
目次
はじめに
IBM CloudのWatson Machine Learningを利用して、予測モデルをAPIとしてアプリから利用してみたので簡単に手順を紹介させていただきます。
予測モデル概要
今回作成したのは、年齢、教育年数、資産売却益、資産売却損、週の平均労働時間、結婚状態を入力し、その人の年収が50,000$を超えるか否かを予測するモデルです。予測モデルの作成に使うトレーニングデータについては、UCI machine learning repositoryで公開されている、国勢調査データを利用しました。
作成した予測モデルはこのようになります。
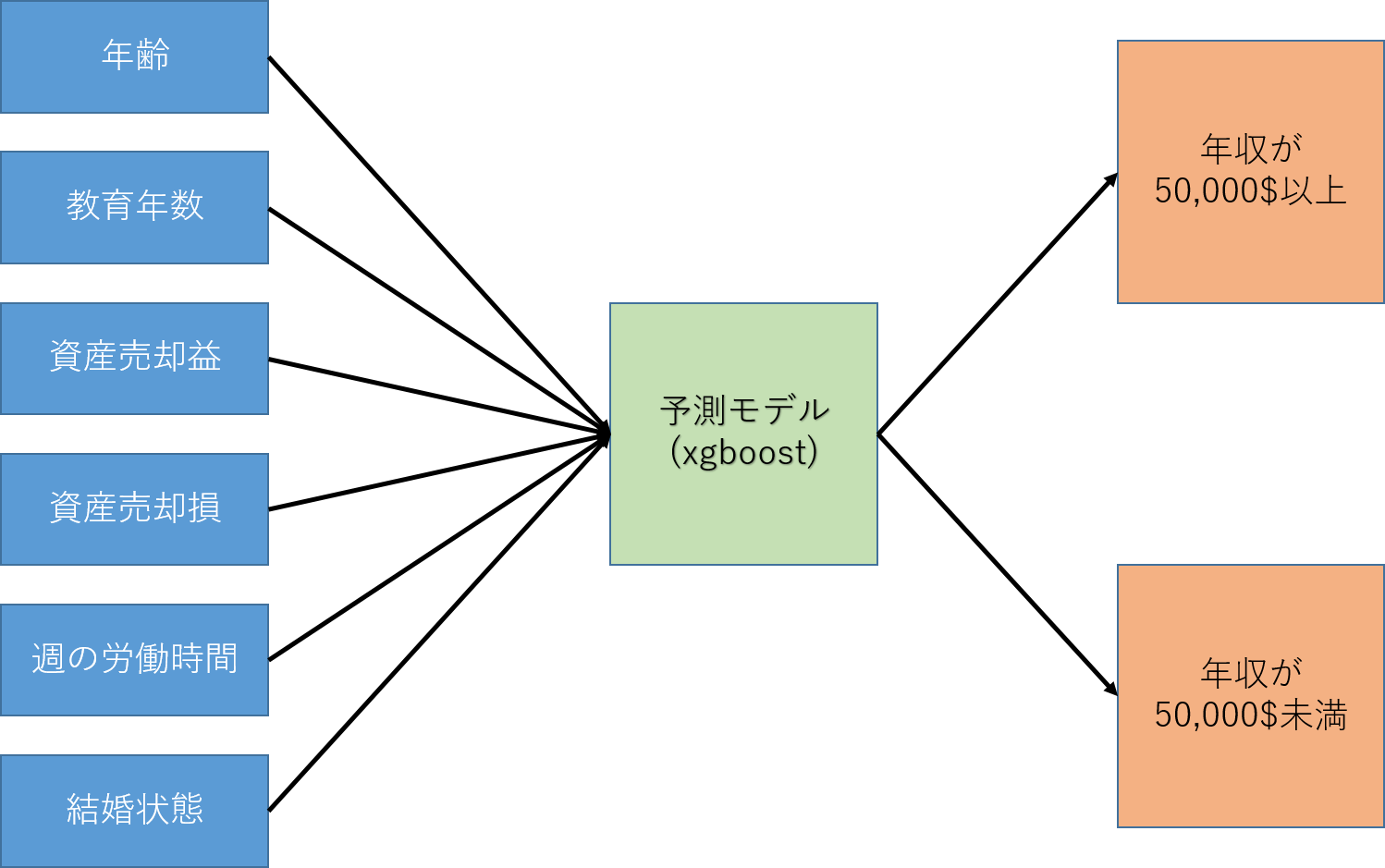
システム概要
全体の流れとしては下の図のようになります。

- トレーニングデータをObject Storageにアップロードする
- Jupyter NoteBookを使い予測モデルを作成する
- 作成した予測モデルをWatson Machine Learningでデプロイする
- Node.jsアプリから予測モデルを利用する
といった順序で解説させていただきます。
※今回1~3については全てIBM Watson Studio上で行っています。
IBM Watson Studioとは
IBM Cloudで提供されている AI活用のための統合開発・分析環境です。
Watson Machine Learningとは
Apache Spark,scikit-learn,XGBoost等様々な手法で構築された予測モデルをデプロイ実行する環境です。
事前準備
- Watson Studio
- Watson Machine Learning
