
Watson Discoveryという、IBM Cloudが提供しているサービスがあります。これは、構造化・非構造化データを問わず、WORDやPDF、JSONファイルなどのファイルを取り込み、“有用な知見”を抽出してくれるというサービスです。私もWatson Discoveryから知見を抽出してみたい!何コレ知らなかった!と思える結果を得たい。そんな軽い気持ちから、検証してみました。
知見を得るデータを決定
今回は、Watson Discoveryからとにかく知見を抽出したいというのがきっかけのため、Watson Discoveryの対象データは何でも良かったのですが、導入するデータはAIっぽく非構造化データを使用したいと思いました。そのため、まずは何かまとまったテーマの「文章」を一定数集めようと考え、手軽に一定数のデータを集められるものをいくつか検討してみました。
- 裁判の判例 ⇒ 専門用語が多いから、トレーニングが難しそう。(という建前で、読むのが苦痛。)
- 新聞記事 ⇒ すでにWatson Discovery Newsというサービスが、IBMから提供済み。
- 短歌や俳句 ⇒ お手軽すぎる?(そもそも五・七・五はある意味、構造化データなのかもしれない)
- 日本昔話 ⇒ 判例ほど難しくなさそうで、検証にはお手ごろそう・・・ 採用!
という流れで記事のタイトルにあるとおり、今回は日本昔話からWatson Discoveryの検証を行ってみることにしました。
Watson Knowledge Studioにデータを登録・アノテーション実施
Watson DiscoveryとWatson Knowledge Studio(以下、WKS)はデータ連携をすることができます。WKSでアノテーション(※)を行い、そこで作成された学習モデルをWatson Discoveryに流用することで、自由なタグ付けが可能となります。今回はこのWKSを使用してWatson Discoveryと連携させます。
※アノテーション ⇒ 文章に注釈付けを行うこと。
WKSの作成はCreate Workspaceをクリックし、ドキュメントの言語指定は「日本語」を選択します。
次にEntity Typeを作成。これを設定することでWatson Discoveryではタグの一つとして抽出することが可能になります。ただし、今回はアノテーション作業に使える時間はあまり取れそうになかったので、できるだけEntity Typeは少なめにして、こんな感じで設定してみました。
| No | Entity Type | 想定するワード |
| 1 | job | 猟師、侍、商人など、仕事を表す単語 |
