目次
はじめに
前回、下記記事でAWSでIoTデータを見える化としてセンサーデータの取得から格納、格納したデータを表形式で見える化する部分までをご紹介しました。

今回は、その続きとしてAWSのBIツールであるAmazon QuickSight(以下、QuickSight)と連動して、取得したデータをグラフィカルに可視化する、見える化の応用について取り上げさせていただきます。
1. 今回のシナリオ
今回のシナリオでは、前回Amazon DynamoDB(以下、DynamoDB)に格納したセンサーデータを使用し、AWSのBIツールであるQuickSightの紹介と合わせて、蓄積されたデータをBIツールで扱いやすくするための加工やQuickSightによるデータの可視化までを流れをご紹介させていただきます。
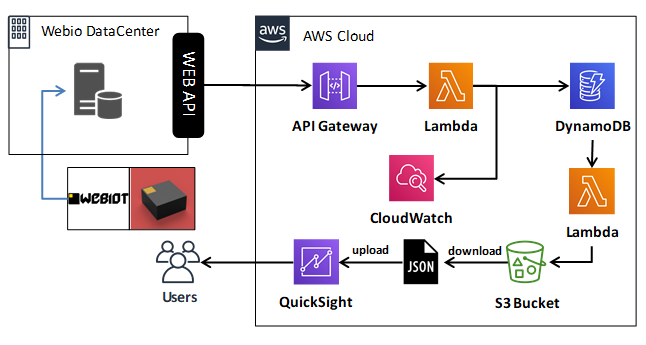
2. 今回構築するシステム構成
前回のシステム構成に機能を追加させ、今回は以下のような構成を検討しました。(2019年1月末に、AWSのアーキテクチャアイコンが新しくなったので、こちらのアイコンも最新化)
3. QuickSightに関して
概要
QuickSightは、AWSが提供するクラウドBIサービスです。簡単に情報を可視化する事が出来、アドホック分析を実行して素早くデータから気付きを得ることが可能です。また、AWSのデータソースとシームレスに連携することが可能で、作成したダッシュボードやレポートを共有する事が可能です。QuickSightでは、今回のこのサービスの為に新しく作られた『SPICE』という仕組みを採用しています。
SPICEとは
- Super-fast(超高速)
- Parallel(並列)
- In-memory Calculation Engine(インメモリ計算エンジン)
の頭文字からなる造語ですが、この仕組みを用いたQuichSightには以下のような特徴があります。
-
- 素早く始められる
サインインし、データソースを選んで数分でデータの可視化が可能です。 - 複数のデータソースにアクセスできる
ファイルやAWSデータソース、外部のデータベースにも対応可能です。 - 最適化された可視化
選択したデータに基づいて最適化された可視化の提供が可能です。 - 素早く答えを得られる
大きなデータセットに対しても素早く、インタラクティブな可視化が可能です。 - データを通してストーリーを伝える
