
IBM Watson Explorer Analytical Components(以下、WEXAC)は、Watsonソリューションの基盤として位置付けられ、文章やDB、WEBなどに含まれる構造化および非構造化コンテンツを収集・分析し、その中に含まれる知見や問題点を発見することができる強力なテキストマイニングツールです。
WEXACでは、コレクションと呼ばれる一回の照会で検索・分析可能なデータの集合を作成し、その中に様々なコンテンツを入れてテキストマイニングを行います。今回は、アンケートを活用したいラーメン屋さんがWEXACを使ってみるケースを想定して、簡単なコレクションを作成してみたいと思います。(この想定はフィクションであり、実在の人物や団体などとは一切関係ありません)
今回の想定
とあるラーメン屋を営むAさんは、今後の経営に役立てるため、お客様に対してアンケートを実施することにしました。アンケート項目として「記入日」「年代」「性別」「ご意見」を設定し、その結果からお客様のニーズを知りたいと考えています。
分析コレクション作成
まず、WEXACの分析コレクションを作成します。
管理コンソールを起動し、「コレクション」ビューの「コレクションの作成」ボタンを押下。

コレクションの作成フォームで下記の通りに設定し、分析コレクションを作成します。
| 設定項目 | 設定内容 |
|---|---|
| コレクション名 | Sample_1 |
| コレクション・タイプ | コンテンツ分析コレクション |
| コレクションID | カスタムのID(Sample_1) |
| 使用する言語の制限 | 日本語 |
空の分析コレクションが作成されました。
CSVデータインポート
次に、CSV形式で用意したアンケートデータをコレクションにインポートします。
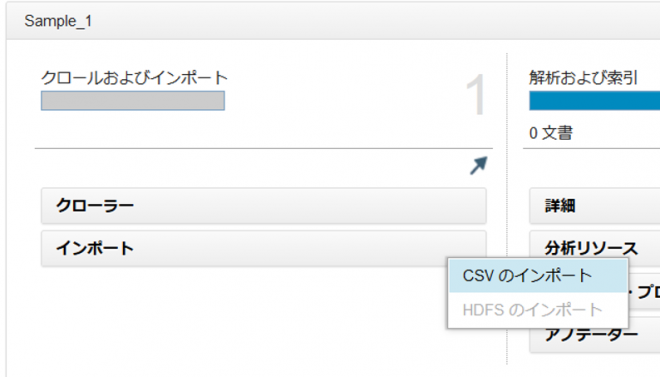
「クロールおよびインポート」ペインの「インポート」>「CSVのインポート」を選択。