| 2 | place | 山、海、あるいは土地や地域などを表す単語 |
| 3 | character | かわいい、意地の悪い、汚いなど、人・モノに対する性質を表す単語 |
| 4 | person | おじいさん、おばあさん、あるいは太郎、次郎など、人を表す単語 |
| 5 | animal | サル、カメ、スズメなど、動物を表す単語 |
| 6 | behavior | イタズラをする、助けた、運んだなど、人や動物が行う仕草・行動を表す単語 |
| 7 | item | 玉手箱、おにぎり、お金、ふんどしなど、上記以外に入らない目的語となる単語 |
これに紐づくかたちで、Relation Typeも設定しましたが、ここでは一旦割愛します。Relation Typeでは、上記で設定したEntity Type同士を紐付け、それらはどんな関係性を示すものか、を定義します。たとえば「おじいさん」と「おばあさん」を紐付けて、この2人は「家族」であるという関係性を定義できます。
これらのEntity Type、Relation Typeを設定した後に、私の怒涛のアノテーション作業が始まります。
・・・・・・が、すぐに悩ましい問題に直面します。
- おじいさんは山へ「柴刈り」へ行くが、それは果たして「job」なのか「behavior」なのか
- 長者や和尚が、物語で活躍をしても、彼らは「person」ではなく「job」に分類されるというジレンマ
- 天狗、神様、オニ、竜などの魑魅魍魎。仕方ないので「animal」に分類・・・後に観音様も「item」から「animal」へ昇格
- 「鬼退治」は、1つの「behavior」とすべきか、「鬼」と「退治」を分けて、定義すべきか
- 親切を受けたお金持ちの「娘を嫁に」という「behavior」の横行
アノテーションを実際に始めると、Entityにもっと項目が欲しい、どこに分類したらいいか分からないといった状況が、頻繁に発生します。業務でアノテーションを実施する際には、複数の担当者で対応するため、各アノテーターが「共通の定義」を共有する仕組みが必要だと感じました。1つの文章は600文字程度なのですが、1話あたり5分~10分程度、計2時間以上かけて、30話分の昔話のアノテーション作業が完了です。
イメージはこんな感じ・・・
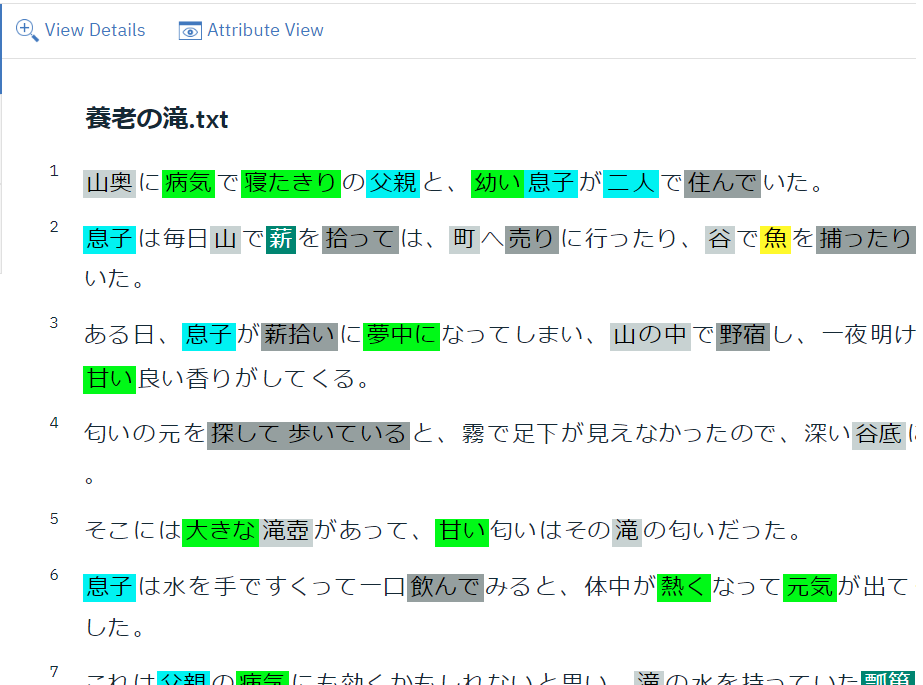