可視化を通した”気付き”を他のメンバーと共有する事ができます。
- 素早く始められる
料金体系
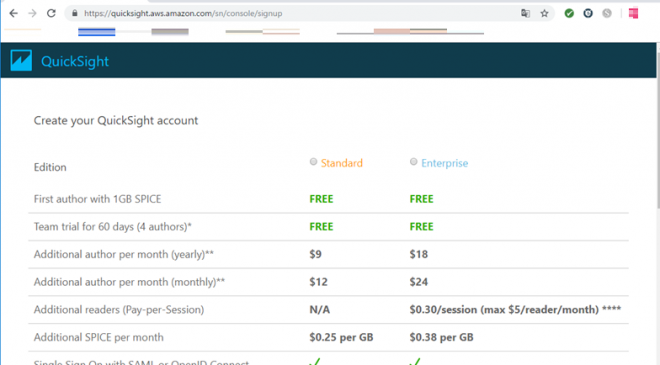
QuickSightには「Standard Edition」、「Enterprise Edition」の2つがあり、どちらのエディションを選ぶか、利用期間をどうするか、ストレージ容量はどれくらいにするかで料金が決まります。
- Standard Edition を選んだ場合
利用期間は月次利用で、1ユーザーあたり 12ドル/月、年間利用では、1ユーザーあたり 9ドル/月
ストレージ容量は、SPICEストレージ 0.25ドル/GB/月
(※10GB以上からの料金(SPICEストレージは10GBまで含まれており無料)) - Enterprise Edition を選んだ場合
利用期間は月次利用で、1ユーザーあたり 24ドル/月、年間利用では、1ユーザーあたり 18ドル/月
ストレージ容量は、SPICEストレージ 0.38ドル/GB/月
(※10GB以上からの料金(SPICEストレージは10GBまで含まれており無料))
その他、各エディションの機能比較などの詳細は、AWSの公式サイトにて確認することができます。
利用までの流れ
QuickSightは、AWSマネジメントコンソールにログインし、AWSサービス一覧からQuickSightを選択することで利用可能になります。初めてQuickSightを利用する場合は、以下のようにアカウント作成、エディションの選択を行った後に利用開始になります。
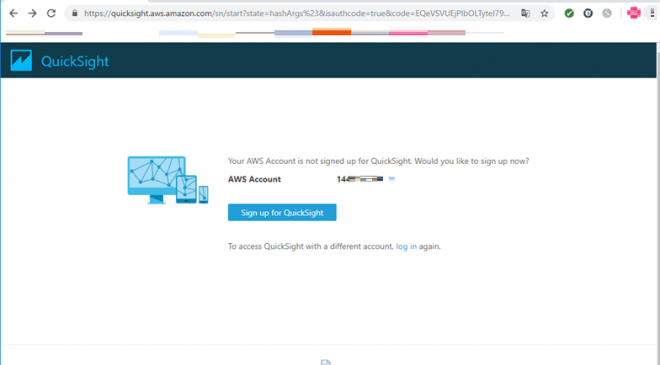
QuickSightアカウントの作成
AWSアカウントを確認し、「Sign up for QuickSight」を押下。
利用するエディションの選択
今回は Standard Editionを選択し、画面下にある「Continue」を押下。
QuickSightアカウントの追加情報を入力。今回は、QuickSightのデータソースとして、Athena、S3、S3 Storage Analytics、IoT Analyticsのすべてにチェックを入れてみました。(これらの設定は後から変更が可能)
追加情報の入力が完了したら、「Finish」を押下。
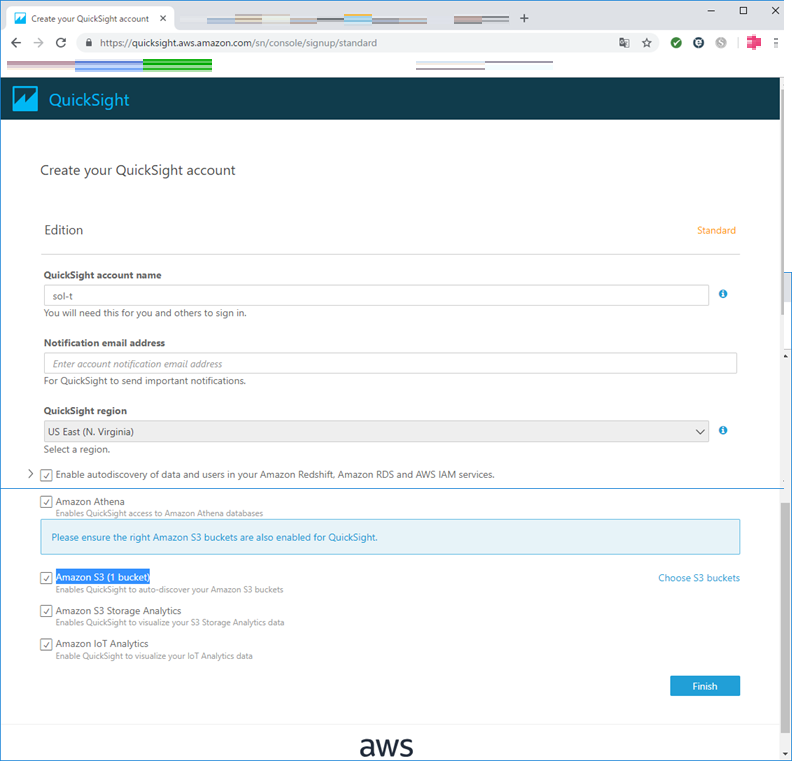
すると、アカウント作成中となり、作成完了画面が表示されればQuickSightが利用可能になります。
