
目次
はじめに
皆様は機械学習やDeep Learningを行う際の実行環境には何をお使いでしょうか。Local PCでやりくり?AWS等のIaaS?それとも社内や自宅に専用機があったりするのでしょうか。
機械学習やDeep Learningを快適に行うためにはそれなりのマシンスペックが必要になります。ある程度のメモリ容量はもちろん、GPUも必須といっていいレベルでしょう。
通常使用のPCでは、メモリが足りず処理できなかったり、1試行ごとに数十分~数時間待つことになったりということがあるのではないでしょうか。また、IaaSを用いれば高スペックな環境を手に入れることはできますが、コストもかかりますし、環境設定に翻弄されることも多いですよね。
実は上に挙げたものは私たちのチームが直面した問題でした。機械学習やDeep Learningを行う際、処理待ちや環境設定に時間を取られてしまい、本来行いたい、手法やモデルの試行錯誤のための充分な時間の確保に問題が生じたのです。
この問題をある程度解決しうる手段としてクラウド上のデータ分析基盤を用いるというのがあります。IBM CloudやAWS、Google等が提供しています。
今回はその中で最も導入が楽(そう)なGoogleのサービスを紹介します。
その名も、「Google Colaboratory」です!
Google Colaboratoryとは
Colaboratory は、機械学習/Deep Learningの教育や研究の促進を目的とした Google 研究プロジェクトです。完全にクラウドで実行される Jupyter ノートブック環境を特別な設定なしにご利用いただけます。
Colaboratory ノートブックは Google ドライブに保存され、Google ドキュメントや Google スプレッドシートと同じように共有できます。Colaboratory の利用は無料です。
Hello,Colaboratory(welcome.ipynb)より抜粋
Google Colaboratoryは、Jupyter Notebook (*1)をベースとした、Googleの仮想マシン上で動くPython実行環境です。無料であり、Googleアカウントさえあれば、インストール等の作業に手間を取られることなく、すぐにコードを実行することができます。
引用にも載っていますが、ソースコードや実行結果はGoogleドライブに保存されるため、編集権限を付与してチーム内で共有・同時編集することで、ペアプログラミング等も容易に行えます。また、GPUも無料で利用することができるので、GPUコンピューティングによる機械学習やDeep Learning等の処理の高速化も可能です。
(*1) Jupyter Notebook とは
The Jupyter Notebook
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
Google翻訳
Jupyterノートブックは、ライブコード、方程式、視覚化、物語テキストを含むドキュメントを作成して共有できるオープンソースのWebアプリケーションです。データの消去と変換、数値シミュレーション、統計モデリング、データの視覚化、機械学習などがそれに含まれます。
我々のチームでも、Pythonのインタラクティブな実行環境として用いています。Jupyter Notebookに処理内容と結果・Markdownでの文章も記載できるため、簡単な共有はこれで行えます。
Google Colaboratoryを使ってみる
Google Colaboratoryを使ってみるための手順はたったの3ステップです。
ステップ1:GoogleのColaboratoryページ にアクセス(導入ページにリダイレクトされます)
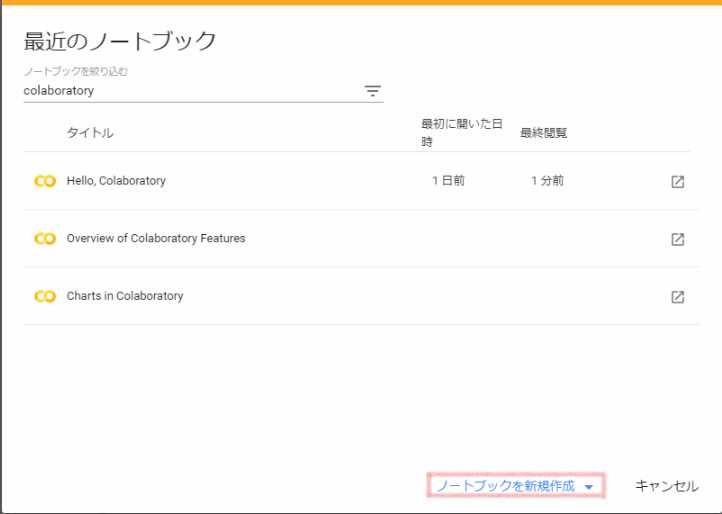
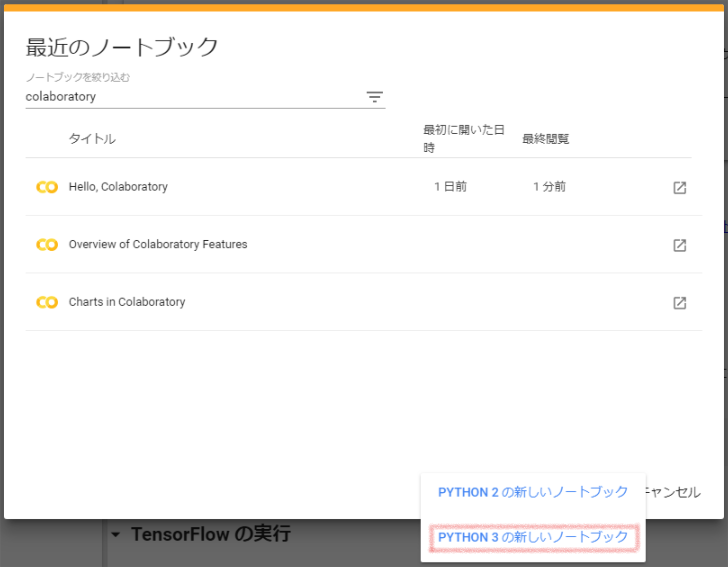
ステップ2:「ノートブックを新規作成」をクリックし、「PYTHON 3 の新しいノートブック」を選択
ステップ3:コードを入力し、Ctrl + Enter で実行!