実際にやってみて思ったことは、お試しの対象を「判例」にしなくて本当に良かったということ。判例の場合、20ページ以上に渡る超大作も珍しくないため、間違いなく私の心は折れていたと思います。たとえ短い文章であっても、一貫した定義づけが行えているのかは自信がありませんでした。アノテーションを業務で行う場合、高品質なモデルを作成するには、複数人、複数回のレビューを経て作成することをおすすめします。
WKSではアノテーション実施後、いくつかのボタンをクリックするだけで、簡単に分析モデルの生成と精度を抽出してくれます。
気になる結果がこちらです。
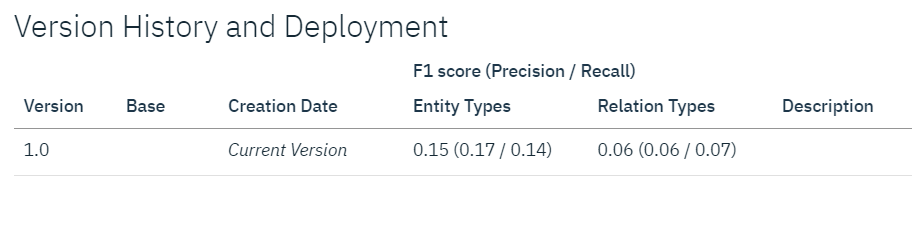
F1 scoreと呼ばれるものが精度を図る指標になり、1に近づくほど精度は上がるのですが・・・言葉も出ません。Relation Typesにいたっては0.1もありません。あの何時間もの作業は何だったんだろう。時間的にも体力的にも余裕はありませんでしたが、あと30件ほどのアノテーションデータを作成して投入します。ここまでのアノテーション作業に6時間以上かかっています。
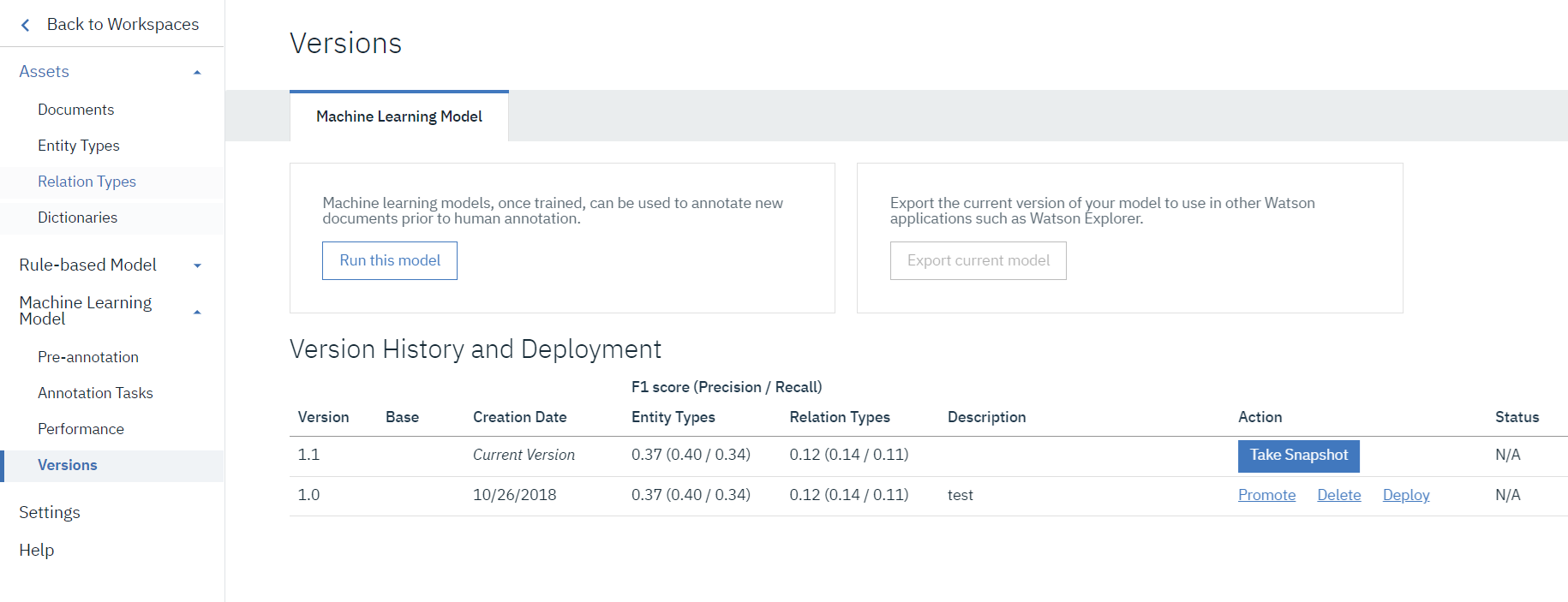
先ほどの結果のほぼ倍、0.37まで向上しました。アノテーションの正確さにもよりますが、7割程度のスコアを出そうと思えば、あと60件、全部で120件くらいは必要そうな感じです。ここでこれ以上の精度をあげることをあきらめ、上記画面からWatson DiscoveryへのDeployを実施します。
この際にModel IDというものが発行されるため、忘れないようにメモします。Watson Discoveryでの作業時に必要になります。
Watson Discoveryに作成したモデルを適用
ここまでにかかった時間は、すでに私の想定を超えていましたが、まだまだ作業は途中です。ここからはWatson Discovery側の対応になります。まずは通常通り新しいcollectionをWatson Discoveryに作成します。そのあとに、ConfigurationからEditを選択します。
※下の画像では、Document countが110となっていますが、作成時は本来0です。
その後、Add Enrichmentsをクリックすると以下の画面になります。ここでEntity Extractionを選択して、Custom Model IDを入力します。先ほどWKSのモデル作成時にメモした内容です。
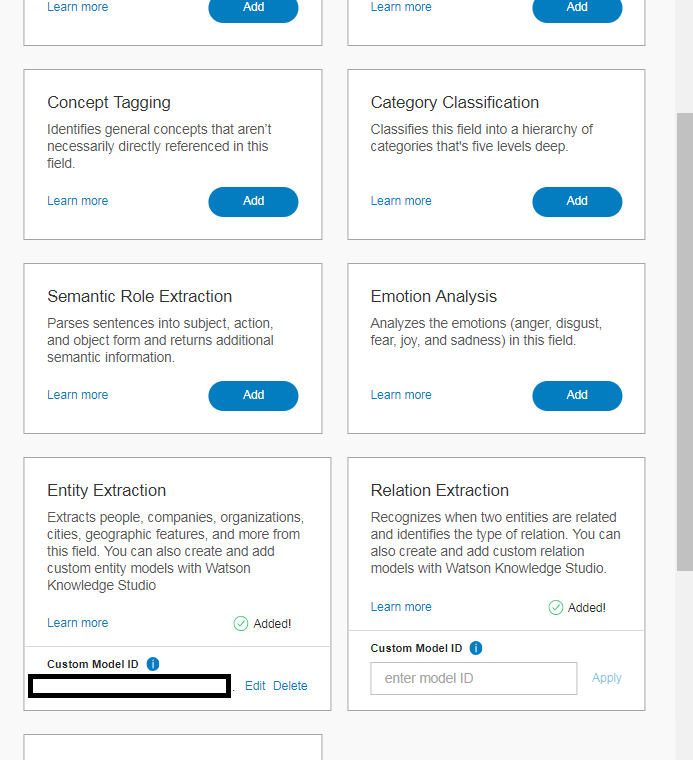
上記作業で、モデルの適用は終了。とても簡単にオリジナルの分析モデルが作成できます!
