目次
モデルをAmazon SageMakerでデプロイ・推論する
私は普段、主にAI業務に従事しており、最近ではクラウドサービス(特にAWS)を使ったAIのシステム構築に関わる機会も増えてきました。今回はその中でも難航した、ローカルのJupyter NotebookやGoogle Colaboratory等で実装したモデルを、AWSのAmazon SageMakerを使ってデプロイ・推論する方法について、備忘録も兼ねてご紹介したいと思います。
主に取り上げる内容は、Kerasで実装したモデルをSageMakerを使ってデプロイまで行う方法と、1つのエンドポイントに複数モデルをデプロイする方法です。
事前準備
前提
後述のモデル実装はGoogle Colabratoryを使って行っています。TensorFlowのバージョンは”1.15.2″、Kerasのバージョンは”2.2.4-tf”を使用します。
※2020/12/07現在、デフォルトだとTensorFlowのバージョンが”2.3.0″、kerasのバージョンが”2.4.0″になっているので、同様の条件でやる場合は、TensorFlowのバージョンを明示的に指定するために、以下のコードを最初に実行し、1.xにしてください。
|
1 |
%tensorflow_version 1.x |
また、今回はAWSを使用するため、AWSアカウントがある前提で進めていきます。今回取り上げるAWSのサービスには一部無料利用枠もありますが、場合によっては料金が発生する可能性もあるので、注意してください。
(参考)
データセットの準備
今回は複数のモデルを必要とするため、適当なモデルを用意します。ここでは、準備の手間を軽減するために、以下のデータセットを使用し、Kerasでモデルを実装しました。(実装方法は割愛しますが、精度は問わないので、各自で調べてみてください。)
学習済みモデルの準備
学習が完了したら、学習済みモデルと重み(パラメータ)を保存します。
|
1 2 3 4 5 |
# モデルの保存 model_json = model.to_json() open('model.json', 'w').write(model_json) # モデルの重み(パラメータ)の保存 model.save_weights('model_weights.h5') |
これでGoogle Colaboratoryでの作業は終了です。
ノートブックインスタンスの作成
SageMakerを使った一連の作業には、Jupyter Notebookを使用します。ローカルのJupyter Notebookでも構いませんが、ここではAWSが提供しているノートブックインスタンスを使って行います。
こちらからAmazon SageMakerコンソールに移動します。
サービス一覧からSageMakerを選択、もしくは検索バーに「SageMaker」と入力し、Amazon SageMakerのサービスコンソールを開きます。Amazon SageMakerのダッシュボード左のサイドバーからノートブック > ノートブックインスタンスを選択します。
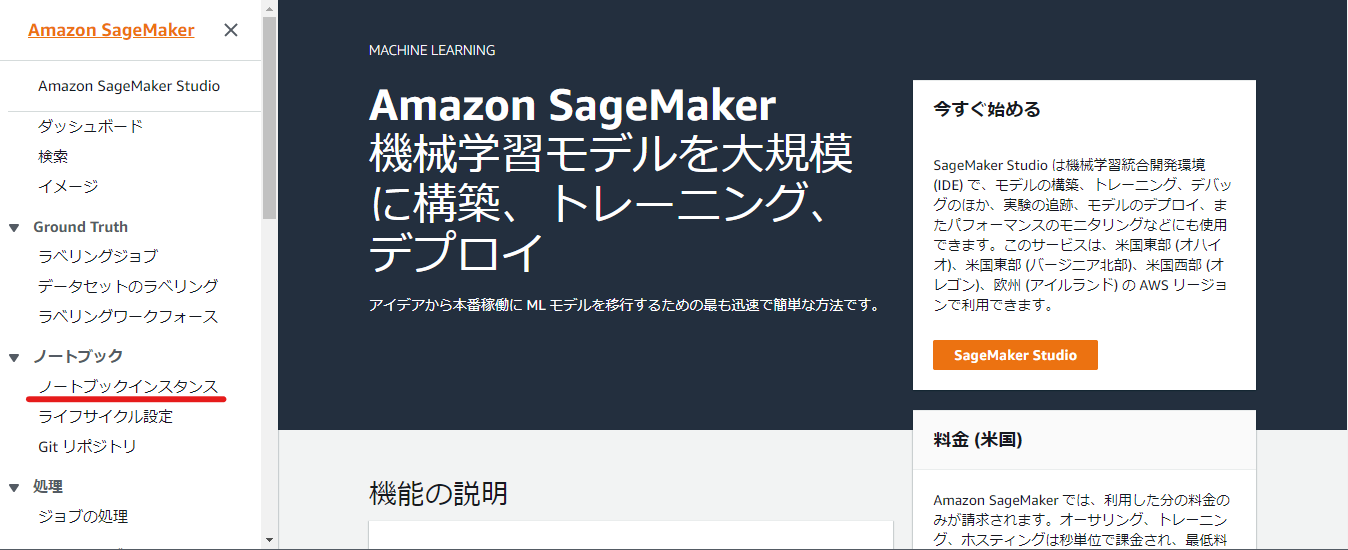
「ノートブックインスタンスの作成」を押下します。
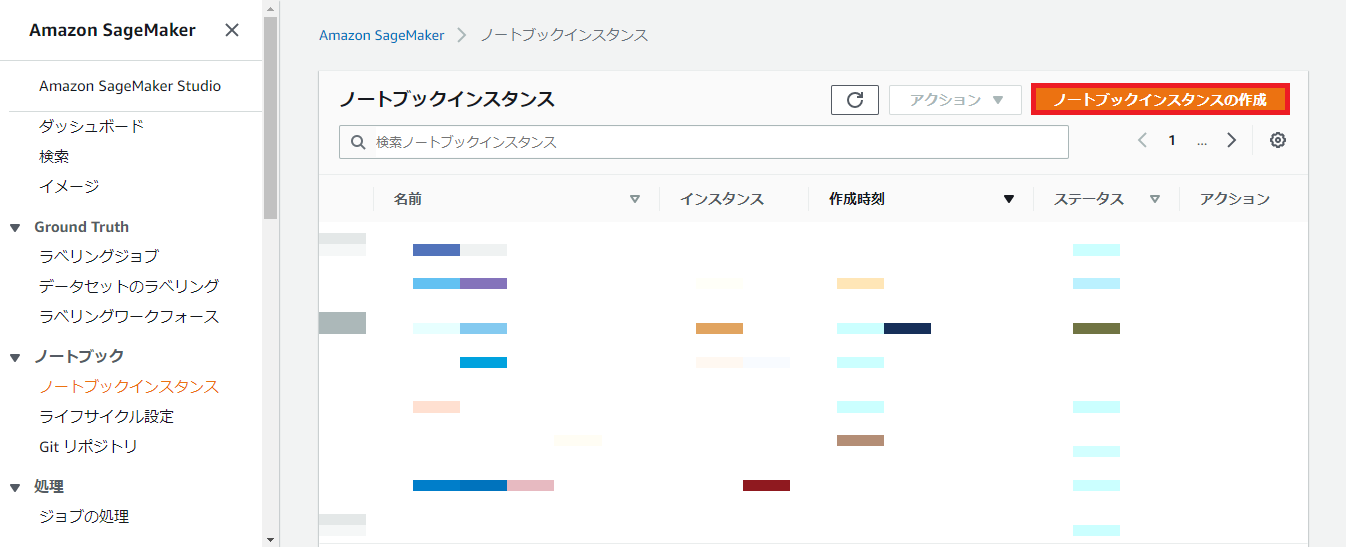
ノートブックインスタンス設定は下記を参考に入力してください。ノートブックインスタンスでは、SageMakerとS3など他のサービスを呼び出すアクセス許可が必要であるため、「AmazonSageMakerFullAccess」を持ったIAMロールを作成および指定します。IAMのサービスコンソールから作成することもできますが、ここでは「新しいロールの作成」からデフォルトの設定でロールを作成します。
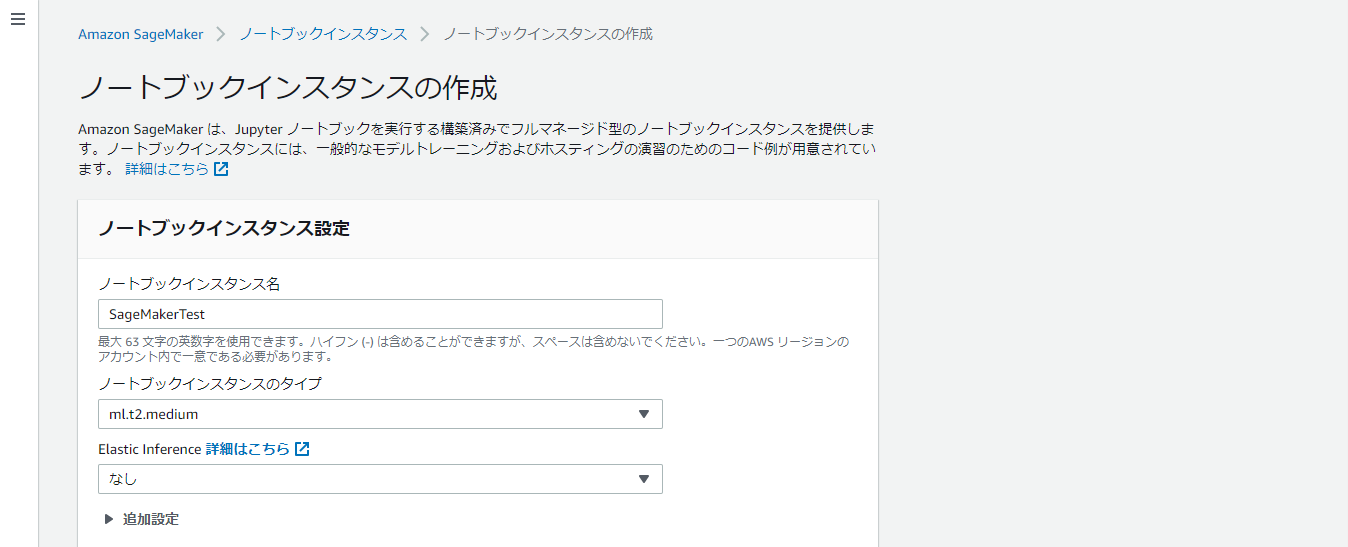
- ノートブックインスタンス設定