print("hello colaboratory!") |
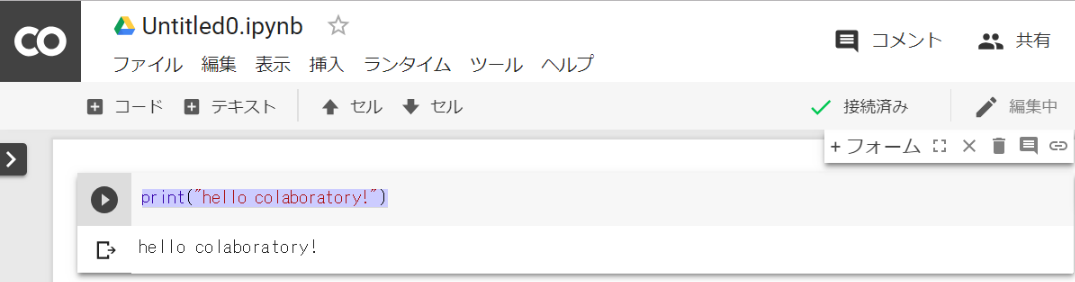
入力欄(セル)の下に結果が表示されました!Pathを通したりといった面倒な作業なしにPythonの実行環境が手に入りましたね!
Google Colaboratoryの実行環境を確認する
さて、Google Colaboratoryが簡単に使えるからと言って、ライブラリを大量にインストールしなければいけなかったり、スペックが悪かったら使えるとは言えません。いくつか確認していきましょう。
事前準備を行う
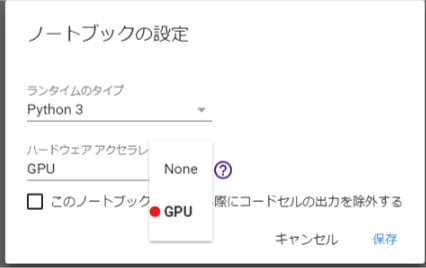
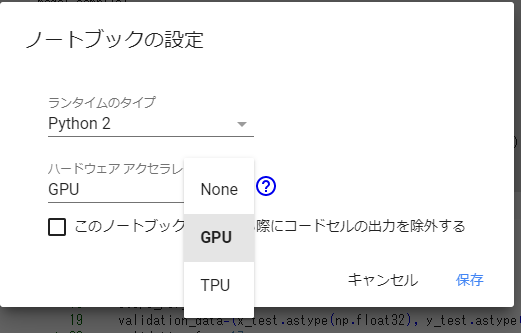
GPUの情報もみたいのですが、実はそのまま起動するとGPUのない環境が立ち上がります。
「ランタイム」 → 「ランタイムのタイプを変更」から
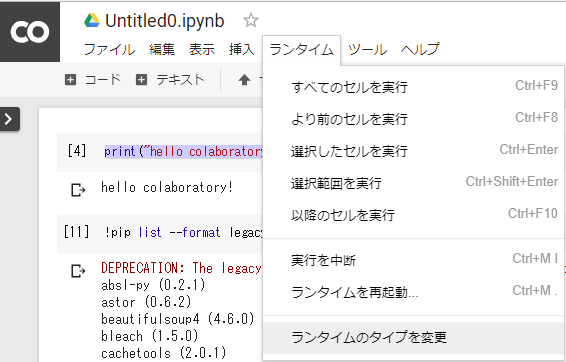
「ハードウェアアクセラレータ」で「GPU」を選択して保存してください。
ライブラリを確認する
pipが使えるので簡単にライブラリを確認することができます。「+コード」を押して、入力欄を追加します。コードの先頭に「!」をつけることで、PythonではなくOSのコマンドラインに命令を送ることができます。
!pip list |
ずらずら出てきました。かなり長いので、詳しく見たい場合は是非実行してみてください。
抜粋すると、よく使うであろう、matplotlib、pandas、numpy、scikit-learnや、Deep Learningに用いるtensorflow、keras等も入っていますね。個人的にはPillow、plotly、xgboostが入っているのも有難いです。目的によってはいくつかインストールしなければいけないでしょうが、大量のインストールを待つ必要はなさそうです。
スペックを確認する
どうやらOSはUbuntuらしいです。なんとapt-getが使えます!ということでハードウェア情報を収集するためにlshwをインストールし、実行します。
|
インストールが終わったら実行して結果を確認します。
|
重要そうな部分だけ抜粋すると以下のような構成のようです。
*-memory description: System memory physical id: 0 size: 12GiB
*-cpu product: Intel(R) Xeon(R) CPU @ 2.30GHz vendor: Intel Corp. physical id: 1 bus info: cpu@0 width: 64 bits