あとはデータの投入ですが、Watson Discoveryには少し使いづらいところがあり、txtファイルは投入することができず、PDF、WORD、JSON、HTMLのいずれかのファイル形式での投入になります。今回は110件の日本昔話データをかき集め、それを投入します。
本来であれば、Relation Typeの精度をもっと上げて、動物達はどんな行動をよくしているか、おじいさんとおばあさんではどちらが優しいかといった分析結果を期待していました。しかし今回はモデルの絶対数が足りず精度がよくないため、Relation Typeの分析はあきらめ、Entity Typeでよくでる単語を確認することにした。
| No | Entity Type | 日本昔話からの頻出ワード(頻出順) |
| 1 | job | 飛脚、先生、山伏、百姓、商人 |
| 2 | place | 村、家、山、地蔵、田んぼ |
| 3 | character | 大きな、小さな、不思議な、幸せに、美しい |
| 4 | person | 爺さん、娘、お婆さん、母親、男の子 |
| 5 | animal | 天狗、鬼、化け物、狼、サル |
| 6 | behavior | 相撲、住んで、退治、暮らした、帰って |
| 7 | item | 餅、小判、石、ぼた餅、お金 |
精度が十分なモデルではなかったですが、ある程度の確認は行えたと感じます。少し分析データに偏りがあると思いますし、地蔵がplaceに分類されていることや、餅とぼた餅、小判とお金が別に分類されて出力されていることなど、もう一歩な部分は多いです。しかし、ここまでの流れでWKSからWatson Discoveryを利用した分析について、概要はつかむことができました。
まとめ
WKSによるオリジナルのタグ付けを行えば、当初の目的であった“有用な知見”を抽出することが可能でした。WKSを使わなくてもWatson Discovery自身が、ある程度のタグ付けは行ってくれるので、WKSの使用判断は目的に応じて、使いわけてください。この分析を通して気が付いた点は以下の通りです。
- WKSのアノテーションのTypeの設定については、最初の定義時に十分検討する。
- 業務でアノテーションを行う場合、費用対効果を考えて、アノテーションの対象を選定。(なるべく短く、有意義なデータの集まり)
- Watson Discoveryは「タグ付け」という切り口から、検索結果を得ることで色々な知見を得ることができそう。

執筆者プロフィール

- tdi AI・コグニティブ推進部
-
データセンター業務を経験した後、Watsonを使用したChatBotの保守を担当。
サービスデリバリ、サービスサポートのプロセス改善を実施してきました。
日々、スキルアップに向け勉強中。