- ノートブックインスタンス名:任意(今回はSageMakerTest)
- ノートブックインスタンスのタイプ:任意(今回はデフォルトのml.t2.medium)
- Elastic Inference:なし
- アクセス許可と暗号化
- IAMロール:AmazonSageMakerFullAccessを持ったIAMロール(今回はデフォルトの設定で作成)
- その他の設定はデフォルト値を使用
ノートブックインスタンスのページで、作成したノートブックインスタンスを起動し、ステータスがInserviceになることを確認します。
ひとまずこれで事前準備は終了です。
SageMakerでのデプロイ
では、本題に入っていきます。
以下のような設定とフォルダ構成で進めていきます。
- カーネル
- conda_tensorflow_p36
- フォルダ構成
- sagemaker_test.ipynb
- trained_model
- ┗ cifar10
- ┗ cifar10_model.json
- ┗ cifar10_weights.h5
- ┗ fashion_mnist
- ┗ fashion_mnist_model.json
- ┗ fashion_mnist_weights.h5
- ┗ cifar10
- tf_model
- ┗ cifar10
- ┗ version名
- ┗ variables
- ┗ saved_model.pb
- ┗ version名
- ┗ fashion_mnist
- ┗ version名
- ┗ variables
- ┗ saved_model.pb
- ┗ version名
- ┗ code
- ┗ inference.py
- ┗ cifar10
Jupyterを開いたら、新規でNotebookを作成します。
ライブラリインポート
まずは、各種ライブラリのインポート等を行います。
Kerasをインポートするときは、独立したモジュールのKerasとTensorFlow付属のKerasがありますが、今回は後者を使うので注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import boto3 import json import os import sagemaker from sagemaker import get_execution_role from sagemaker.tensorflow.serving import Model import tensorflow as tf from tensorflow.keras import backend as K from tensorflow.keras.models import model_from_json from tensorflow.python.saved_model import builder from tensorflow.python.saved_model import tag_constants from tensorflow.python.saved_model.signature_def_utils import predict_signature_def # IAMロール定義 role = get_execution_role() |
学習済みモデルの読み込み
事前に作成した学習済みモデルを読み込みます。
|
1 2 3 4 5 |
# cifar10 with open('/home/ec2-user/SageMaker/trained_model/cifar10/cifar10_model.json', 'r') as cifar10_json_file: loaded_cifar10_model = cifar10_json_file.read() cifar10_model = model_from_json(loaded_cifar10_model) cifar10_model.load_weights('/home/ec2-user/SageMaker/trained_model/cifar10/cifar10_weights.h5') |
Signature作成