*-display description: 3D controller product: GK210GL [Tesla K80]
どうやらメモリが12GB、GPUはTesla K80のようです。超一線級ではないとはいえTeslaが無料で使えるとはすばらしい。CPUはあまり詳しくないのですがこの分だと悪いものではなさそうです。
Google ColaboratoryのGPUを使ってMNISTを実行する
題材はDeep LearningのHello worldとも呼ばれるMNIST(*2)を利用しました。Kerasを用いて一般的な畳み込みモデルを学習させてみます。
(*2) MNISTとは
Modified National Institute of Standards and Technology の略称で、データセットを用いた手書き文字分類問題のこと。手書きの0~9の数字画像を対応する数字に分類する問題です。
(Yann LeCunホームページより)
事前準備を行う
まずはGPUを認識しているかの確認を、backendのTensorFlowで行います。
|
結果
|
ちゃんと認識しているようです。自力でやろうとするとドライバを更新したりなんだり面倒なので、これだけでも感動しますね。
MNISTを実行する
ソースコードはKerasが公開しているチュートリアルコードを用いました。
実行した2018/05/22 16:11時点のコードを引用します。
|
結果
|
1epoch 11秒ほど!GPU無しでやると160秒程度かかりますから1/16ほどの時間になってますね!素晴らしい時間短縮です。
参考:GPU無しでの実行結果(抜粋)
|
TPUを使ってFashion MNIST
更新が大変遅れてしまったのですが、なんと無料でTPUが使えるようになっております。
TPUとは
テンサー・プロセッシング・ユニット(Tensor processing unit、TPU)はGoogleが開発した機械学習に特化した特定用途向け集積回路(ASIC)。グラフィック・プロセッシング・ユニット(GPU)と比較して、ワットあたりのIOPSをより高くするために、意図的に計算精度を犠牲に(8ビットの精度[1])した設計となっており、ラスタライズ/テクスチャマッピングのためのハードウェアを欠いている[2] 。
wikipedia – テンソル・プロセッシング・ユニットより抜粋
グラフィック処理向けに作られたGPUと異なり、Deep Learningを行うために作られた集積回路ということですね。計算一つ一つの精度より計算速度を優先した設計になっているそうです。他にも、内部での値の受け渡しをメモリを介さないようにする等、様々な工夫が行われています。
性能確認
それでは、特化型の性能を確認してみましょう!