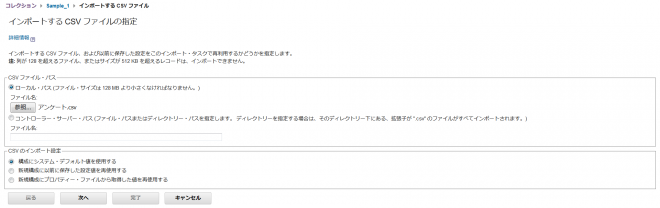
「CSVファイル・パス」でアンケートデータファイルを指定し、「次へ」ボタンを押下。
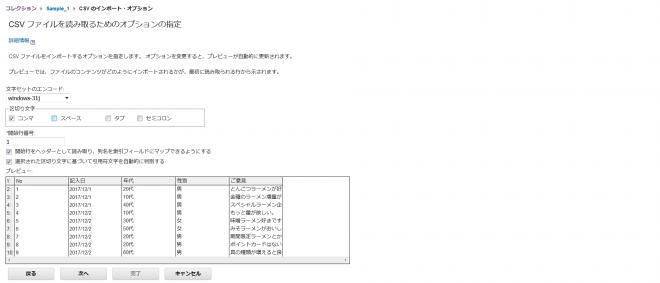
今回のデータファイルは開始行がヘッダーとなっているため、「開始行をヘッダーとして読み取り、列名を索引フィールドにマップできるようにする」をチェックし、「次へ」ボタンを押下。
「新しい索引フィールドを列名から作成する」ボタンを押下し、CSVの列名を基に新しい索引フィールドを作成。
下記の通りに設定します。
| 列 | 索引フィールド設定内容 |
|---|---|
| No | 索引フィールド「title」を指定 |
| 記入日 | 索引フィールド「date」を指定 |
| 年代 | 「戻り可能」「ファセット検索」「フリー・テキスト検索」「サマリーに含める」にチェック |
| 性別 | 「戻り可能」「ファセット検索」「フリー・テキスト検索」「サマリーに含める」にチェック |
| ご意見 | 索引フィールド「body」を指定 |
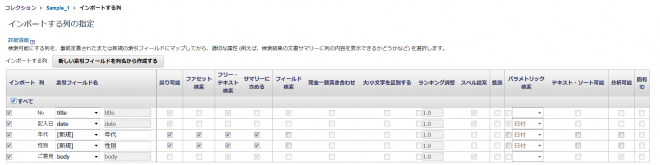
文章日付として「記入日」を使用するため、拡張オプションも設定。
| 設定項目 | 設定内容 |
|---|---|
| 文章日付として使用する列 | 「記入日」を指定 |
| 日付形式 | yyyy/M/d |

今後インポートする時のために、現行設定を保存。「完了」ボタンを押下すると、インポート処理を開始します。

インポート、解析および索引処理の終了後にコンテンツ分析マイナーを起動し、作成した分析コレクションを確認します。取り込んだ文章が解析され、品詞単位で分析できるようになりました。
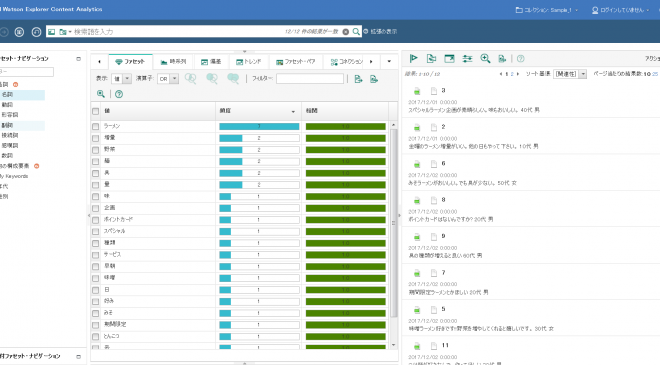
ユーザー辞書設定
「ファセット」ビューで「名詞」ファセットを見てみると、解析された名詞単位の一覧が確認できます。