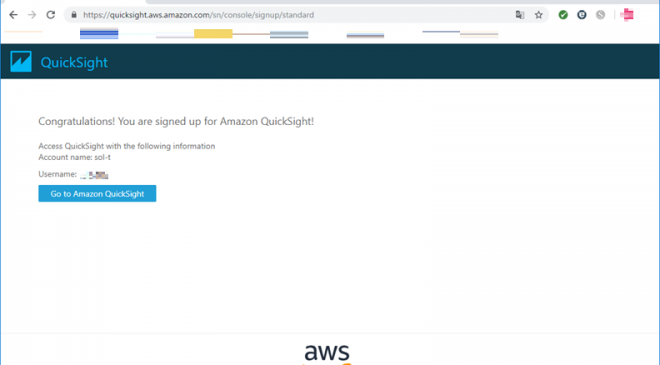
QuickSightへのサインアップ
上記のアカウント作成完了画面にて「Go to Amazon QuickSight」を押下するとQuickSightへサインアップが可能になります。初めは、QuickSightの解説が表示されますが、その後にサンプルページが表示されれば完了となります。
4. データ加工(Lambda)
QuickSightでDynamoDBのテーブルを直接データソースに指定したいところですが、執筆時点ではまだできないため、今回はDynamoDBのデータをAWS Lambda(Lambda)で加工の上JSONファイルに変換し、Amazon S3(以下、S3)上に出力したファイルをQuickSightで可視化してみようと思います。
また、今回DynamoDBのテーブルは前回使用したテーブルのsensortimeというunixtimeをローカル時間(JST)に変換したタイムスタンプの列を、sensor_date(YYYY-MM-DDの年月日の文字列)、sensor_time(hh:mi:ssの時分秒の文字列)に分割し、この2列をインデックスとして設定したテーブル(miso_20190201_dynamodb)をベースにJSONファイルを作成しております。
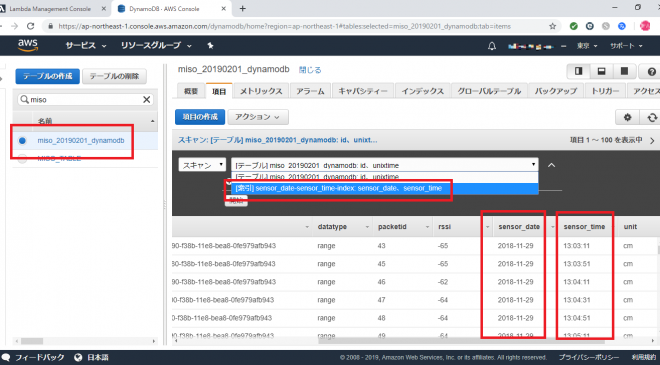
データ加工用のLambdaを作成します。今回作成するLambdaは、DynamoDBのテーブルを日付を指定してデータ抽出を行い、その結果をS3上に格納する仕組みになっています。(このLambdaをベースに、日次バッチで日ごとや月ごとにデータ抽出可能です)
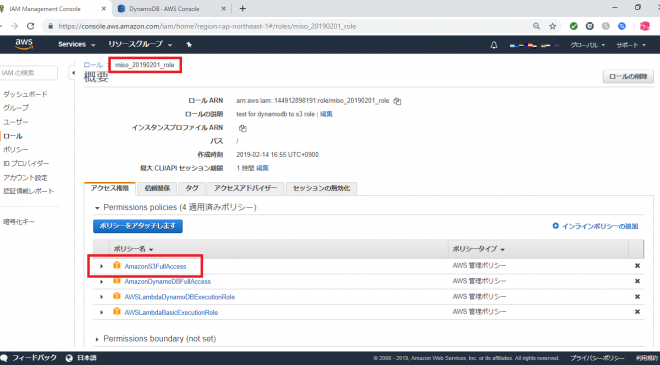
まずは、今回作成するLambda用にIAMロールを作成します。IAMロールは前回作成した miso_20181207_roleというロールをベースに、ポリシー (AmazonS3FullAccess)を追加して新しく miso_20190201_role を作成しました。
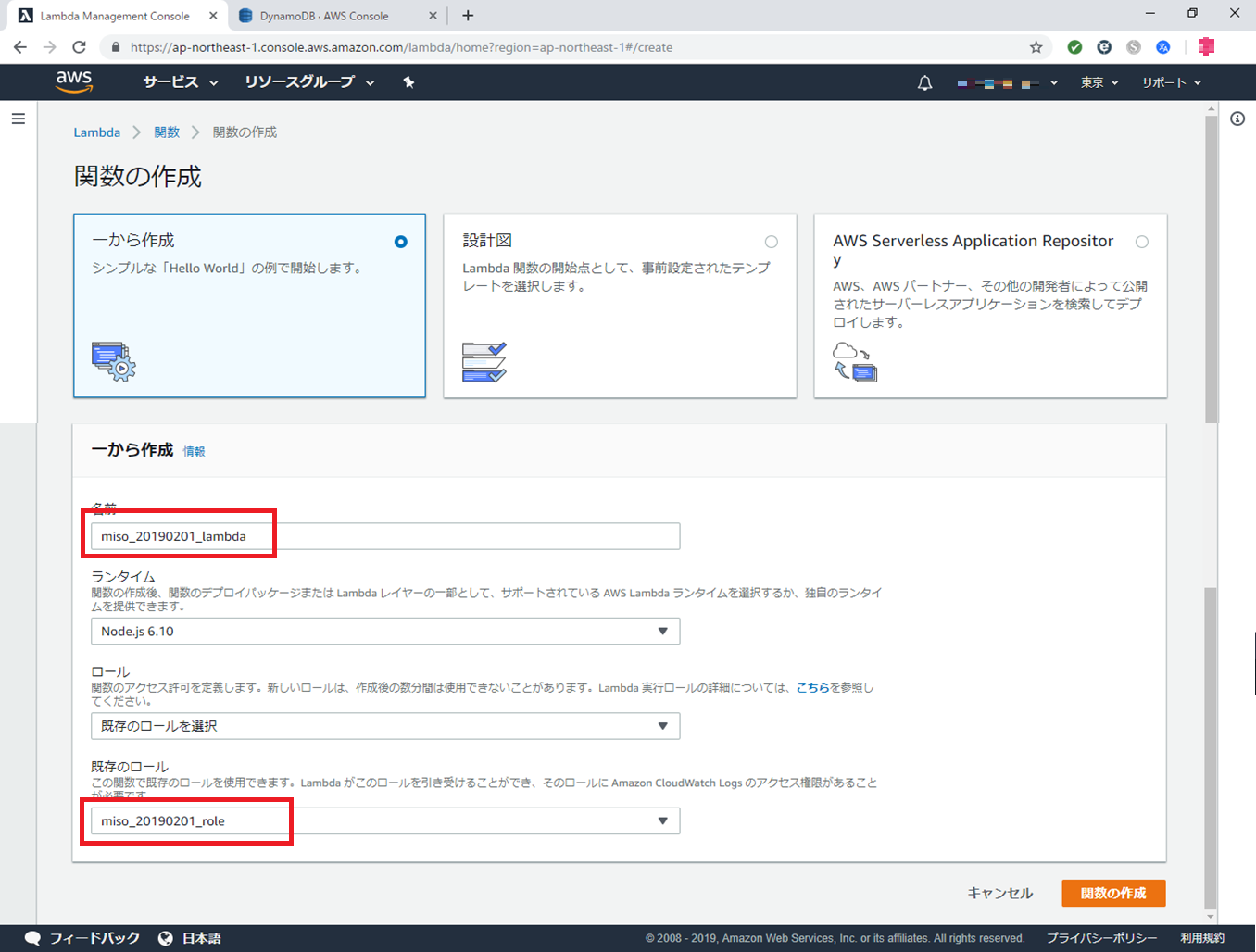
前回同様に、Lambdaを作成します。今回は miso_20190201_lambda という名前で作成しました。
Lambda自体のコードは以下の通りです。今回のLambdaでは、node_moduleの moment.js を追加していますのでご注意ください。