- IBM Cloud Object Storage
のインスタンスを作成します。(今回はすべてライトプランの物を使いました)
Projectの作成
Watson Studioを利用するにあたりインスタンスを作成したら、まずはプロジェクトの作成を行います。
画面中央のCreate a projectをクリックします。
Standardを選択します。
Project Nameを入力し、Storageで事前準備で作成したものが選択されていることを確認したら、Createボタンをクリックし新規Projectを作成します。
データの取り込み
次に、トレーニングに利用するデータをストレージにアップロードします。
画面右上からFind and add dataを選択します。
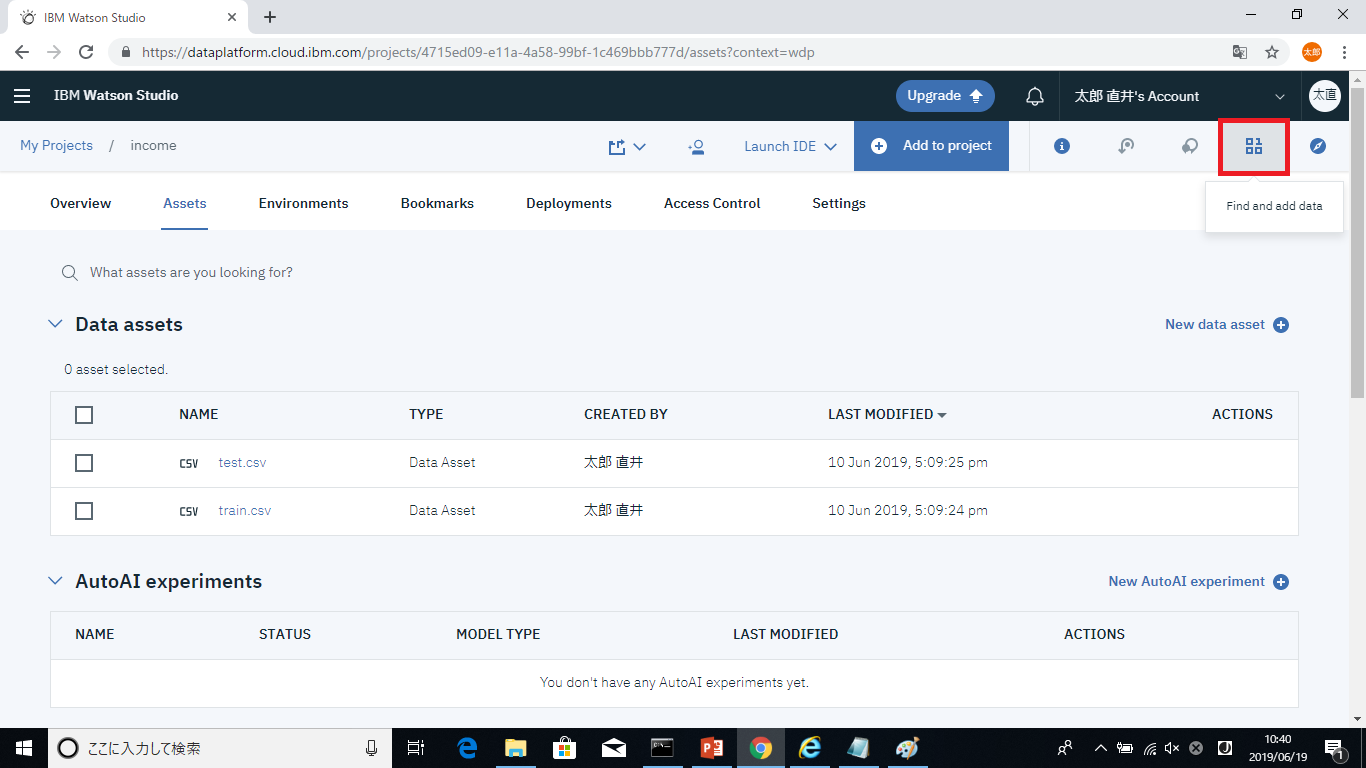
立ち上がった枠にトレーニングデータをドラッグアンドドロップし、データをインポートします。ここで利用したデータは冒頭でも紹介させていただきましたUCI machine learning repositoryで公開されている、国勢調査データです。
予測モデルの作成
トレーニングデータがアップロードできたら次は予測モデルの作成を行います。
まずは、Jupyter NoteBookを起動します。
画面上部のAdd to projectからNotebookを選択します。
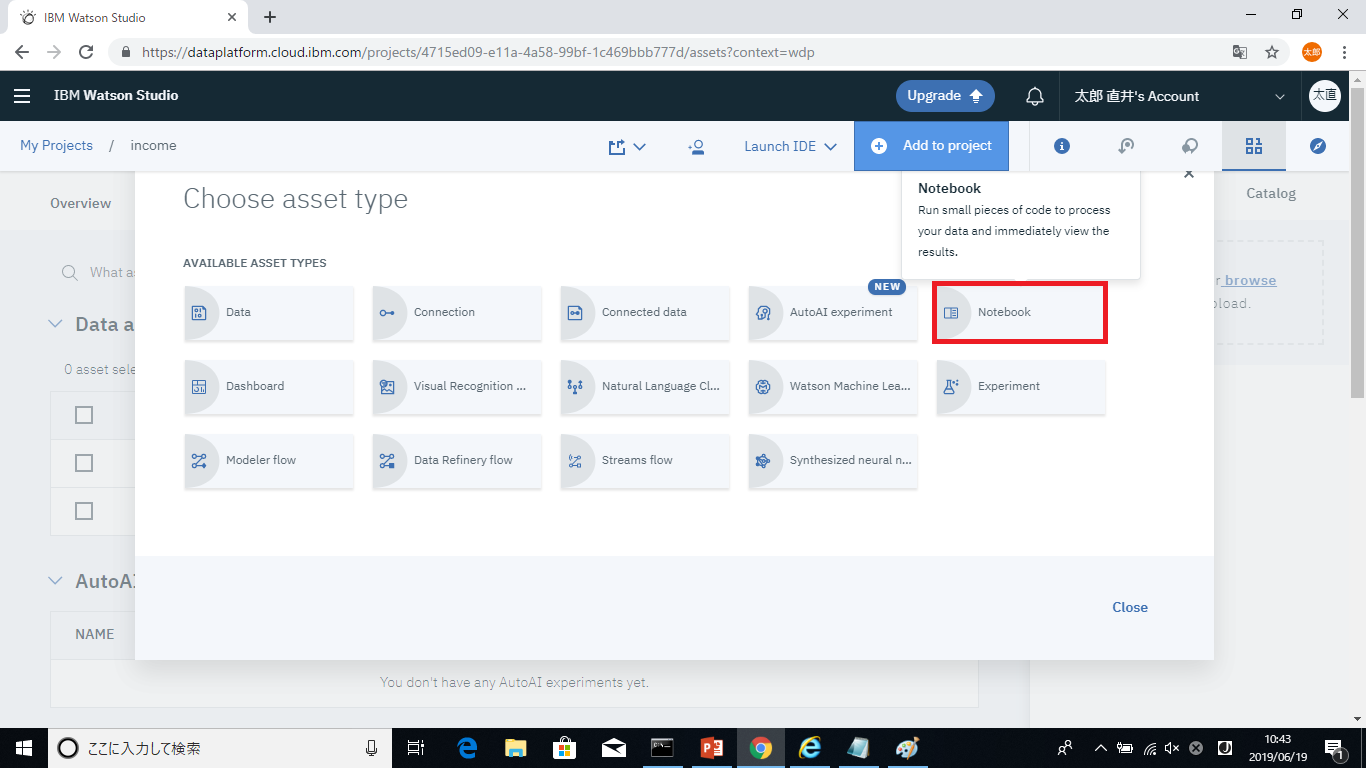
NoteBookが立ち上がったら、まずは先ほどストレージにアップロードしたトレーニングデータをJupyter NoteBookにインポートします。