ですが、デフォルトだと「味噌ラーメン」が「味噌」「ラーメン」と2ワードに分割されたり、「味噌」と「みそ」が別のワードとして解析されたりしています。今回は「味噌ラーメン」としてまとめてしまいたいので、「味噌ラーメン」も「みそラーメン」も、「味噌ラーメン」として解析されるように設定します。
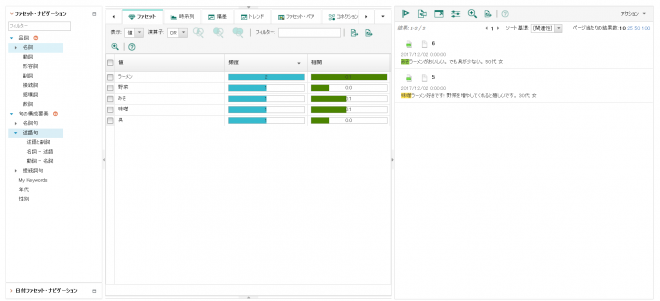
まず、「味噌ラーメン」などメニューの切り口で分析するための「メニュー」ファセットを作成します。
「解析および索引」ペインの「分析リソース」>「ファセット・ツリー」を選択。
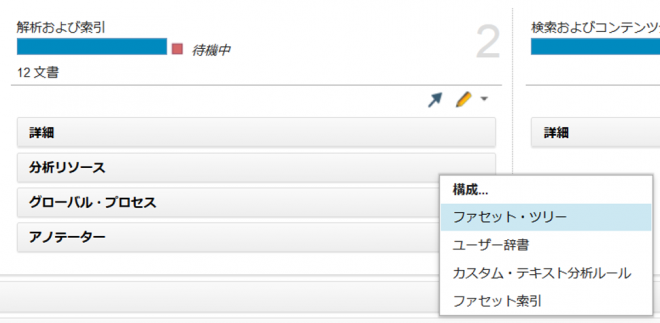
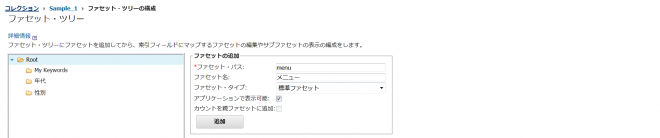
下記の通りに設定します。「追加」ボタンを押下。左のファセット・ツリーに「メニュー」ファセットが追加されたことを確認後、「OK」ボタンを押下します。
| 設定項目 | 設定内容 |
|---|---|
| ファセット・パス | menu |
| ファセット名 | メニュー |
| ファセット・タイプ | 標準ファセット |
次にユーザー辞書を設定します。
「解析および索引」ペインの「分析リソース」>「ユーザー辞書」を選択。
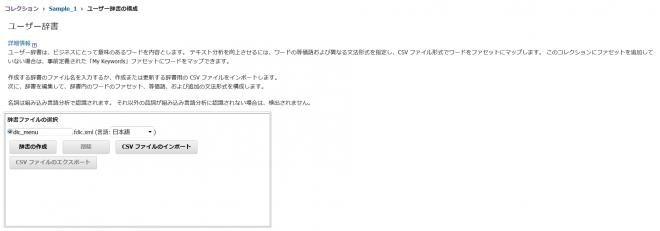
辞書ファイル名(今回は「dic_menu」とします)を入力し、「辞書の作成」ボタンを押下。
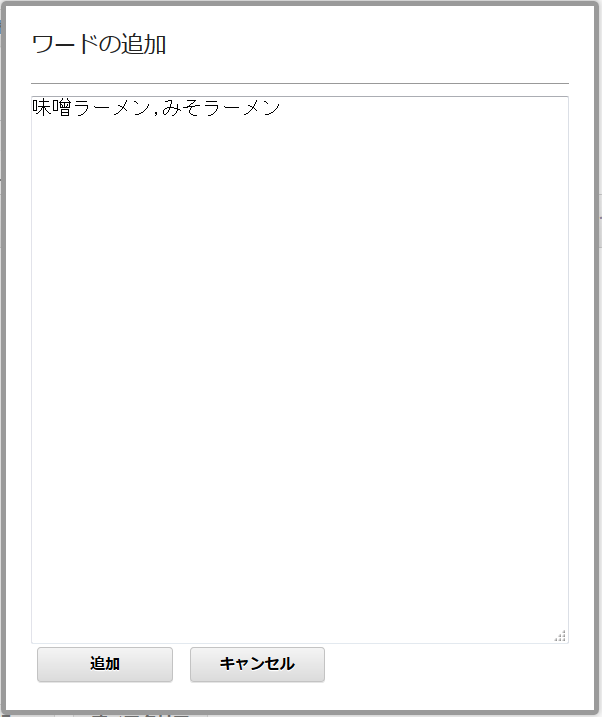
「ワードの追加」ボタンを押下し、表示されたフォームにワードを入力します。
等価語はワードの後に「,」区切りで入力します。今回は「味噌ラーメン,みそラーメン」と入力し、「追加」ボタンを押下。
「適用済みワード」の「味噌ラーメン」の行で「選択」をチェックします。「ファセット・ツリー」の「メニュー」ファセットを選択し、「>>」ボタンを押下。