Signatureはモデルのインターフェースのようなもので、入出力を識別するために使います。inputsとoutputsの指定が必要です。
参考:https://www.tensorflow.org/tfx/serving/signature_defs
|
1 2 3 |
input_sig = 'inputs' output_sig = 'score' signature = predict_signature_def(inputs={input_sig: cifar10_model.input}, outputs={output_sig:cifar10_model.output}) |
モデル保存
TensorFlow Servingを使って簡単にデプロイするために、最初に用意したモデルをSavedModel形式で保存します。
|
1 2 3 4 5 6 7 8 9 |
model_version = '1' export_path = './tf_model/cifar10/' + model_version if not os.path.exists(export_path): os.mkdir(export_path) with K.get_session() as sess: builder = tf.saved_model.builder.SavedModelBuilder(export_path) builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING], signature_def_map={'serving_default': signature}, main_op=tf.tables_initializer()) builder.save() |
saved_model_cliを使うことでSavedModelの入出力を確認できます。
|
1 |
!saved_model_cli show --dir $export_path --all |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: signature_def['serving_default']: The given SavedModel SignatureDef contains the following input(s): inputs['inputs'] tensor_info: dtype: DT_FLOAT shape: (-1, 32, 32, 3) name: conv2d_4_input:0 The given SavedModel SignatureDef contains the following output(s): outputs['score'] tensor_info: dtype: DT_FLOAT shape: (-1, 10) name: dense_5/Softmax:0 Method name is: tensorflow/serving/predict |
モデルをS3にアップロード
予めcodeディレクトリの中に、事前・事後処理スクリプトのinference.pyを格納しておきます。この時、必要なライブラリがあれば、requirements.txtとして同じ場所に格納しますが、今回は特に必要はありません。