Google ColaboratoryでTPUを利用するチュートリアルは、Cloud TPU Colab ノートブック として、Googleがいくつか提供してくれています。今回は、内容がシンプルな、Fashion MNIST with Keras and TPUsを用いて検証します。
- ランタイムのタイプの変更
GPUの時と同様に、「ランタイム」→「ランタイムのタイプの変更」を選択します。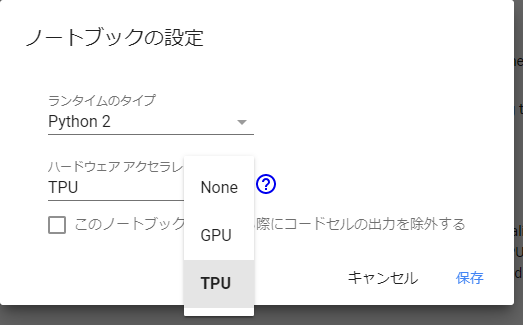
以前と比べてTPUが増えています!チュートリアルのノートブックはデフォルトでTPUになっているので、今回はそのままキャンセルを押し、ノートブックの設定を閉じます。
- Fashion MNISTの実行
「ランタイム」→「全てのセルを実行」を選択することで、データの読み込みから学習・推論まで行われます。
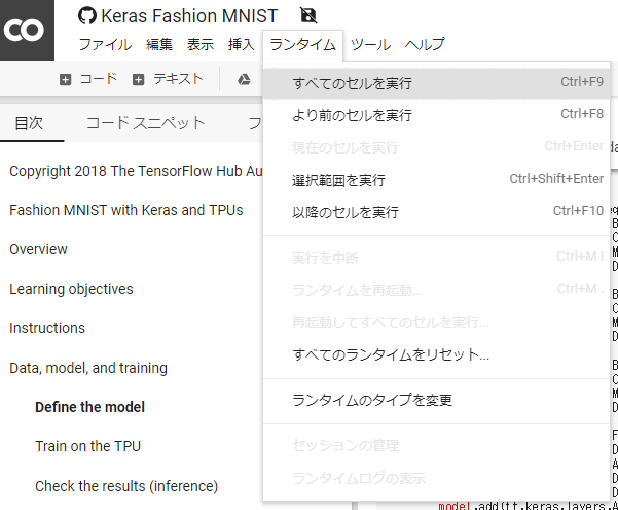
Train on the TPU
To begin training, construct the model on the TPU and then compile it.
と書いてある部分の下が学習を行っている箇所になります。
出力
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
Epoch 1/17 60/60 [==============================] - 4s 68ms/step - loss: 1.2539 - sparse_categorical_accuracy: 0.6604 Epoch 2/17 60/60 [==============================] - 1s 24ms/step - loss: 0.5539 - sparse_categorical_accuracy: 0.8136 Epoch 3/17 60/60 [==============================] - 1s 23ms/step - loss: 0.4491 - sparse_categorical_accuracy: 0.8463 Epoch 4/17 60/60 [==============================] - 1s 23ms/step - loss: 0.3953 - sparse_categorical_accuracy: 0.8628 Epoch 5/17 60/60 [==============================] - 1s 23ms/step - loss: 0.3553 - sparse_categorical_accuracy: 0.8759 Epoch 6/17 60/60 [==============================] - 1s 23ms/step - loss: 0.3255 - sparse_categorical_accuracy: 0.8842 Epoch 7/17 60/60 [==============================] - 1s 23ms/step - loss: 0.2928 - sparse_categorical_accuracy: 0.8951 Epoch 8/17 60/60 [==============================] - 1s 23ms/step - loss: 0.2744 - sparse_categorical_accuracy: 0.9020 Epoch 9/17 60/60 [==============================] - 1s 23ms/step - loss: 0.2549 - sparse_categorical_accuracy: 0.9085 Epoch 10/17 60/60 [==============================] - 1s 24ms/step - loss: 0.2406 - sparse_categorical_accuracy: 0.9129 Epoch 11/17 60/60 [==============================] - 1s 24ms/step - loss: 0.2255 - sparse_categorical_accuracy: 0.9180 Epoch 12/17 60/60 [==============================] - 1s 23ms/step - loss: 0.2133 - sparse_categorical_accuracy: 0.9227 Epoch 13/17 60/60 [==============================] - 1s 23ms/step - loss: 0.1998 - sparse_categorical_accuracy: 0.9272 Epoch 14/17 60/60 [==============================] - 1s 23ms/step - loss: 0.1908 - sparse_categorical_accuracy: 0.9290 Epoch 15/17 60/60 [==============================] - 1s 23ms/step - loss: 0.1784 - sparse_categorical_accuracy: 0.9334 Epoch 16/17 60/60 [==============================] - 1s 23ms/step - loss: 0.1708 - sparse_categorical_accuracy: 0.9372 Epoch 17/17 10/10 [==============================] - 4s 369ms/step |
1Epoch 1秒といったところでしょうか。これだけだと性能がわからないのでGPUで同じコードを実行してみましょう。
- GPUでコードを実行
ランタイムのタイプをGPUに変更します。
先ほど確認したTrain on the TPUのセルにおいて、resolver ..からwith strategy..をコメントアウトすることで、TPUを利用する処理を削除して実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import os # resolver = tf.contrib.cluster_resolver.TPUClusterResolver('grpc://' + os.environ['COLAB_TPU_ADDR']) # tf.contrib.distribute.initialize_tpu_system(resolver) # strategy = tf.contrib.distribute.TPUStrategy(resolver) #with strategy.scope(): model = create_model() model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3, ), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy']) model.fit( x_train.astype(np.float32), y_train.astype(np.float32), epochs=17, batch_size = 60, steps_per_epoch=60, validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)), validation_freq=17 ) model.save_weights('./fashion_mnist.h5', overwrite=True) |
