
IBM Watson Explorer Analytical Components(以下、WEXAC)は、Watsonソリューションの基盤として位置付けられ、文章やDB、WEBなどに含まれる構造化および非構造化コンテンツを収集・分析し、その中に含まれる知見や問題点を発見することができる強力なテキストマイニングツールです。
前回では、アンケートを活用したいラーメン屋さんがWEXACを使ってみるケース(フィクションです)を想定して、簡単なコレクションを作成しました。

今回はカスタム・テキスト分析ルールを使って更なるコレクションの作り込みを行ってみたいと思います。
品詞を確認
取り込んだ文章の品詞を確認してみました。
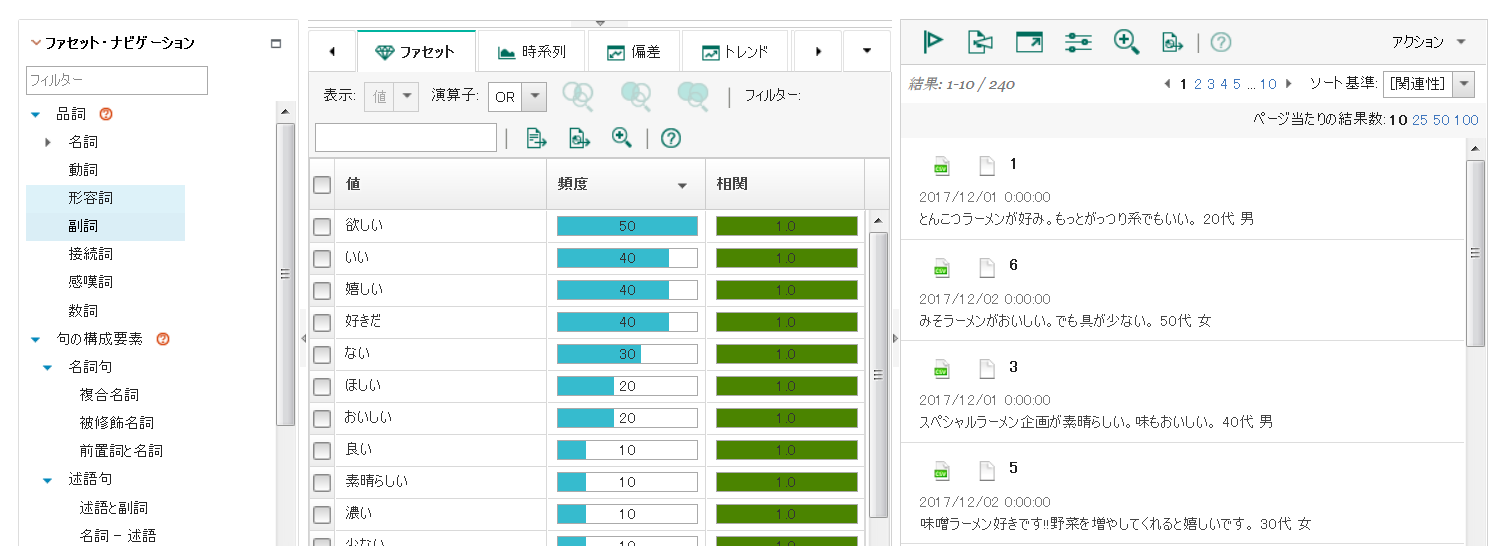
「形容詞」ファセットを見ると、「欲しい」「いい」「嬉しい」など、ニーズに繋がりそうなワードが並んでいます。何が「欲しい」のか、何があると「嬉しい」のかを抽出してみます。
カスタム・テキスト分析ルール設定
まず、ファセット・ツリーで「要望」ファセットを作成しておいた後に、カスタム・テキスト分析ルールを設定します。「解析および索引」ペインの「分析リソース」>「カスタム・テキスト分析ルール」を選択します。
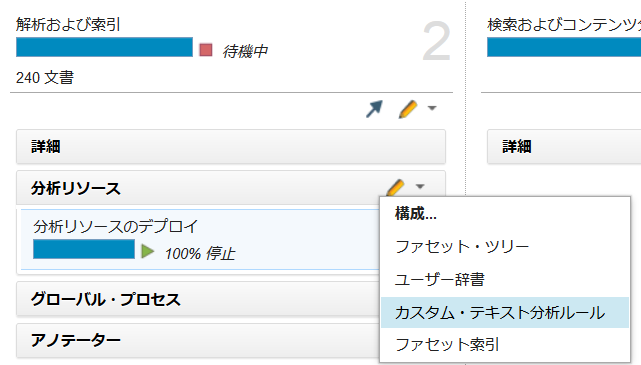
ルールファイル名(今回は「pat_request」とします)を入力し、「開く」ボタンを押下します。
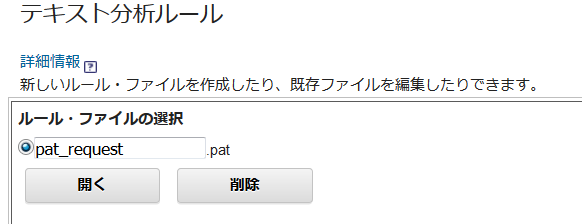
試しに、シンプルに「●●が欲しい」の「●●」を抽出してみたいと思います。ルールはXML形式で記入します。
・categoryに表示したいファセットのファセット・パス(今回は「要望」ファセットのファセット・パス)
・valueにファセット値として表示したい内容(今回は「●●」を表示するため、その要素を示す${0.lex})
を設定します。要素ごとに定義が必要なため、
・「●●」:名詞(id=”0″ pos=”noun”)
・「が」:ワード「が」(id=”1″ lex=”が”)
・「欲しい」:ワード「欲しい」(id=”2″ lex=”欲しい”)
と、定義します。ルールを記入し、「OK」ボタンを押下します。