画面右上からFind and add dataからトレーニングデータを選択しInsert pandas DataFrameをクリックします。
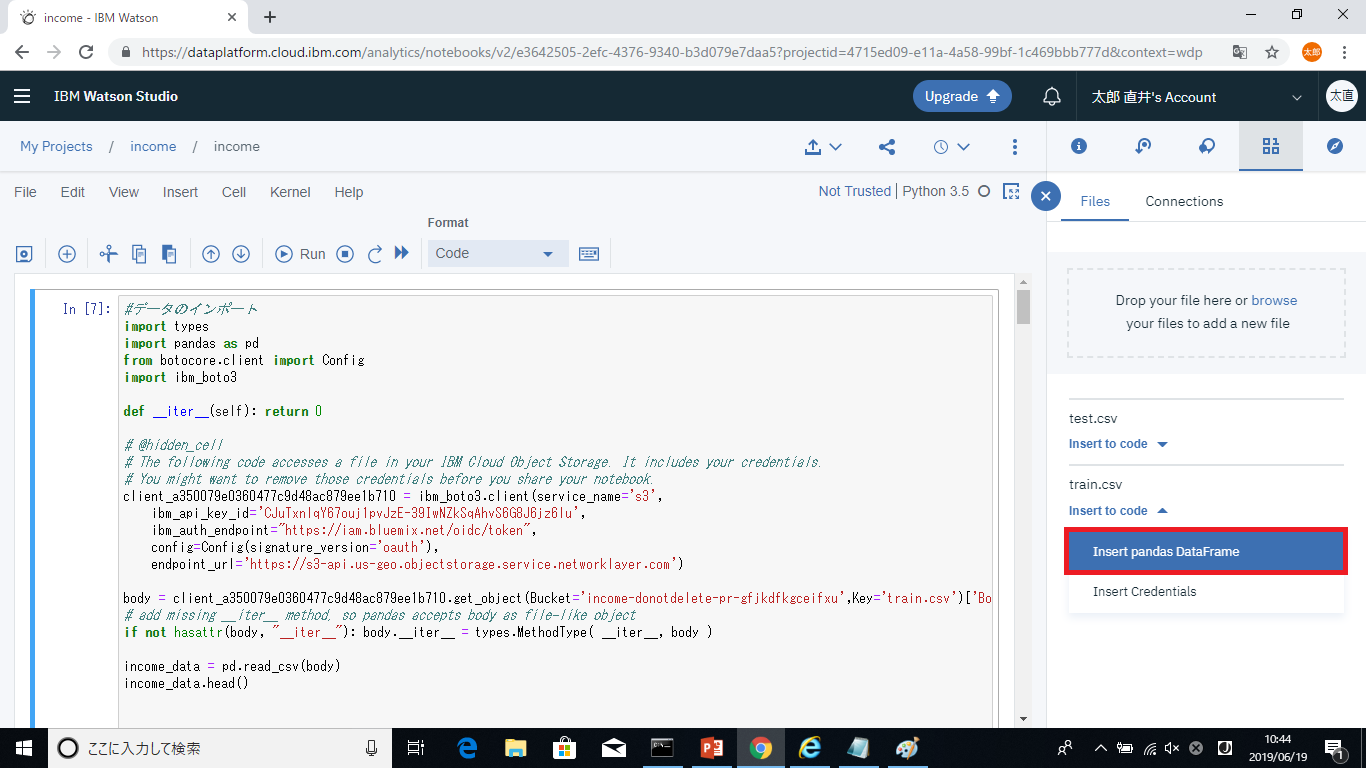
データの分析や前処理、加工を行い、予測モデルのトレーニングを行います。
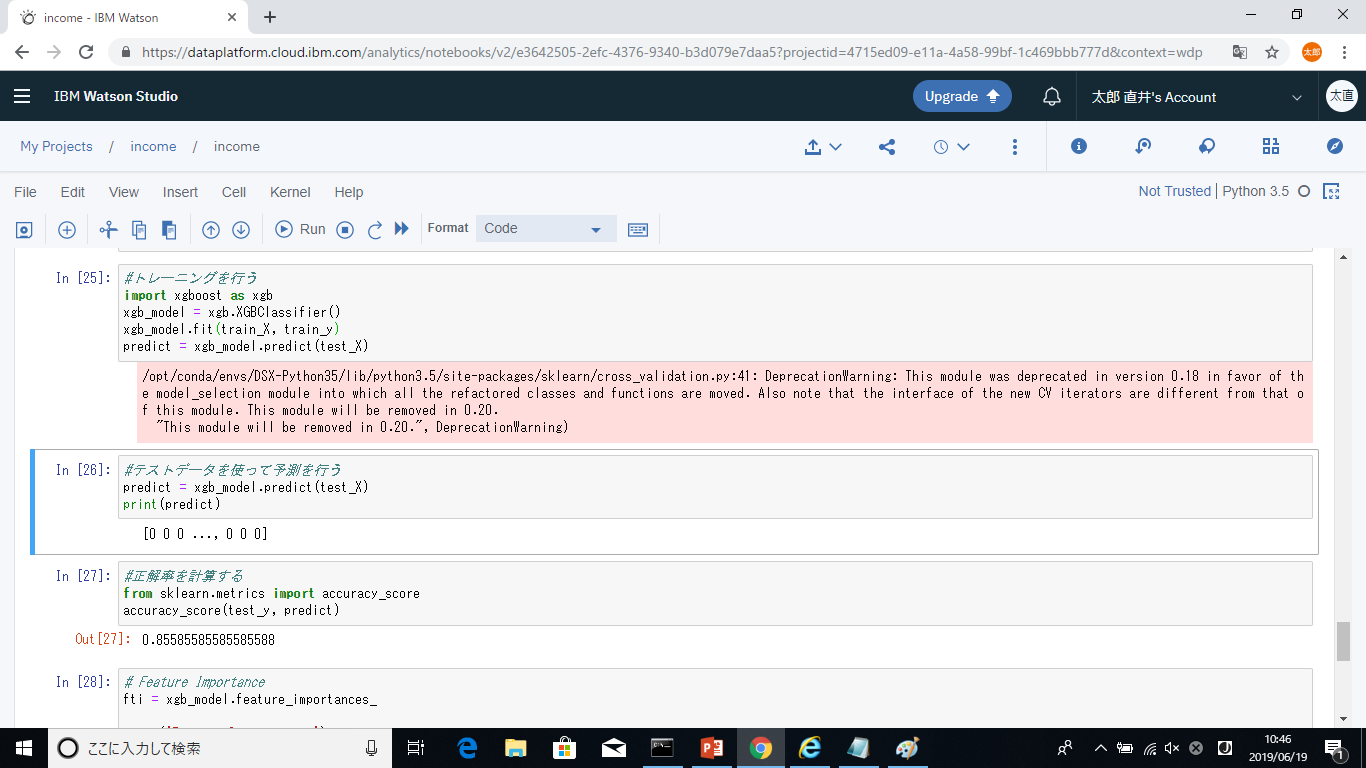
予測モデルをWatson Machine Learningのリポジトリに追加
先程トレーニングを行ったモデルをAPIから利用するためにはWatson Machine Learningでデプロイする必要があります。そこでまずは、作成した予測モデルをWatson Machine Learningのリポジトリに追加します。
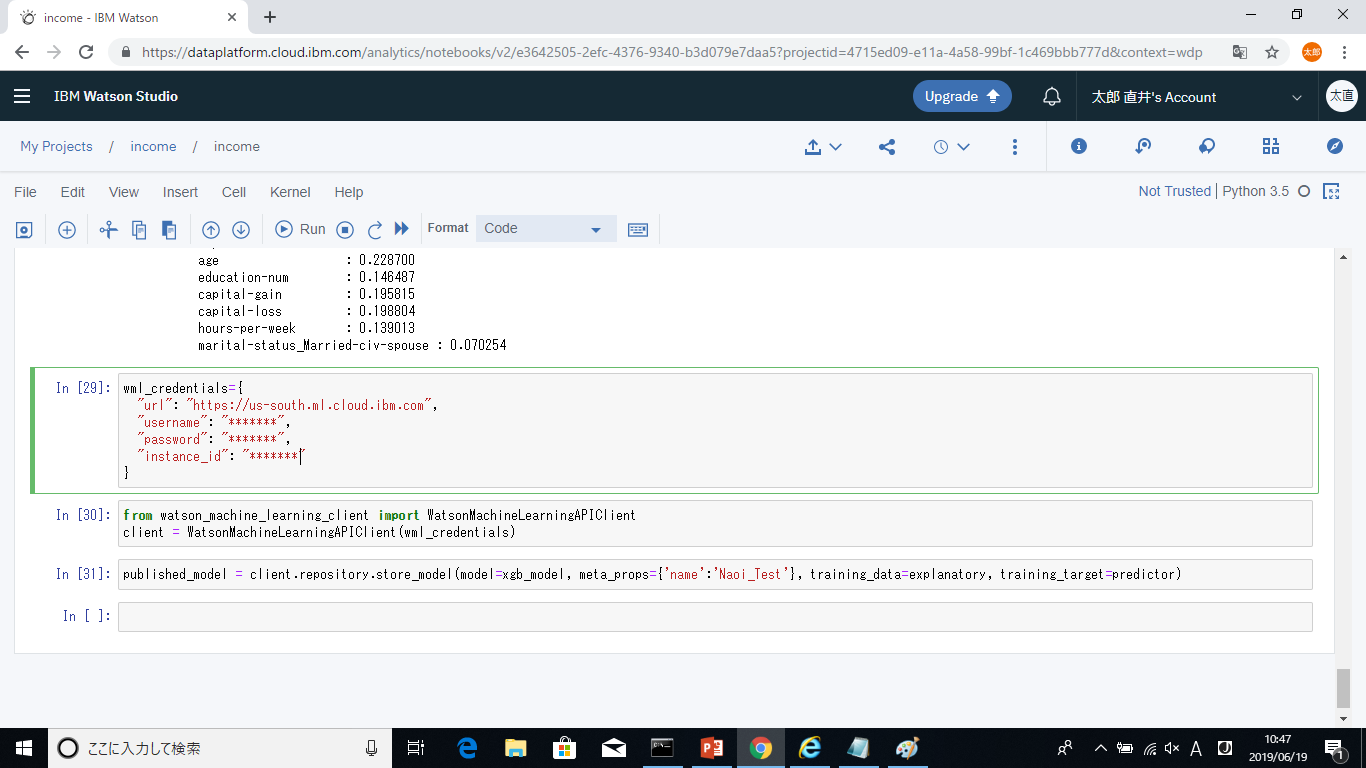
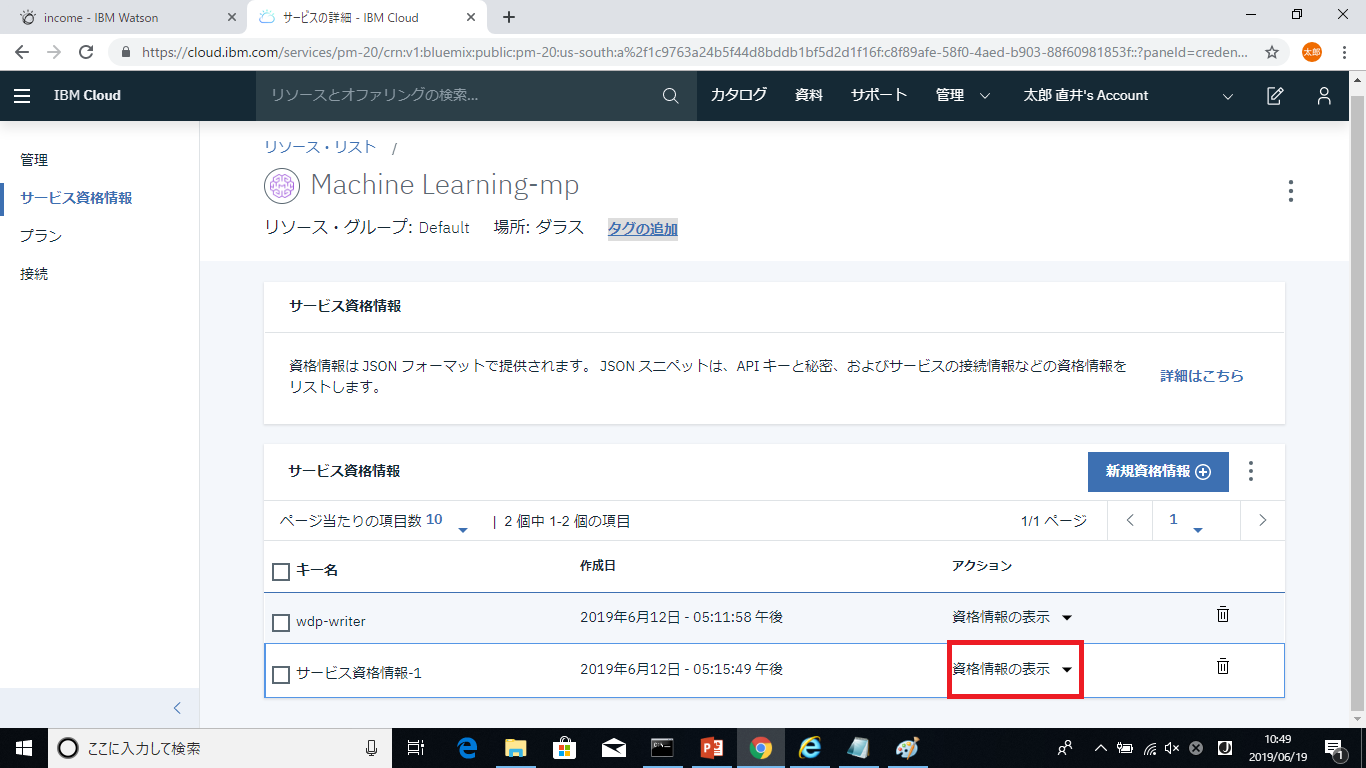
username,password,instance_idについては、ダッシュボードからインスタンスにアクセスし資格情報の表示をクリックすることで確認できます。
予測モデルのデプロイ
次はAPIとして利用するために予測モデルをデプロイします。リポジトリに予測モデルを追加すると、IBM Watson Studio上のModelsの部分から確認ができるようになります。
ACTIONSメニューを開きDeployをクリックすると、予測モデルのデプロイが開始されます。
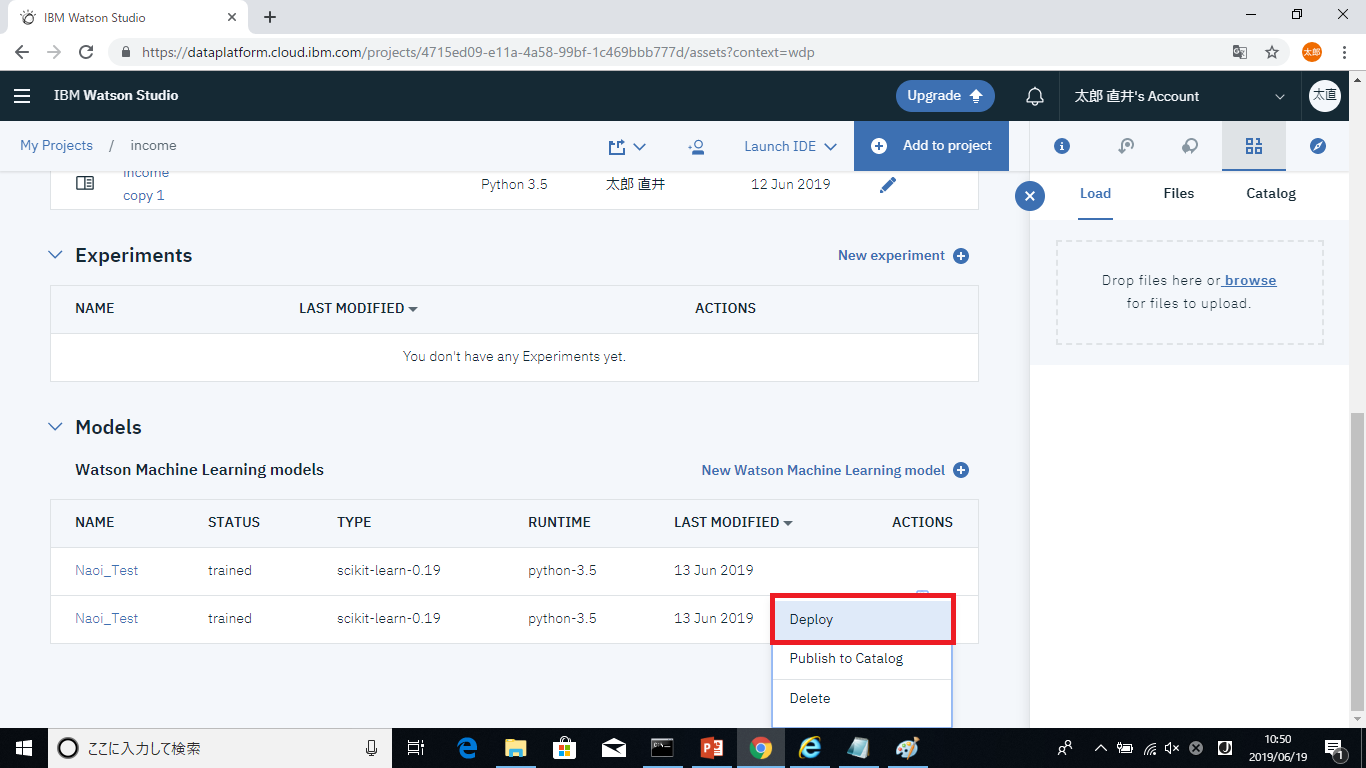
Deploymentsタブを確認し、DEPLOY_SUCCESSとなっていればデプロイが完了されています。