結果
|
1 |
(0) Resource exhausted: OOM when allocating tensor with shape[60000,64,28,28] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[{{node conv2d_3/Conv2D}}]] |
エラーが出てしまいました。OOMはOutOf Memoryなので、どうやらメモリが足りないようです。今回の目的は性能(速度)比較を行いたいだけですので、15行目を変更することで単純に読み込むデータ数を減らして再実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import os # resolver = tf.contrib.cluster_resolver.TPUClusterResolver('grpc://' + os.environ['COLAB_TPU_ADDR']) # tf.contrib.distribute.initialize_tpu_system(resolver) # strategy = tf.contrib.distribute.TPUStrategy(resolver) #with strategy.scope(): model = create_model() model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3, ), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy']) model.fit( x_train.astype(np.float32)[:17*60], y_train.astype(np.float32)[:17*60], epochs=17, batch_size = 60, steps_per_epoch=60, validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)), validation_freq=17 ) model.save_weights('./fashion_mnist.h5', overwrite=True) |
結果
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Epoch 1/17 60/60 [==============================] - 15s 258ms/step - loss: 0.9501 - sparse_categorical_accuracy: 0.7417 Epoch 2/17 60/60 [==============================] - 13s 222ms/step - loss: 0.1613 - sparse_categorical_accuracy: 0.9422 Epoch 3/17 60/60 [==============================] - 13s 222ms/step - loss: 0.0420 - sparse_categorical_accuracy: 0.9853 Epoch 4/17 60/60 [==============================] - 13s 221ms/step - loss: 0.0147 - sparse_categorical_accuracy: 0.9954 Epoch 5/17 60/60 [==============================] - 13s 222ms/step - loss: 0.0066 - sparse_categorical_accuracy: 0.9982 Epoch 6/17 60/60 [==============================] - 13s 222ms/step - loss: 0.0049 - sparse_categorical_accuracy: 0.9987 |
1Epoch 13秒ほどですね。TPUだと1Epoch 1秒ほどなので、TPUはGPUの13倍高速という結果になりました。TPUのために設計されたモデルということを考慮しても、かなり大きな差です。特化型というのは伊達じゃないということですね!
まとめ
いかがでしたでしょうか。GPU環境をこんなに簡単に使えるGoogle Colaboratoryは、これから始める際の第一手としてかなり有力です。さらになんとGoogleがDeep Learning専用に開発したTPUまで無料で使える優れものです。
また、今回は触れませんでしたが、入力補助やショートカットも豊富なので、Google Colaboratoryを使いこなせればかなり強力だと思います!
強いて言うならRAMが少なめなので、データの読み方を考慮する必要があるかもしれません。TFRecord形式を用いて使用メモリ量を削減する方法は、下記の過去記事をご参照ください。

今後は、Google Colaboratoryの機能紹介を継続的に行っていく予定です!また、他のデータ分析SaaSの検証もご紹介する予定ですので、お楽しみに!

更新履歴
- 2018年6月7日公開の記事を更新しました(TPUに関する内容を追加)。

執筆者プロフィール

- tdi デジタルイノベーション技術部
-
入社して半年間ロボコン活動に専念。少しのJavaエンジニア期間を経てデータ分析や機械学習、Deep Learningをテーマに勤労しております。
昔取った杵柄を摩耗させつつ新たな支えを求めて試行錯誤中。
この執筆者の最新記事
 Pick UP!2020年10月30日Python/Kerasで学習させたモデルをJavaで動かすだけじゃ速くならなかった
Pick UP!2020年10月30日Python/Kerasで学習させたモデルをJavaで動かすだけじゃ速くならなかった ITコラム2020年8月4日DL4Jを使うためにEclipseでMaven使おうとして困ったら
ITコラム2020年8月4日DL4Jを使うためにEclipseでMaven使おうとして困ったら AI2019年11月29日AIの検証・開発を行うときに必要なハードウェア条件とは?
AI2019年11月29日AIの検証・開発を行うときに必要なハードウェア条件とは? AI2019年8月5日Google Colaboratoryの無料GPU環境を使ってみた
AI2019年8月5日Google Colaboratoryの無料GPU環境を使ってみた


