
はじめに
人工知能(AI)がブームですね。そして、AIによる文字や画像の認識精度が非常によくなっています。また、その中でも、ディープラーニングについては、認識精度の向上とは反対に、アルゴリズムの説明が難しくなっており、ブラックボックス化について語られるようになっています。
そのような状況において、故意に誤検知させることによって、”問題”を発生させるような攻撃が指摘されており、例えば、道路標識にステッカーを貼り付けることで誤認識させた例が、大学の研究で発表されています。(Robust Physical-World Attacks on Deep Learning Visual Classification)
今回は、攻撃手法の1つである「アドバーサリアル・エグザンプル」(Adversarial Examples)を取り上げます。これは、ある学習済みのモデルに対して、画像を与えて推論を行う際に、その画像に対して特殊なノイズを加えることで、誤認識を起こさせる手法です。
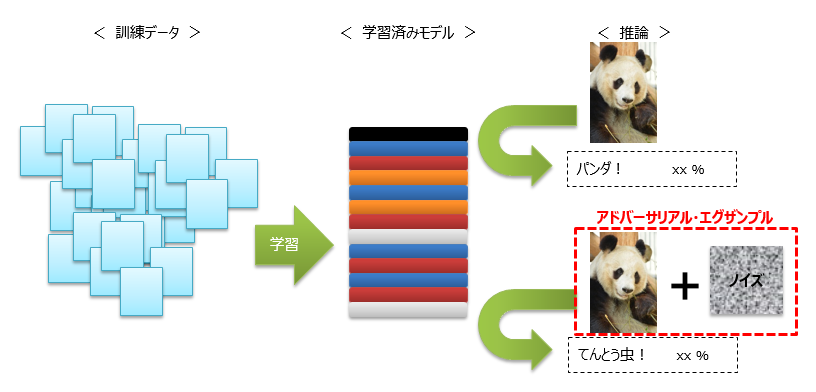
後程、「アドバーサリアル・エグザンプル」として作られた画像を掲載していますが、人間が見る分には正しく認識できる程度のノイズです。
ところで、深層学習は、入力データをベースに学習を進めるので、入力データは非常に重要になります。しかし、学習済みモデルを推論に利用する際には、どのようなデータが入力されるか分からず、事前にそのような訓練データを準備するには限界があります。
では、対策はどのようにすればいいのか。「アドバーサリアル・エグザンプル」対策用のPythonライブラリ「cleverhans」がGitHubで公開されているので、利用してみましょう。(執筆時の最新バージョン「V2.0.0」を前提に話を進めます)
https://github.com/tensorflow/cleverhans
このライブラリによって、学習済みモデルを疑似攻撃する(「アドバーサリアル・エグザンプル」を生成する)ことや、モデルを攻撃に対して強固にすることができます。これまでのソフトウェアの脆弱性対策と同様、唯一の万能な解決策というものはありませんが、少しずつ対策を進めていきましょう。
ということで、さっそく使ってみましょう、といきたいところですが、リンク先のページを見ていただくと分かるように、あまりドキュメントがありません。そこで、今回はチュートリアルとして挙がっている「MNIST with FGSM」について、説明を行います。
「cleverhans」のインストール
最初は、「cleverhans」をインストールしましょう。インストールの詳細は、上記リンクに記載されていますが、簡単に言うと次の感じです。(マニュアルインストールの場合)
- TensorFlowをインストールする(https://www.tensorflow.org/install/)
- サポート対象のバージョン:
- Python 2.7 もくしは 3.5
- TensorFlow 1.0 もしくは 1.1
- サポート対象のバージョン:
-
gitからソースをダウンロードする
git clone https://github.com/tensorflow/cleverhans - 環境変数「PYTHONPATH」を設定する
- 値は、gitからダウンロードしたフォルダへのパス
(例)C:\Users\(ユーザ)\src\cleverhans
- 値は、gitからダウンロードしたフォルダへのパス
チュートリアル「MNIST with FGSM」について
チュートリアル「MNIST with FGSM」は、次のことを行っています。
- MNISTを学習したモデルを作る
- 上記1のモデルに対して、手法「FGSM」(fast gradient sign method)で生成された「アドバーサリアル・エグザンプル」を与えて推論した結果の紹介
- 「アドバーサリアル・エグザンプル 」に対してモデルをより強くする「アドバーサリアル・トレーニング」(adversarial training)を実施する
実行方法
ダウンロードしたフォルダ「\cleverhans\cleverhans_tutorials」にある「mnist_tutorial_tf.py」を実行します
python mnist_tutorial_tf.py |
実行結果
実行後は、どこかにデータが残るわけではなく、次のようなログが表示されるだけとなります。では、ログを一緒に確認していきましょう。
|
1 2 3 4 5 6 7 8 9 10 |
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Extracting /tmp/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Extracting /tmp/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Extracting /tmp/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. Extracting /tmp/t10k-labels-idx1-ubyte.gz X_train shape: (60000, 28, 28, 1) X_test shape: (10000, 28, 28, 1) |
まずは、MNISTデータセットをダウンロードしています。MNISTとは、手書き文字のデータセットで、0 から 9 の手書き文字の画像とそれらに正解ラベルが付与されており、訓練データとテストデータが区別されて用意されたものです。ダウンロード後にメモリ上に格納し、データの形状を確認しています。
- 訓練データ:(枚数)6万枚、(サイズ)28×28のグレースケール
- テストデータ:(枚数)1万枚、(サイズ)28×28のグレースケール
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[INFO 2018-03-13 15:10:25,490 cleverhans] Epoch 0 took 174.24789333343506 seconds Test accuracy on legitimate examples: 0.9884 [INFO 2018-03-13 15:13:22,591 cleverhans] Epoch 1 took 171.5252697467804 seconds Test accuracy on legitimate examples: 0.9893 [INFO 2018-03-13 15:16:15,968 cleverhans] Epoch 2 took 168.23467421531677 seconds Test accuracy on legitimate examples: 0.9921 [INFO 2018-03-13 15:19:21,079 