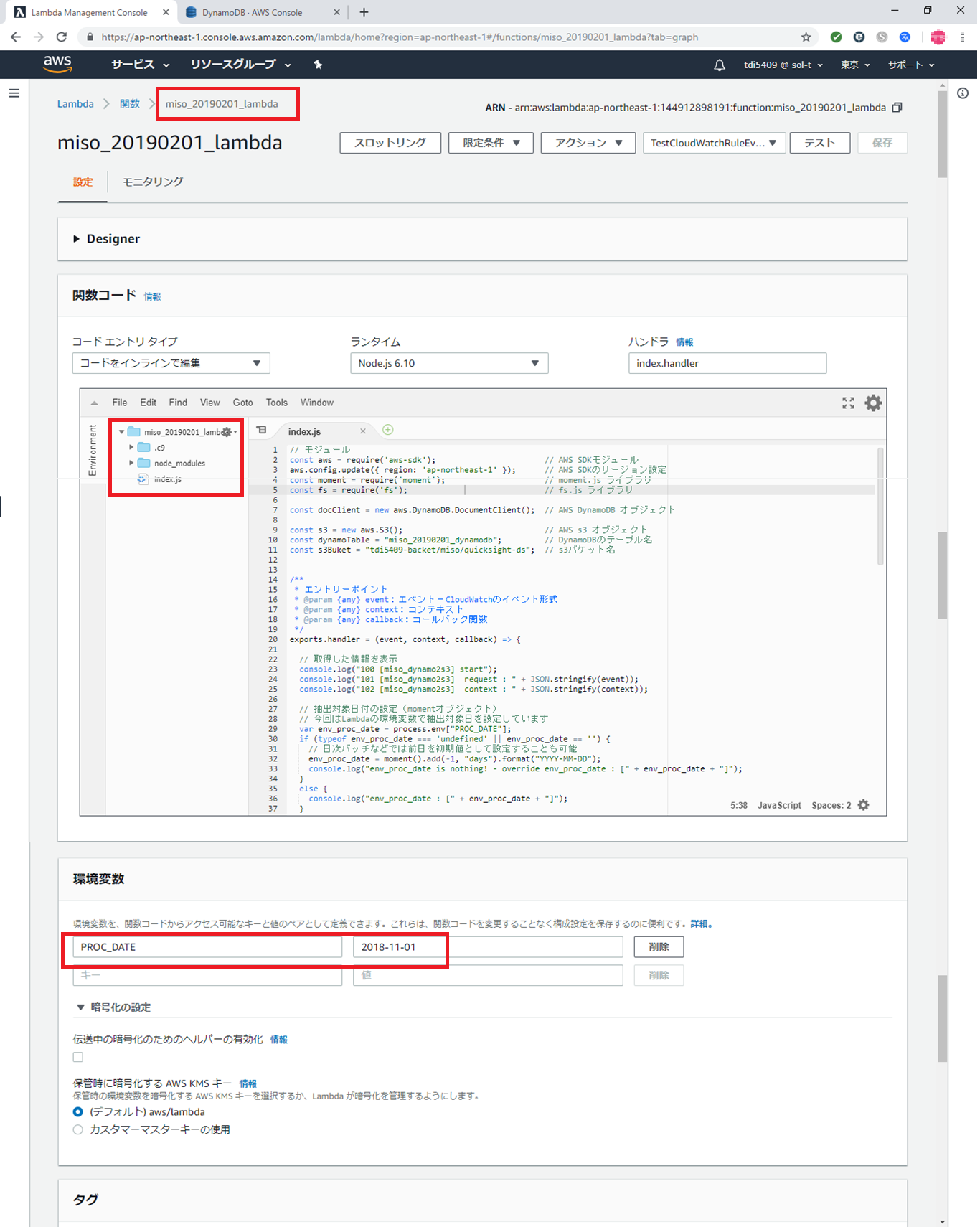
コードは以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
// モジュール const aws = require('aws-sdk'); // AWS SDKモジュール aws.config.update({ region: 'ap-northeast-1' }); // AWS SDKのリージョン設定 const moment = require('moment'); // moment.js ライブラリ const fs = require('fs'); // fs.js ライブラリ const docClient = new aws.DynamoDB.DocumentClient(); // AWS DynamoDB オブジェクト const s3 = new aws.S3(); // AWS S3 オブジェクト const dynamoTable = "miso_20190201_dynamodb"; // DynamoDBのテーブル名 const s3Buket = "tdi5409-backet/miso/quicksight-ds"; // S3バケット名 /** * エントリーポイント * @param {any} event:エベント-CloudWatchのイベント形式 * @param {any} context:コンテキスト * @param {any} callback:コールバック関数 */ exports.handler = (event, context, callback) => { // 取得した情報を表示 console.log("100 [miso_dynamo2s3] start"); console.log("101 [miso_dynamo2s3] request : " + JSON.stringify(event)); console.log("102 [miso_dynamo2s3] context : " + JSON.stringify(context)); // 抽出対象日付の設定(momentオブジェクト) // 今回はLambdaの環境変数で抽出対象日を設定しています var env_proc_date = process.env["PROC_DATE"]; if (typeof