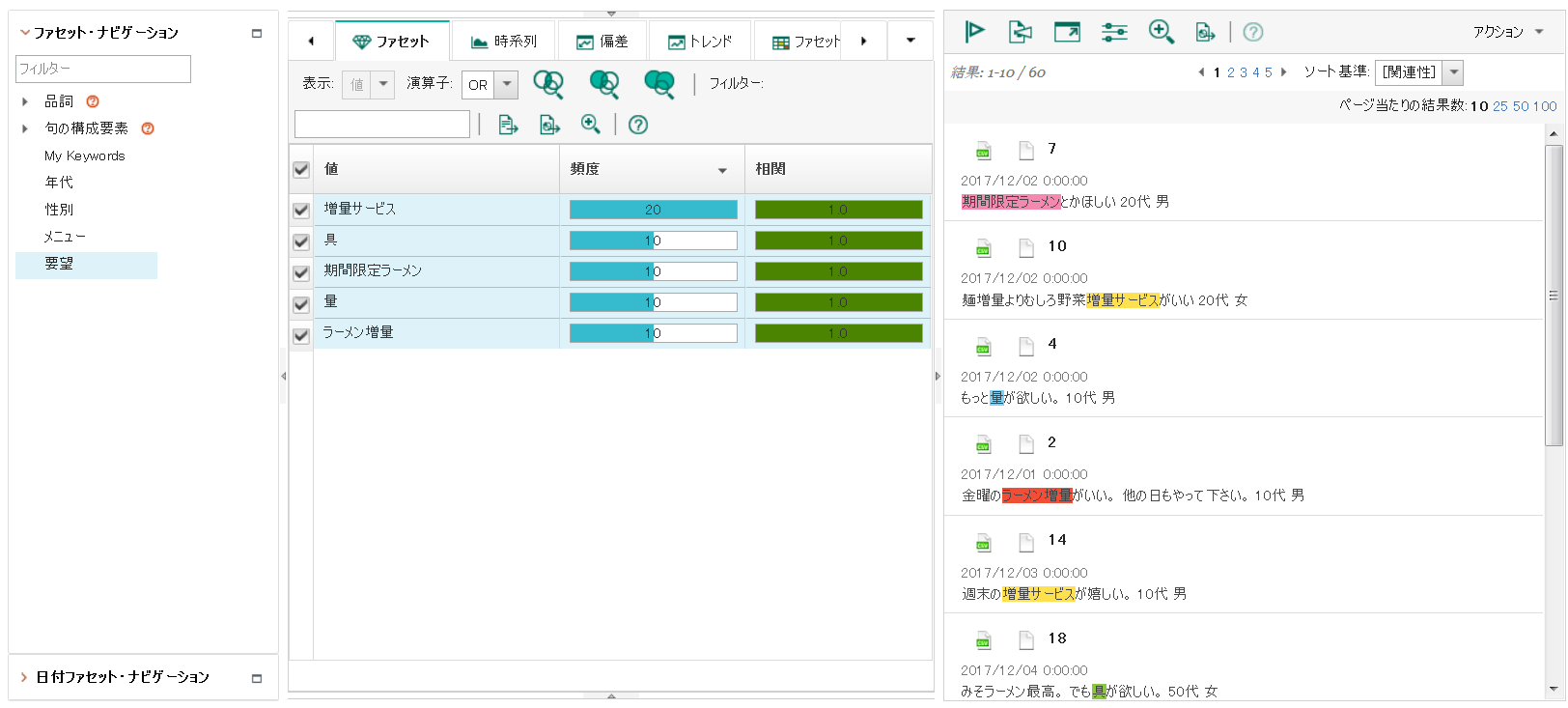
分析リソースのデプロイ、索引の作成を行い、終了後にコンテンツ分析マイナーで確認します。「●●が欲しい」の「●●」が「要望」ファセットに表示されるようになりました。
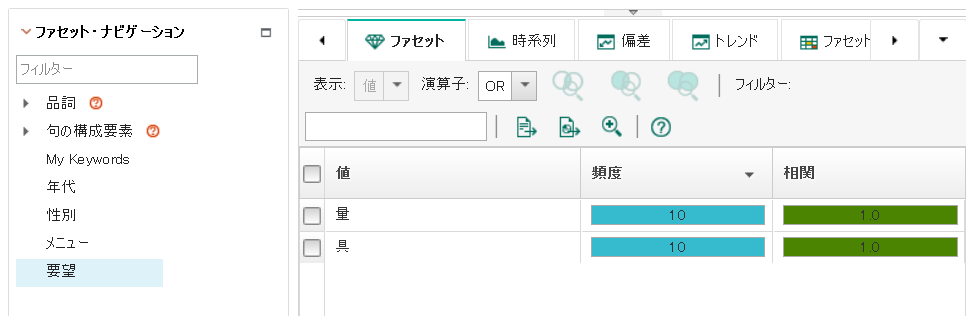
ですが、このままでは「●●が欲しい」という文章の「●●」しか取れません。文章を見ると、「●●がほしい」「●●とか欲しい」など、「欲しい」という文章だけでもパターンが色々あるようです。

取れる文章のパターンを増やせるよう、ルールを追加します。複合名詞、助詞、形容詞のパターンを増やしてみます。

分析リソースのデプロイ、索引の作成を行い、終了後にコンテンツ分析マイナーで確認します。要望と思われるワードが先程よりも多く抽出できるようになりました。
今回は更なるコレクションの作り込み方法のひとつとして、カスタム・テキストルール分析設定を簡単に取り上げてみました。WEXACには他にも様々な機能がありますので、機会がありましたら是非色々とお試しいただければと思います。

執筆者プロフィール

- tdi AI・コグニティブ推進部
- 主にIBM Watson Explorer Analytical Components関連業務に携わっています。面白そうなものには取り敢えず着手してみる主義。現在はkaggleに挑戦中。