cleverhans] Epoch 3 took 179.91166853904724 seconds Test accuracy on legitimate examples: 0.9915 [INFO 2018-03-13 15:22:22,733 cleverhans] Epoch 4 took 176.27413725852966 seconds Test accuracy on legitimate examples: 0.9927 [INFO 2018-03-13 15:25:32,937 cleverhans] Epoch 5 took 184.92887806892395 seconds Test accuracy on legitimate examples: 0.9928 [INFO 2018-03-13 15:25:38,516 cleverhans] Completed model training. Test accuracy on adversarial examples: 0.1213 |
次に、ログの1~13行目は、単純に、モデルがMNISTを学習している状況です。最初から精度が高いですが、最後の6エポック目の実行後には、99.28%になっていますね(ログ:12行目)。また、ログの14行目は、その学習済みモデルに対して、「アドバーサリアル・エグザンプル」を与えて推論した結果です。精度が12.13%しかありませんね。
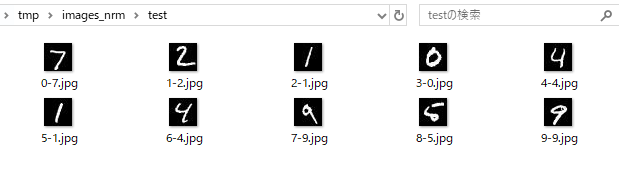
では、元の画像と、「アドバーサリアル・エグザンプル」として生成された画像は、どのように違っているのでしょうか。チュートリアルでは画像は生成してくれませんので、ソースに手を加えて、実際にデータを画像化してみましたので、確認してみましょう。
(元の画像)
(「アドバーサリアル・エグザンプル」として生成された画像)
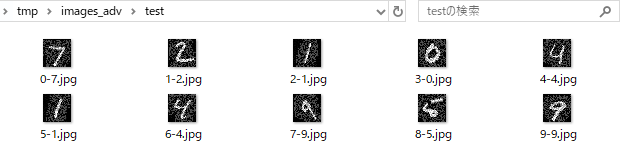
確かに、画像にノイズが入っていますが、人間が判断する分には元の文字と一緒ですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Repeating the process, using adversarial training [INFO 2018-03-13 15:32:57,856 cleverhans] Epoch 0 took 409.0198721885681 seconds Test accuracy on legitimate examples: 0.9774 Test accuracy on adversarial examples: 0.8288 [INFO 2018-03-13 15:40:11,420 cleverhans] Epoch 1 took 399.68671321868896 seconds Test accuracy on legitimate examples: 0.9876 Test accuracy on adversarial examples: 0.8990 [INFO 2018-03-13 15:47:21,736 cleverhans] Epoch 2 took 397.4520537853241 seconds Test accuracy on legitimate examples: 0.9896 Test accuracy on adversarial examples: 0.9173 [INFO 2018-03-13 15:54:41,703 cleverhans] Epoch 3 took 406.38210105895996 seconds Test accuracy on legitimate examples: 0.9914 Test accuracy on adversarial examples: 0.9363 [INFO 2018-03-13 16:01:45,682 cleverhans] Epoch 4 took 390.99851846694946 seconds Test accuracy on legitimate examples: 0.9910 Test accuracy on adversarial examples: 0.9366 [INFO 2018-03-13 16:08:58,363 cleverhans] Epoch 5 took 399.86022877693176 seconds Test accuracy on legitimate examples: 0.9914 Test accuracy on adversarial examples: 0.9384 [INFO 2018-03-13 16:09:31,499 cleverhans] Completed model training. |
最後のログが、「アドバーサリアル・トレーニング」での学習状況です。ログに記載の「legitimate examples」が、元の画像での評価結果で、ログに記載の「adversarial examples」が、「アドバーサリアル・エグザンプル」として生成された画像での評価結果です。6エポック目まで学習を行っていますが、いずれも90%超えの精度を達成しています。
さいごに
今回は、「cleverhans」のチュートリアルについて説明しました。今後、自身の開発したモデルに対して、「アドバーサリアル・トレーニング」を行い、「cleverhans」で疑似攻撃し、攻撃を防げるようなったかどうかを確かめる記事を書いてみようと思います。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 入社以来、C/S型の業務システム開発に従事してきました。ここ数年は、SalesforceやOutSystemsなどの製品や、スクラム開発手法に取り組み、現在のテーマは、DeepLearning/機械学習です。
この執筆者の最新記事
 Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて)
Pick UP!2021年11月11日VoTTを複数人で使って、アノテーションを行いたい!(ファイル移行を用いて) Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩
Pick UP!2020年11月20日AIoTデバイス「M5StickV」、はじめの一歩 RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む!
RPA2019年8月15日「OSSのRPA」+「自作の三目並べマシン」でGoogleに挑む! AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする
AI2019年4月22日暗記学習(Rote Learning)で三目並べを強くする