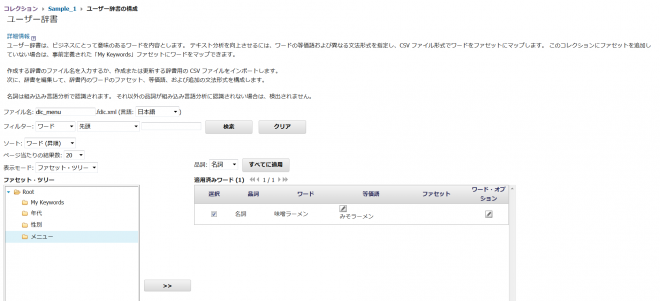
「ファセット」に「メニュー」が表示されたことを確認します。「OK」ボタンを押下。
編集したユーザー辞書をコレクションに適用するため、「解析および索引」ペインの「分析リソース」>「分析リソースのデプロイ」の「▲」を押下し、デプロイを行います。

「分析リソースのデプロイ」が終了したことを確認後、インポート済のデータの索引を再作成します。「解析および索引」ペインの「索引の再作成」の「▲」を押下。
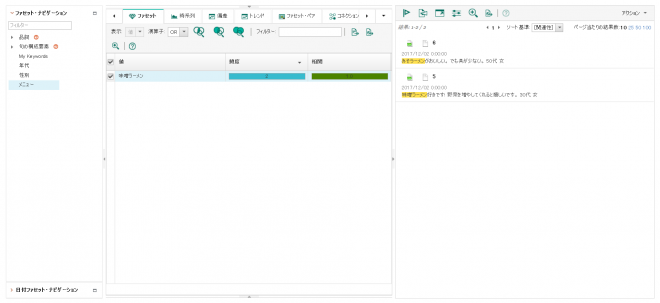
索引の再作成処理の終了後にコンテンツ分析マイナーを確認します。「味噌ラーメン」がまとめて解析できるようになりました。
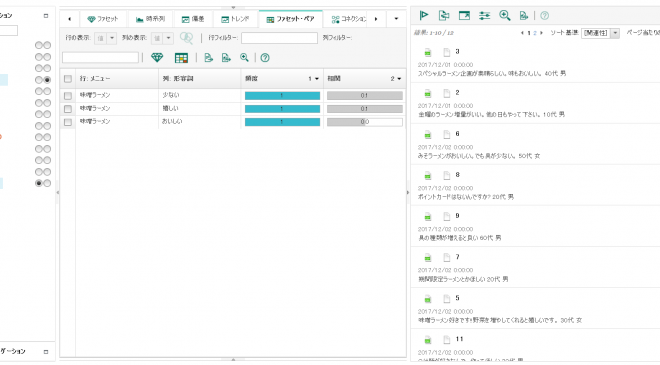
このように目的に合わせてコレクション作成を進めていくことで、WEXACは細やかな分析ができるように成長していきます。今回は簡単なコレクションの作成方法ということで、ここまでとさせていただきますが、この後には、更なるコレクションの作り込み、それを用いたテキストマイニングによる洞察・知見(今回の想定で言うと、お客様のニーズ)の引き出し、と続いていく流れとなります。これらについては、次の機会に記事に取り上げられればと思います。
WEXACは、手を掛ければ掛けるほど応えてくれるようになりますので、機会がありましたら是非じっくりと育ててみてください。
なお、当社はWEXACの環境をクラウドで提供する「おてがるデータ分析環境サービス」を取り扱っています。ご興味ございましたら、こちらのWebフォームよりお問い合わせください。

執筆者プロフィール

- tdi AI・コグニティブ推進部
- 主にIBM Watson Explorer Analytical Components関連業務に携わっています。面白そうなものには取り敢えず着手してみる主義。現在はkaggleに挑戦中。