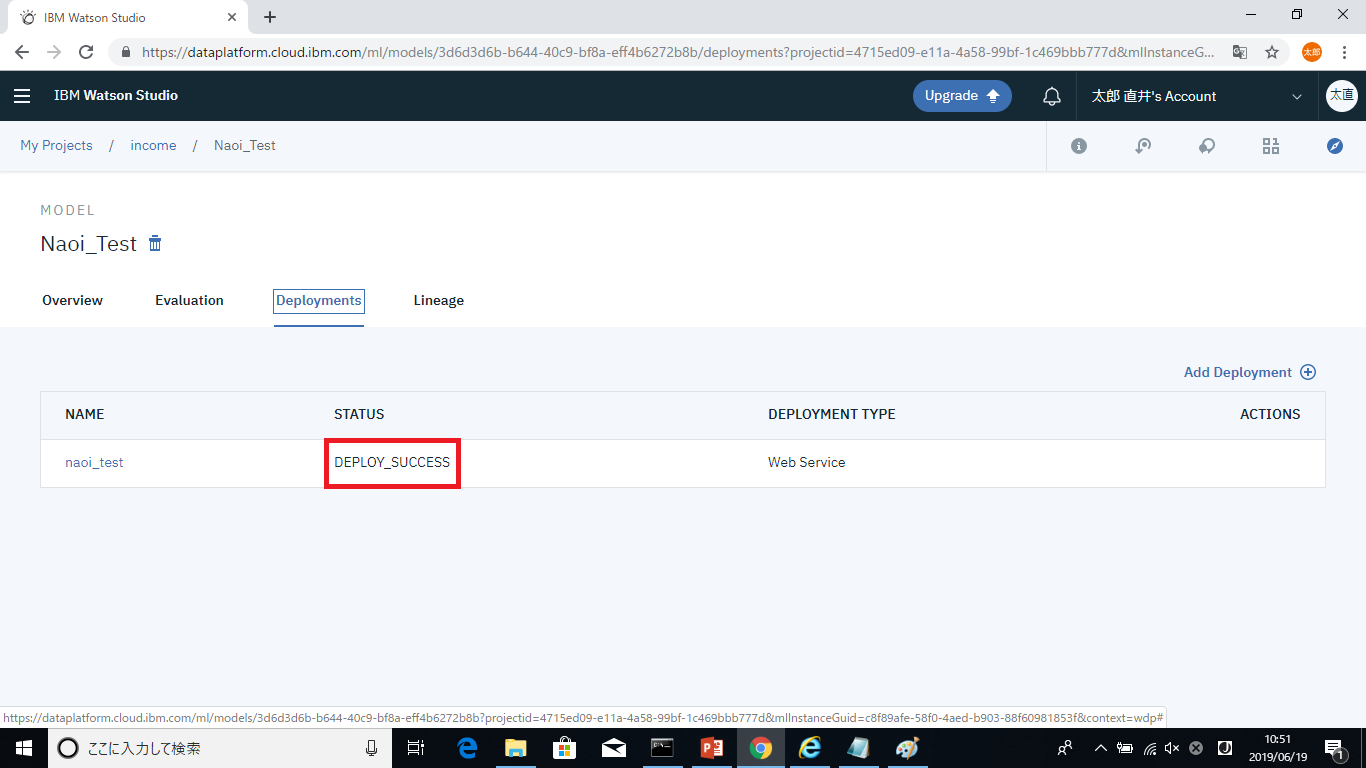
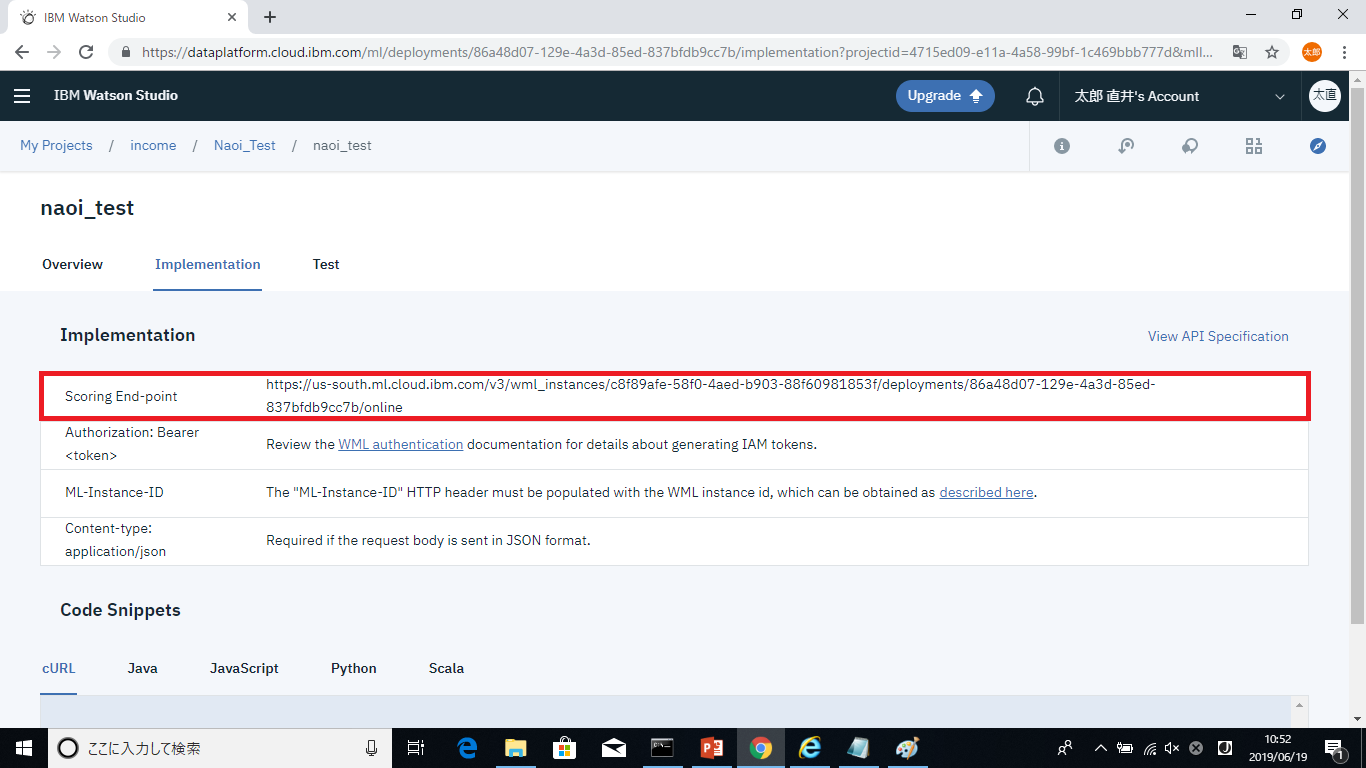
デプロイが完了すると、Webサービスとして利用する際に必要なScoring End-pointが確認できるようになります。このURLが、実際にPOSTを行うURLになります。
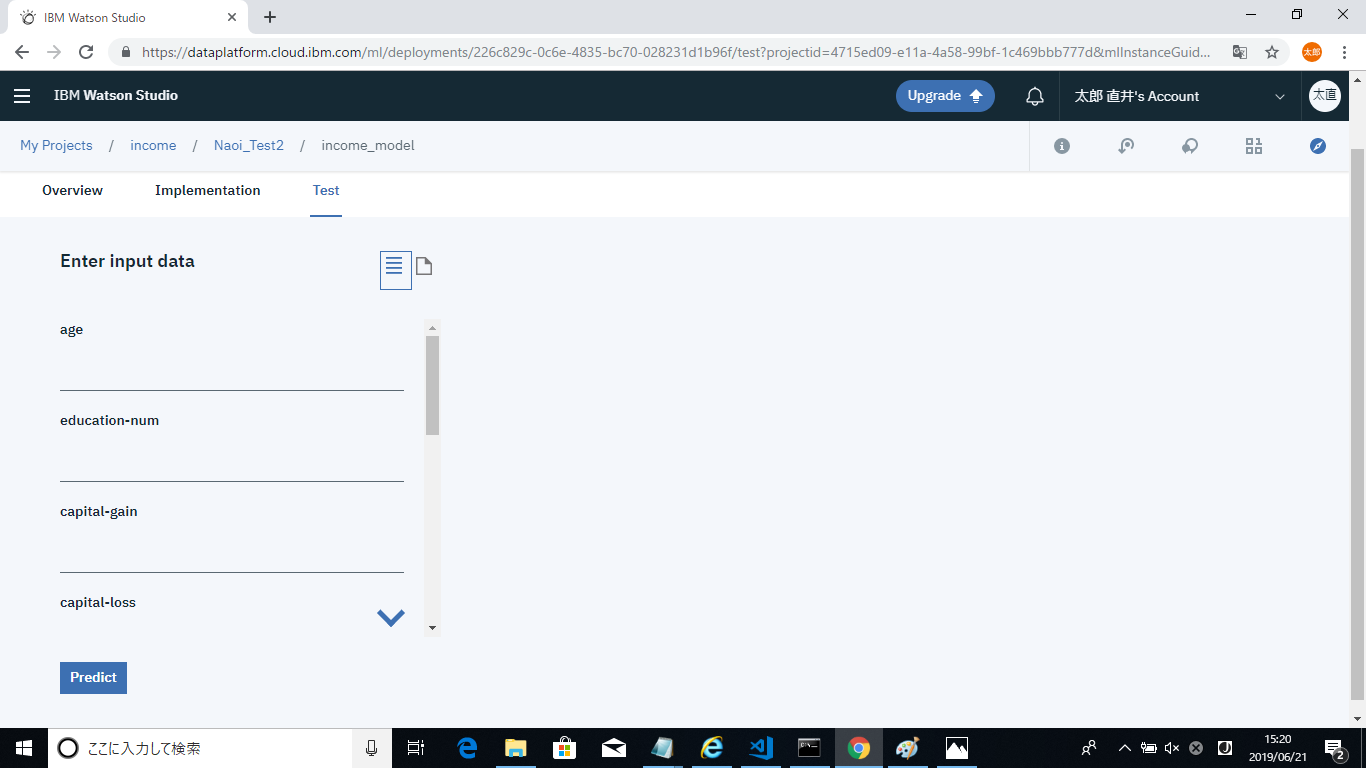
また、Testタブから実際にデプロイしたモデルを試すことができます。入力方法については、フォームから入力をする方法とjsonを送信する方法があります。
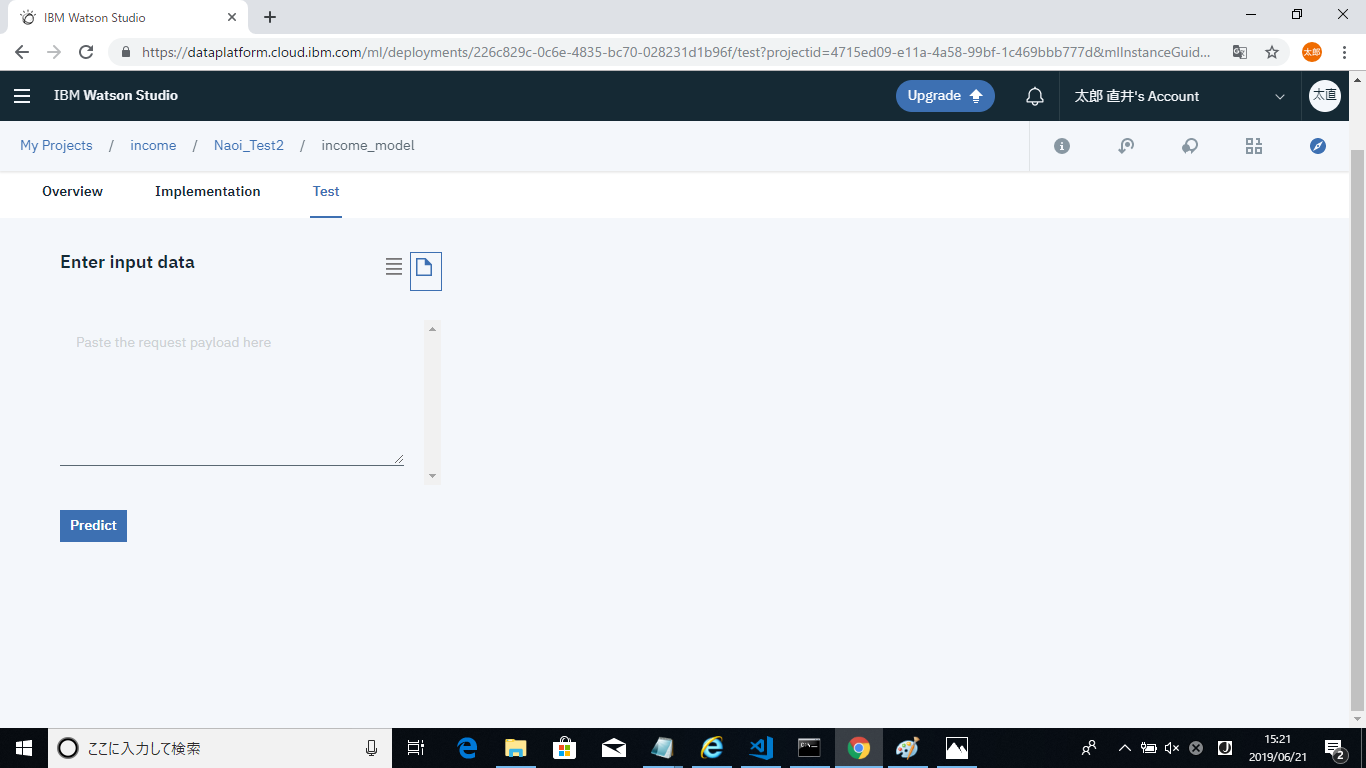
今回はテスト用に用意したjsonを送信してみようと思います。ここでは、
年齢:30歳
教育年数:15年
資産売却益:0
資産売却損:0
週の労働時間:40
結婚状態:既婚者
のデータを送信してみます。こちらが送信したjsonです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "fields": [ "age", "education-num", "capital-gain", "capital-loss", "hours-per-week", "marital-status_Divorced", "marital-status_Married", "marital-status_Never-married", "marital-status_Separated", "marital-status_Widowed" ], "values": [ [ 30, 15, 0, 0, 40, 1, 0, 0, 0, 0 ] ] } |