デプロイ時に参照するモデルデータはS3に置いておく必要があります。そのため、codeディレクトリと先ほど作成したモデルデータが入ったディレクトリを一緒に圧縮し、S3にアップロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import base64 import io import json import requests def input_handler(data, context): if context.request_content_type == "application/json": body = data.read().decode("utf-8") param = json.loads(body) return json.dumps(param) else: _return_error(415, 'Unsupported content type "{}"'.format(context.request_content_type or 'Unknown')) def output_handler(response, context): if response.status_code != 200: _return_error(response.status_code, response.content.decode('utf-8')) response_content_type = context.accept_header prediction = response.content return prediction, response_content_type def _return_error(code, message): raise ValueError('Error: {}, {}'.format(str(code), message)) |
|
1 2 |
cd /home/ec2-user/SageMaker/tf_model/ !tar zcvf cifar10_model.tar.gz code --directory=cifar10 $model_version |
|
1 2 |
sagemaker_session = sagemaker.Session() cifar10_model_data = sagemaker_session.upload_data(path='cifar10_model.tar.gz', key_prefix='model') |
S3を確認すると、モデルがちゃんとアップロードされていることが分かります。
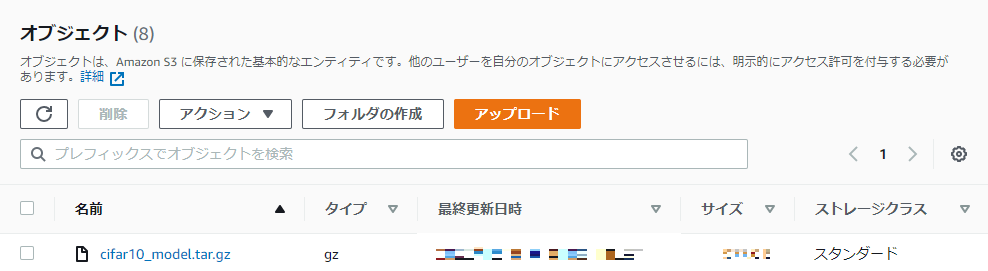
単一モデルデプロイ
下記を実行します。デプロイが完了するまで少し時間がかかるので、気長に待ちます。
|
1 2 3 4 5 6 |
tensorflow_serving_cifar10_model = Model(model_data=cifar10_model_data, role=role, framework_version='1.14.0') predictor = tensorflow_serving_cifar10_model.deploy(initial_instance_count=1, instance_type='ml.t2.medium', endpoint_name='cifar10-endpoint') |
複数モデルデプロイ
1つのエンドポイントに複数のモデルをデプロイする方法もご紹介します。
やることはほとんど単一の時と同じです。モデルをS3にアップする際に下図のようにまとめて圧縮します。
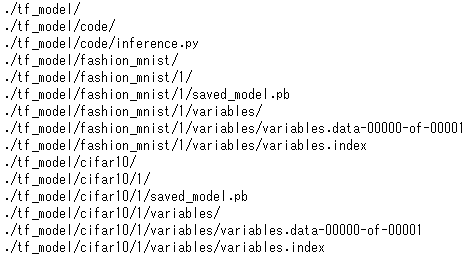
オプションとして環境変数(env)を定義しておきます。今回はデフォルトのモデルをcifar10にしています。
|
1 2 3 4 5 6 7 8 |