env_proc_date === 'undefined' || env_proc_date == '') { // 日次バッチなどでは前日を初期値として設定することも可能 env_proc_date = moment().add(-1, "days").format("YYYY-MM-DD"); console.log("env_proc_date is nothing! - override env_proc_date : [" + env_proc_date + "]"); } else { console.log("env_proc_date : [" + env_proc_date + "]"); } // 処理日のmomentオブジェクトを作成し、DynamoDBの日次データをS3に保存 var mProcDate = new moment(env_proc_date, "YYYY-MM-DD"); extructDailyData(mProcDate); // レスポンス const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), }; callback(null, response); }; /** * DynamoDBから日次データを取得しS3に配置 * @param {any} mDay : データ出力日の momentオブジェクト */ var extructDailyData = function (mProcDate) { // DynamoDBのクエリパラメータ // → 抽出日以降のデータを出力条件に変換 // 日次バッチなどでは前日を対象(=)とすれば日ごとのデータを抽出可能 var params = { TableName: dynamoTable, IndexName: "sensor_date-sensor_time-index", KeyConditionExpression: "#date >= :date and #time >= :time", // 今回は 対象日以降(>=)を対象 ExpressionAttributeNames: { "#date": "sensor_date", "#time": "sensor_time" }, ExpressionAttributeValues: { ":date": mProcDate.format("YYYY-MM-DD"), // 指定された日付 ":time": "00:00:00" // 時間は 00:00:00 以降を対象 } }; // DynamoDBへクエリ実行、戻りをS3に格納 docClient.query(params).promise().then(data => { let datagArray = []; data.Items.forEach(element => { datagArray.push(JSON.stringify(element)); }); // データなしなら抜ける if (datagArray.length == 0) { return new Promise(function (resolve, reject) { console.log("data in dynamodb is nothing! - [" + mProcDate.format("YYYY-MM-DD") + "]"); }); } else { // データあり console.log("dynamodb data count [" + datagArray.length + "] - [" + mProcDate.format("YYYY-MM-DD") + "]"); return new Promise(function (resolve, reject) { //Lambdaでは一時的なファイルの出力先に/tmpが使える fs.writeFile("/tmp/tmp.txt", datagArray.join("\n"), function (err) { if (err) reject(err); else resolve(data); }); }); } }).then(() => { // Promise が成功した場合、S3に書き込み let s3Params = { Bucket: s3Buket, // S3の格納先パス、Bucket以降のパス Key: `${dynamoTable}_${mProcDate.format("YYYY-MM-DD")}.json`, // 出力ファイル名 ContentType: "application/json; charset=utf-8", // コンテキスト Body: fs.readFileSync("/tmp/tmp.txt", "utf-8") // 出力内容(UTF-8) }; return s3.putObject(s3Params).promise(); }).then(data => { // resolve(成功時) console.log(data); }).catch(err => { // reject(失敗時) console.log(err); }); }; |
