが一番時間もかかりますし、非常に大変です。たくさん画像を集めるのが困難な場合でも、次のステップでご紹介する手法を用いれば画像枚数を増やすことができます。今回はネットでの画像検索や実際に寿司を食べに行き、各ネタごとになんとか150枚程度画像を収集しました。
【参考】今回は使用しませんでしたが、画像収集に用いられる方法にはWebスクレイピング(扱いには要注意)やFlickrなどのサイトのAPIを使う方法があります。これだと簡単にたくさん収集することができます。
※Webスクレイピングをする場合、Webページ上に書かれている内容をデータに変換しても問題ないか、対象先のサイトにWebブラウザーからではなくプログラムからアクセスしても良いのかなど、確認すべき点がいくつかあります。
それでは、収集した画像を見てみましょう。

寿司がお皿の上に乗っているものやそうでないものなど様々な画像があることが分かります。寿司ネタは形状の違いがあまりないですが、果たしてうまく判別できるのでしょうか。
3.画像の前処理(データの水増し)
画像の収集が終わりましたが、ただでさえあまり集められていない各画像を、トレーニングデータとテストデータに分けてしまうとさらに枚数が少なくなってしまいます。そこで学習前の前処理として、画像の水増しを意味するData Augmentationを行っていきます。元画像に対して、左右反転と回転(15度、30度、45度、60度、75度、285度、300度、315度、330度)の処理を適用しました。ここでの前処理には画像操作ライブラリのPILを使っています。
|
1 2 3 4 5 6 7 8 9 10 |
from PIL import Image img = Image.open(INPUT_DIR) # 画像読み込み # 例1 img_flr = img.transpose(Image.FLIP_LEFT_RIGHT) # 左右反転 img_flr.save(OUTPUT_DIR) # 画像保存 # 例2 img_rotate = img.rotate(15) # 15度回転 img_rotate.save(OUTPUT_DIR) # 画像保存 # 以下省略 |
前処理結果は以下のようになり、画像枚数が10倍に増えました!

水増ししたことにより画像の枚数が増えたので、トレーニングデータを10500枚、精度確認のためのテストデータを4500枚としてみようと思います。また、学習時の検証データはトレーニングデータのうち3割を使うことにします。
4.各種ライブラリのインポートとデータ整形
ここでは画像判別器の実装に向けた各種ライブラリのインポートと、上記で準備しておいた画像を読み込み、学習時に扱いやすいように整形を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import os, cv2, random import numpy as np import matplotlib.pyplot as plt from matplotlib import ticker from PIL import Image %matplotlib inline from keras.models import Sequential from keras.layers import Input, Flatten, Conv2D, MaxPooling2D, Dense, Activation from keras.callbacks import Callback, EarlyStopping from keras.utils import np_utils |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
TRAIN_DIR = './sushi/train/' # トレーニングデータが格納してあるディレクトリのパス TEST_DIR = './sushi/test/' # テストデータが格納してあるディレクトリのパス ROWS = 150 # 学習時の画像の行数 COLS = 150 # 学習時の画像の列数 CHANNELS = 3 # チャネル数(カラー画像なので今回は3) train_sake = [TRAIN_DIR + i for i in os.listdir(TRAIN_DIR) if 'sake' in i] # 以下、同様の操作を行うため省略 # テストデータ test_images = [TEST_DIR + i for i in os.listdir(TEST_DIR)] train_images = train_sake + …(省略) # トレーニングデータをシャッフル random.shuffle(train_images) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 画像を読み込み、サイズを統一する def read_image(file_path): image = cv2.imread(file_path, cv2.IMREAD_COLOR) return cv2.resize(image, (ROWS, COLS), interpolation = cv2.INTER_CUBIC) # 各データの準備 def prep_data(images): count = len(images) data = np.ndarray((count, ROWS, COLS, CHANNELS), dtype = np.uint8) for i, image_file in enumerate(images): image = read_image(image_file) # ライブラリによって色情報の順序が違うため変換 data[i] = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) return data |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
train_data = prep_data(train_images) test_data = prep_data(test_images) # 学習がしやすいように正規化 train_data = train_data.astype('float32') train_data = train_data/255.0 # トレーニングデータ用ラベルデータ作成 train_labels = [] for i in train_images: if 'sake' in i : train_labels.append(0) # 以下省略 # トレーニングデータ用ラベルデータ作成 test_labels = [] for i in test_images: if 'sake' in i : test_labels_test.append(0) # 以下省略 # one-hotラベルに変換 train_labels = np_utils.to_categorical(train_labels,10) test_labels = np_utils.to_categorical(test_labels,10) |
5.モデル作成
データの準備が終わり、いよいよモデルの作成です。今回は、初心者にもとっつきやすいと評判のkerasを使ってモデル構築をします。モデルのタイプとしては全結合層だけでなく、畳み込み層とプーリング層を用いたCNNを採用しています。これは、画像の分野では頻繁に用いられています。一般的にゼロからモデルを作るというのはあまりしないと思いますが、今回はCNNの基礎ともいえるLeNetというモデルをベースに自作していこうと思います。
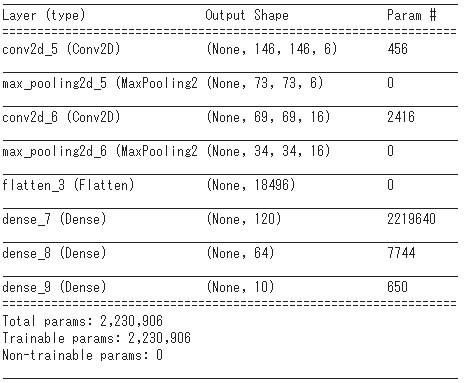
作成したモデルの詳細は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 最適化アルゴリズム optimizer = 'SGD' # 目的関数 objective = 'categorical_crossentropy' # モデル構築 def sushi_model(): model = Sequential() model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', kernel_initializer='he_normal', input_shape=(ROWS, COLS, CHANNELS))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(16, kernel_size=(5, 5), activation='relu', kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(120, activation='relu', kernel_initializer='he_normal')) model.add(Dense(64, activation='relu', kernel_initializer='he_normal')) model.add(Dense(10, activation='softmax')) model.summary() model.compile(loss=objective, optimizer=optimizer, metrics=['accuracy']) return model model = sushi_model() |
6.モデルの学習
モデルの作成も完了したので、最初に準備しておいた画像を使ってモデルの学習を行っていきます。今回はGPU環境が使えるGoogle Colaboratoryを使って処理を行っています。Google Colaboratoryに関しては、別記事で紹介しているので参考にしてみてください。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# エポック数 epochs = 30 # バッチサイズ batch_size = 20 # 損失の推移を監視する class LossHistory(Callback): def on_train_begin(self, logs={}): self.losses = [] self.val_losses = [] def on_epoch_end(self, bacth, logs={}): self.losses.append(logs.get('loss')) self.val_losses.append(logs.get('val_loss')) # 学習がある程度進んだ段階で学習を打ち切る early_stopping = EarlyStopping(monitor='val_loss', patience=10, verbose=1, mode='auto') # 寿司ネタ判別器の実行 def run_sushi_discriminator(): history = LossHistory() model.fit(train_data, train_labels, batch_size=batch_size, epochs=epochs, validation_split=0.3, verbose=1, shuffle=True, callbacks=[history, early_stopping]) predictions = model.predict(test_data, verbose=1) return predictions, history predictions, history = run_sushi_discriminator() |
学習の推移もグラフで見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
loss = history.losses val_loss = history.val_losses plt.xlabel('Epochs') plt.ylabel('Loss') plt.title('Sushi-Net Trend') plt.plot(loss, 'blue', label='Training Loss') plt.plot(val_loss, 'red', label='Validation Loss') plt.xticks(range(0,nb_epoch)[0::5]) plt.legend() plt.show() |
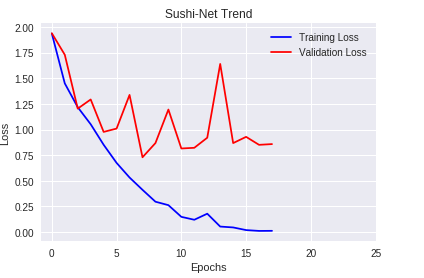
エポック数を30としていましたが、学習が進み、精度がこれ以上は向上しないと判断したら学習を止める手法であるEarly Stoppingが機能したため、途中で学習が打ち切りになりました。上のグラフからはValidation Lossの方が途中から飽和していき、Training Lossとの差が広がっていることが分かりますね。これはトレーニングデータの学習しすぎによる過学習が起きてしまっていると言えます。本来であれば、パラメータ等を変更し再度学習させるべきところですが、今回はこのまま最後まで行きたいと思います。
7.推論/精度確認
では、精度を確認してみましょう!
|
1 2 3 |
score = model.evaluate(test_data, test_labels, verbose=1) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |

lossが高く、精度は約45%とかなり低い精度になりました。数値だけではしっくりこないので、どのネタが何のネタと判定されたのか画像つきでいくつか見てみましょう。判定結果はpredictionsの中に格納されています。
※正しく認識されたものは、判定結果のセルが赤くなっています。
| 寿司ネタ(正解ラベル) | 画像 | 判定結果 |
| イカ |  |
タイ |
| サバ | 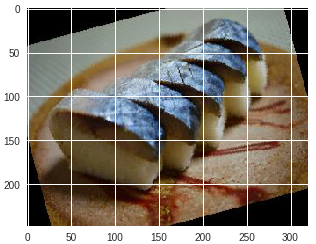 |
サバ |
| タコ | 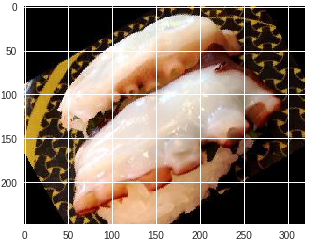 |
イカ |
| サケ | 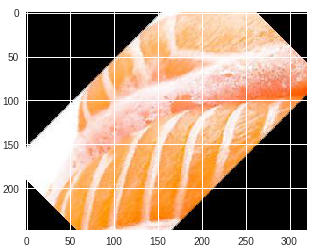 |
サケ |
| ウニ |  |
タコ |
明らかに違うでしょ!と思うものもありますね。一番下のウニの画像はお皿の割合も大きいので、対象物のみが画像内に写るように前処理を行った方がよいのかもしれません。
次は精度上げに挑戦!
今回は寿司ネタ判別器の実装に挑戦してみました!結果的には正解率が約45%とあまりよい結果は得られませんでした。次回はこの認識精度の向上を目指して、いくつか精度向上につながりそうな手法を取り入れていきたいと思います。


執筆者プロフィール

- tdi デジタルイノベーション技術部
- 配属後、ロボコン担当として、ETロボコン2017東京地区大会優勝・ITAロボコン2017優勝に貢献。現在は、AIチームの一員として、機械学習、ディープラーニングなどに挑戦しています。






