
はじめに
前回の記事では、私がAIチームに配属されてから学習してきた内容を活かした、寿司ネタ判別器の実装についてご紹介しました。

推論結果としては、認識精度が約45%だったため、今回はモデルの精度向上を図っていこうと思います。
1.データクレンジング
Deep Learningは、良いモデルをつくるためには大量のトレーニングデータが必要だとよく言われますが、その中に質の悪い画像が含まれていると却ってモデルの精度が悪くなってしまうことがあります。汎用性を高めるには各カテゴリーごとにいろいろなバリエーションの画像があったほうが良いですが、なんでもかんでもトレーニングデータとして使うのではなく、品質の良さを保持した上で画像の収集を行うことが大切です。
前回、寿司ネタの画像を必死に集めましたが、収集した画像の中には寿司に被さるように文字やイラストが書かれていたり、これは本当にこの寿司なの?と、人の目で見ても判別つかないような画像も混ざっていました。時間はかかりますが、少しでも精度を向上させるために、そのようなデータは取り除いておきましょう。不要なデータと判断するポイントをいくつか挙げておきます。
- 実際に使われないようなデータはできるだけ避ける
- 人の目で見ても判断しづらいデータは学習させないようにする
- ラベル付けが正しくできているかの確認も忘れずに行う
2.転移学習
ここからが今回の記事の本題になります。前回はCNNの基礎ともいえるLeNetをベースに、1からモデルを実装していましたが、今回はモデル実装に転移学習を導入してみようと思います。
転移学習とは、ある分野/領域で学習させたモデルを別の分野/領域に適応させる学習方法のことです。この転移学習のメリットは、少ないデータ数でも精度の高い結果を得ることができる可能性に満ちているところです。今回使うモデルは転移学習でよく用いられているVGG16というモデルです。VGG16は、畳み込み層とプーリング層から構成されるとても基本的なCNNのモデルですが、名前にもある通り、16層にも重ねているところが特徴です。ImageNetという100万枚を超える画像のデータセットを、1000カテゴリに分類する大規模画像認識のコンペティション ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で、高い成績を収めたことでも有名なモデルになってます。
なぜ転移学習でこのようなモデルが使われ、高精度の結果が得られるのかというと、たくさんの画像を大量のカテゴリに分類したネットワークの上層部分は似たようなフィルタになるためだと言われています。また、後述するファインチューニングと転移学習の違いは、出力層以外の層の重みを変更するかどうかです。
※転移学習は重みを変更しないで利用する方です。
厳密に上記のように定義されているのかは分かりませんが、今回は便宜上、別用語として扱います。
では、さっそく実装に移っていきましょう。前回の記事で実装した関数sushi()の中身を以下のように変更するだけで転移学習を試すことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
optimizer = 'SGD' objective = 'categorical_crossentropy' def sushi(): input_tensor = Input(shape=(ROWS, COLS, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu', kernel_initializer='he_normal')) top_model.add(Dropout(0.5)) top_model.add(Dense(10, activation='softmax')) model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output)) # 最後の層の直前までの重みを固定 for layer in model.layers[:15]: layer.trainable = False model.summary() model.compile(loss='categorical_crossentropy', optimizer ="SGD", metrics=['accuracy']) return model model = sushi() |
モデルの概要は以下のようになっています。

今回はエポック数(epoch)を35、バッチサイズ(batch_size) を20として、学習をさせてみます。

今回もGoogle Colaboratory(GPUあり)を使って学習させていますが、学習時間は約1時間程かかりました。過学習が起きている様子もなく、学習は順調に進んでいるように見えます。
![]()
推論結果を見てみましょう。
前回よりも少しだけ認識精度が上がっていました!(45%⇒52%)

3.ファインチューニング
先ほどは、VGG16のモデルを使った転移学習と推論を行いました。ここでは、重みを固定せず、VGG16の重みも学習させていくファインチューニングをやってみたいと思います。ソースコードの変更箇所は一部で、下記をコメントアウトすることで試すことができます。(先ほどのソースコードの20行目~21行目)
|
19 20 21 |
# 最後の層の直前までの重みを固定 for layer in model.layers[:15]: layer.trainable = False |
コードを修正し、さっそく学習をさせてみましょう。
今回もエポック数(epoch)を35、バッチサイズ(batch_size) を20として、学習をさせてみます。

こちらも過学習が起きている様子は見られず、学習は順調に進んでいるようです。学習時間は約2時間かかりました。また、先ほどのグラフよりもTraining LossとValidation Lossの差が縮まっていますね。
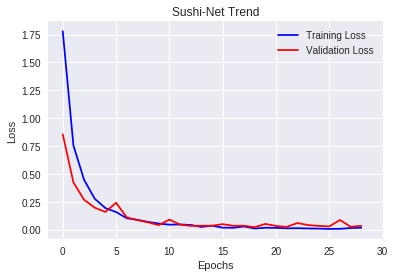
気になる推論結果はどうなったでしょうか。
転移学習の時よりも精度がさらに向上しました!(52%⇒69%)

前回の記事で最後に判定結果を見てみた画像について、今回の手法を取り入れたことで判定結果に違いが出たのかも見てみましょう。
※セルが赤くなっているところが、正しく判定できたもの
| 寿司ネタ(正解ラベル) | 画像 | 判定結果(前回) |
判定結果(転移学習) |
判定結果(ファインチューニング) |
| イカ |
|
タイ | マグロ | イカ |
| サバ |
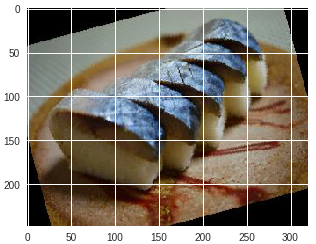 |
サバ | サバ | サバ |
| タコ |
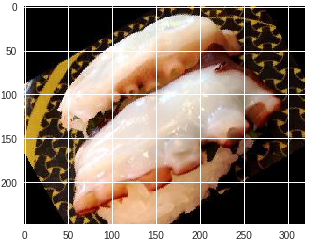 |
イカ | タコ | タコ |
| サケ |
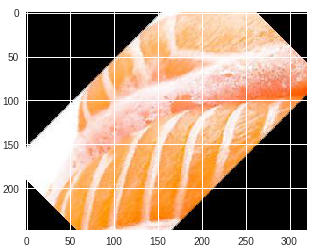 |
サケ | サケ | サケ |
| ウニ |
 |
タコ | イクラ | ウニ |

なんとファインチューニングを行った方は、5つの寿司ネタ全てを正しく判定しています!
4.おわりに
ここまで、私がAIチームに配属されてからの学習ステップ、寿司ネタ判別器の実装、モデルの精度向上と3回に渡りご紹介してきましたが、いかがだったでしょうか?既に世の中に出回っていることも多かったかもしれませんが、みなさんもオリジナルのデータでぜひ試してみてください!
個人的にインプットだけだとなかなか身につかないところも多いため、今回のように学んだ内容を実際に手を動かしながら試してアウトプットしてくことが大切だなと感じました。まだまだ精度が高いとは言えないので、さらなる精度向上を目指していきたいと思います。ここまで読んで下さりありがとうございました。
過去記事はこちら>>


執筆者プロフィール

- tdi デジタルイノベーション技術部
- 配属後、ロボコン担当として、ETロボコン2017東京地区大会優勝・ITAロボコン2017優勝に貢献。現在は、AIチームの一員として、機械学習、ディープラーニングなどに挑戦しています。