上記のコードでは、日次バッチ用に日付を指定して抽出が可能になっておりますが、今回はDynamoDBをSCANして全件取得しました。実行すると、以下のようにS3にファイルが生成されていることを確認しています。
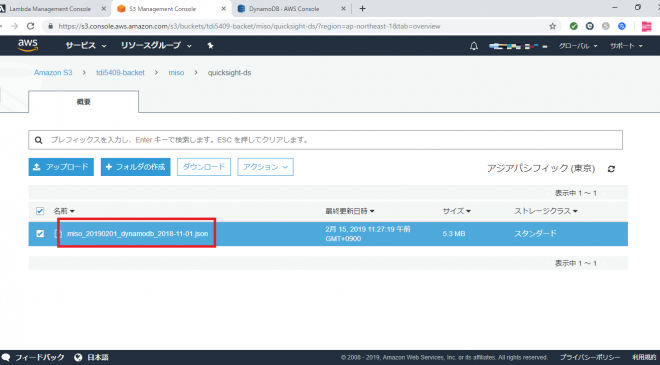
5. データ可視化(QuickSight)
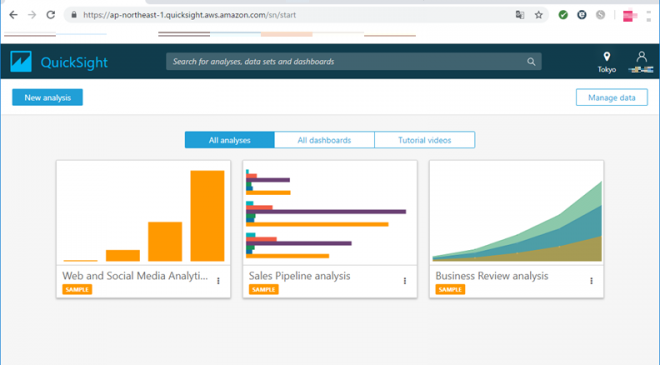
次に、データの可視化を行います。上述の通りQuickSightにサインアップした状態から始めます。QuickSightにサインアップをするには、AWSコンソールにログインした後に、サービス一覧より「QuickSight」を選択してください。利用までの流れの通りユーザー設定などが問題なくできていれば、QuickSightにサインアップされ以下のような画面が表示されます。
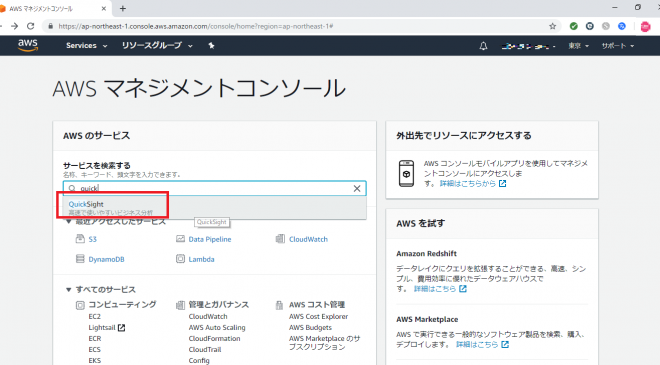
サインアップしたら左上にある「New analysis」を押下します。
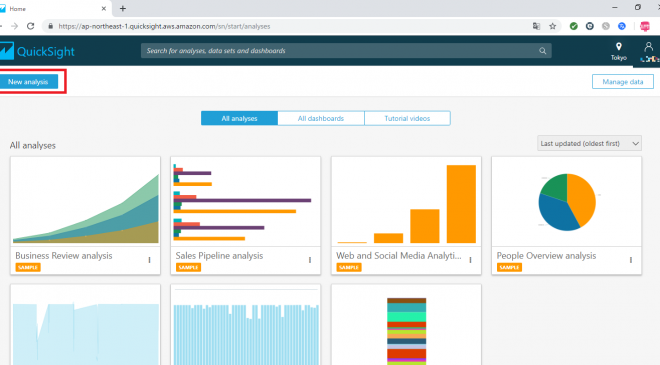
データセットの選択画面になるので、左上の「New data set」を押下します。
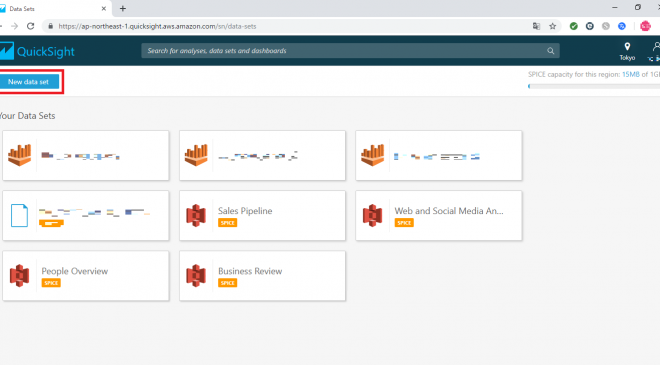
データセットの作成画面で「Upload a file」を押下すると、ファイル選択ダイヤログが表示されるので、先ほどS3上に作成したDynamoDBのデータファイルをローカルにダウンロードして置き、そのファイルを選択してください。(他にもデータセットを作成する方法はありますが、今回は一番シンプルにローカルのデータファイルをアップロード方法をとっています)また、今回使用したファイルは、以下のような情報が設定されております。
| No | 列名 | 内容 | サンプル |
| 1 | id | センサーID | 任意の文字列 |
| 2 | unit | センサーの値の単位 | cm |
| 3 | unixtime | UNIX時間のセンサー日時 | 1543464191 |
| 4 | sensor_date | センサー日付 | yyyy-mm-dd |