env = { 'SAGEMAKER_TFS_DEFAULT_MODEL_NAME': 'cifar10' } tensorflow_serving_model = Model(model_data=cifar10_model_data, role=role, framework_version='1.14.0', env=env) predictor = tensorflow_serving_model.deploy(initial_instance_count=1, instance_type='ml.t2.medium', endpoint_name='multi_endpoint') |
SageMakerでの推論
単一verでの推論
必要な前処理やモデルに入力する際の形状を調整し、実際に推論を行って結果を確認します。
|
1 2 3 4 5 6 |
client = boto3.client("sagemaker-runtime") res = client.invoke_endpoint(EndpointName=predictor.endpoint_name, Body=json.dumps({'inputs':img.tolist()}), ContentType='application/json', Accept='application/json') result = json.loads(res['Body'].read()) |
ちゃんと推論結果が返ってきていますね。
|
1 2 3 4 5 6 7 8 9 10 |
{'outputs': [[0.00372815761, 0.00345002953, 0.0572209284, 0.336594731, 0.327576339, 0.0408443436, 0.214840576, 0.0126564596, 0.00157217472, 0.00151623122]]} |
複数verでの推論
CustomAttributesで指定するだけで、モデルを切り替えて推論ができます。
|
1 2 3 4 5 6 7 8 9 10 |
cifar10_response = client.invoke_endpoint(EndpointName=predictor.endpoint_name, Body=json.dumps({"inputs":cifar10_img.tolist()}), ContentType="application/json", Accept="application/json") fashion_mnist_response = client.invoke_endpoint(EndpointName=predictor.endpoint_name, Body=json.dumps({"inputs":fashion_mnist_img.tolist()}), ContentType="application/json", Accept="application/json", CustomAttributes='tfs-model-name=fashion_mnist') |
※立ち上げたままだと課金され続けてしまうので、不要になったエンドポイントは削除するようにしてください。
おわりに
Amazon SageMakerの使い方自体は、世の中には他にも記事がたくさんあり、目新しいものではありませんでしたが、個人的に今回やるにあたって、SageMaker PythonSDKのバージョン、TensorFlowのバージョン等、ほんの少し違うだけで、エラーになって動作しないことが多くあったため、ドキュメントをしっかりと隅々まで読むことの大切さを改めて痛感しました。移り変わりが激しいので、ドキュメントの公開/更新時期もよく確認することをおすすめします。
今は、有難い日本語翻訳機能があるとはいえ、英語のドキュメントだとどうしても見落としてしまう部分も多いので、英語への耐性も必要ですね。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 配属後、ロボコン担当として、ETロボコン2017東京地区大会優勝・ITAロボコン2017優勝に貢献。現在は、AIチームの一員として、機械学習、ディープラーニングなどに挑戦しています。