valuesに入力されている値が、各変数に対する値になります。marital-status(結婚状態)については、カテゴリ変数であるためダミー変数化を行っています。そのため、その状態であるものには1を、そうでないものには0を入力しています。
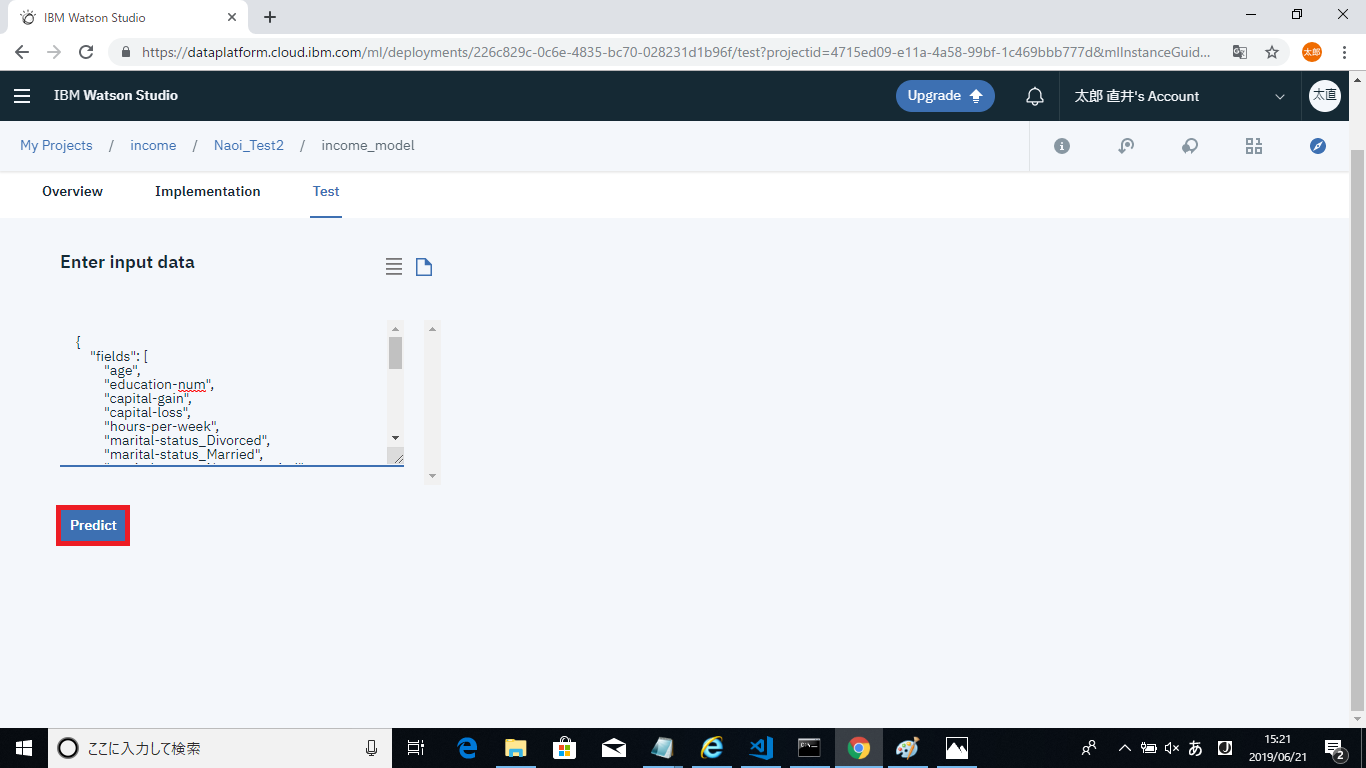
jsonを入力しPredictボタンをクリックすると予測結果が得られます。
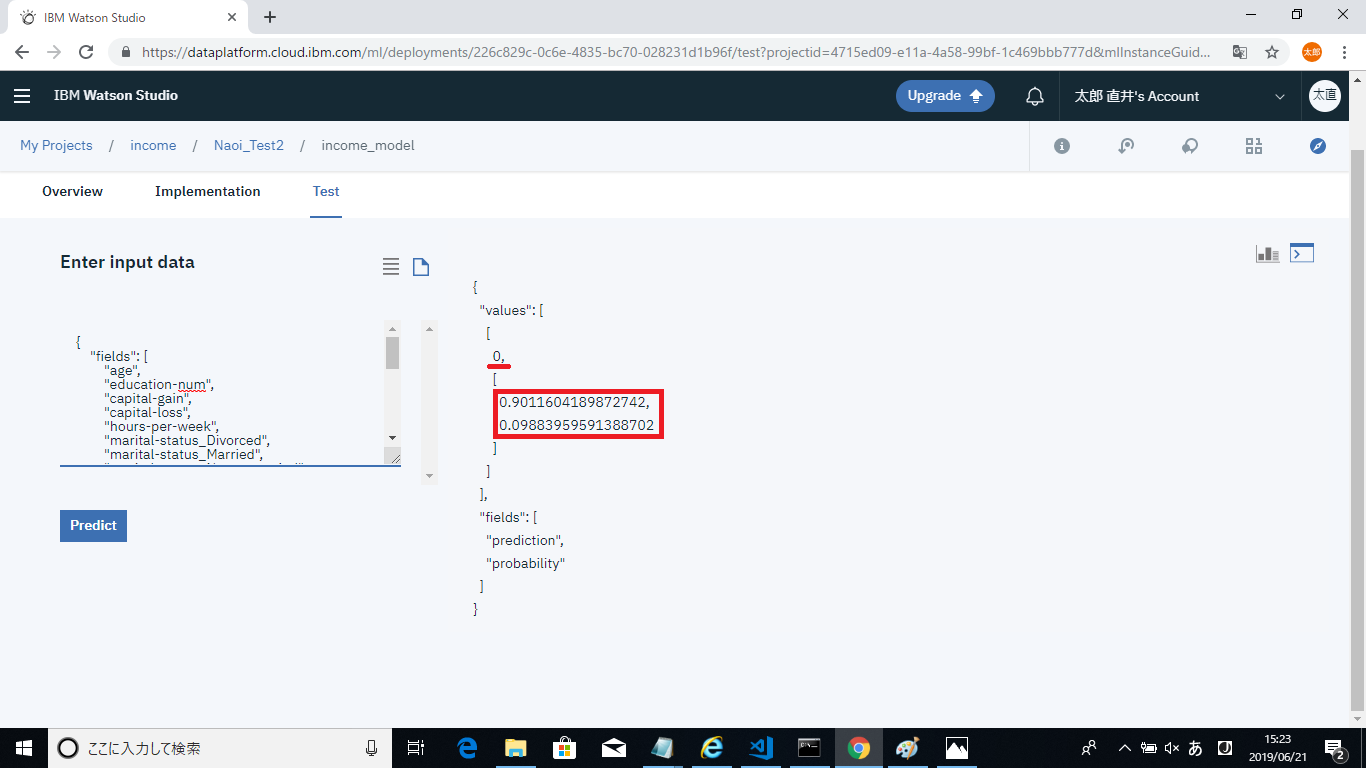
下線部が予測結果になります。
50,000$未満を「0」50,000$以上を「1」で出力するモデルを製作しているため、「0」と出力されています。枠内が確信度です。こちらは、上が「0」の確信度で下が「1」の確信度になります。
以上でIBM Watson Studio上での作業は完了です。以降は実際にNode.jsアプリから予測モデルを利用してみます。
IAMトークンの取得
アプリから予測モデルを利用するためには、2つのSTEPが必要になります。まずIAMトークンを取得し、そのトークンを使って予測モデルを利用する流れになります。こちらがIAMトークンの取得に利用したコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var options = { url : "https://iam.bluemix.net/oidc/token", headers : { "Content-Type" : "application/x-www-form-urlencoded", "Authorization" : "Basic " + btoa("bx:bx") }, body : "apikey=" + <span style="color: #ff0000;">apikey</span> + "&grant_type=urn:ibm:params:oauth:grant-type:apikey" }; request.post( options, function( error, response, body ) { wmlToken = "Bearer " + JSON.parse( body )["access_token"]; } ); |
bodyにセットしているapikeyについては、Watson Machine Learningの資格情報から確認できます。
予測モデルの利用
こちらが予測モデルに問い合わせを行う関数です。
|
1 2 3 4 5 6 7 8 9 10 11 |
function apiPost(scoring_url, token, mlInstanceID, payload, loadCallback, errorCallback){ const oReq = new XMLHttpRequest(); oReq.addEventListener("load", loadCallback); oReq.addEventListener("error", errorCallback); oReq.open("POST", scoring_url); oReq.setRequestHeader("Accept", "application/json"); oReq.setRequestHeader("Authorization", token); oReq.setRequestHeader("ML-Instance-ID", mlInstanceID); oReq.setRequestHeader("Content-Type", "application/json;charset=UTF-8"); oReq.send(payload); } |
scoring_url:デプロイ済みモデルのimplementationタブで確認できます。
token:手順6で取得したIAMトークンを使用します。
mlInstanceID:Machine Learningの資格情報から確認できます。
payload:先程テストの際に使用したjsonと同じ形式のデータです。
こちらが今回使用したpayloadのデータです。ユーザーがフォームに入力した値をアプリ内の変数に格納しjsonに成形しているため、valuesの中の値は変数名になっています。
|
1 2 3 4 |
'{ "fields": ["age", "education-num", "capital-gain", "capital-loss", "hours-per-week", "marital-status_Divorced", "marital-status_Married-AF-spouse", "marital-status_Married-civ-spouse", "marital-status_Married-spouse-absent", "marital-status_Never-married", "marital-status_Separated", "marital-status_Widowed"], "values": [['+age+','+education_num+','+capital_gain+','+capital_loss+','+hours_per_week+','+divorced+','+af_spouse+','+civ_spouse+','+spouse_absent+','+never_married+','+separated+','+widowed+']] }' |
上記内容をpostすると手順5で取得したものと同様の予測値、確信度が得られます。
完成
これらのコードを使い作成したWebアプリがこちらです。ここでは先程テストで使用したデータと同じものを利用して、API呼び出しがうまく行えている事を確認します。
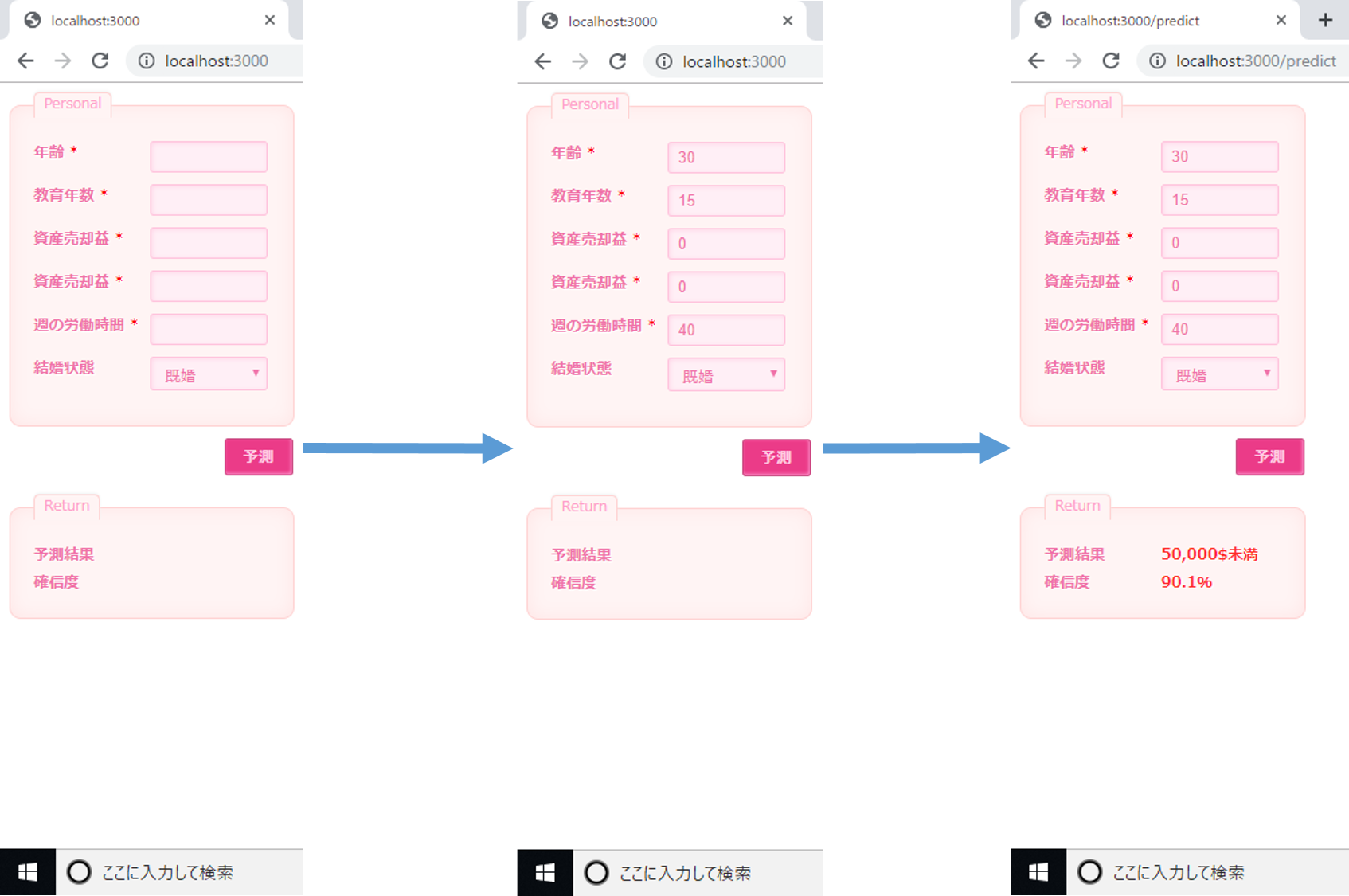
先程と同様に予測結果 50,000$未満、確信度90.1%を得られましたのでAPI利用ができていることを確認できました。
最後に
簡単なコーディングで予測モデルを利用したサービスを製作できるので、作成したモデルを顧客に利用してもらう際や、既存のWebアプリに組み込む際などにすごく便利だと感じました。今後は運用を見据え、Webアプリからの再トレーニングや精度のモニタリング等を実装できればと思います。

執筆者プロフィール

- tdi AI・コグニティブ推進部
-
文系出身の新米エンジニアです。これまでに行ってきたことは、ツール開発や画像認識、チャットボットの運用などです。
今後は機械学習についてもっと詳しくなりたいと思っています。