| 5 | sensor_time | センサー時間 | hh:mi:ss |
| 6 | battery | バッテリー電圧 | 2.97 |
| 7 | value | センサーの値 | 200.0 |
| 8 | rssi | センサー信号の強度 | -65 |
| 9 | datatype | センサーの種別 | 種別を表す文字列 |
| 10 | dataid | データを識別するid | GUID |
| 11 | packetid | センサー内の連番 | 1 |
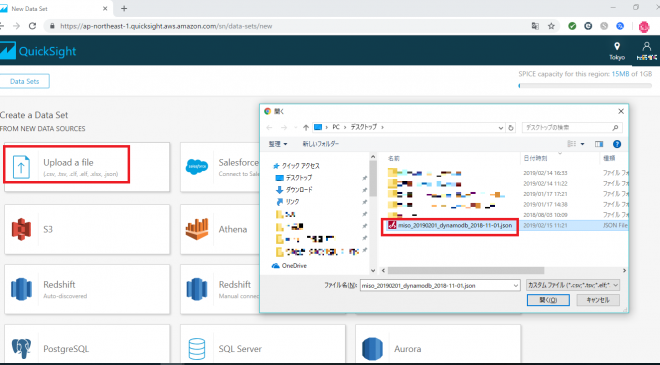
アップロードしたデータの確認画面が表示されるので、「Edit settings and prepare data」を押下してください。
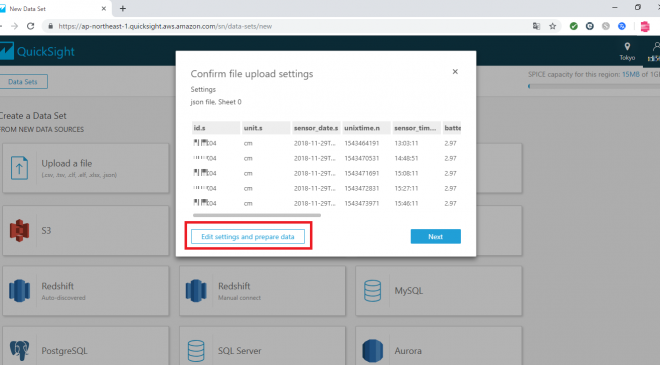
アップロードしたファイルの列名やデータ型が表示されているので、内容を確認します。なお、画面左にあるDataSourceのFieldsにある「Add calculated field」を押下することで「計算列」を追加することも可能です。今回は、追加列などは使わず、内容を確認しているだけです。
最後に、画面上部にあるデータセット名を「miso_20190201_dynamodb_2018-11-01」→「miso_20190201_dataset」に変更し、右隣りの「Save & Visualization」を押下してデータセットを作成します。
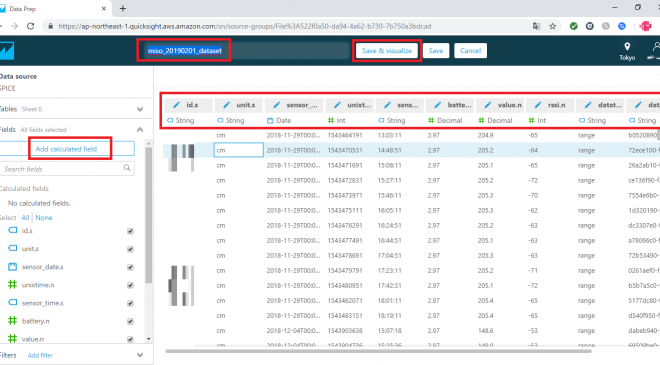
次に下図のように、レポート作成画面が表示されます。基本的な使い方は、左側のナビゲーションの「Fields list」にある列からメジャーを選択して、右側の四角い枠に入れ、「Visual types」から表示するグラフの種類を選択して可視化をしていきます。
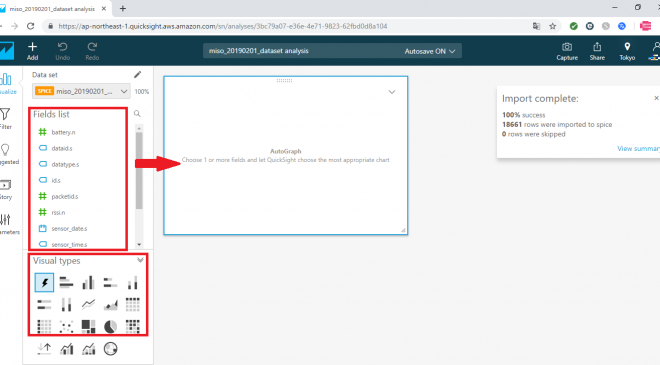
今回は、センサーから物体までの距離の時間経過による推移をグラフにすることで、センサーの種別(id)毎に、時系列(sensor_date)毎に値(value)の平均の推移を可視化しようと思います。
まず、「Fields list」からsensor_date.sを選択すると、下の図のようなグラフが自動的に生成されます。グラフ上部に「Field wells」のX軸(X axis)に選択した sensor_date.s が設定されることを確認してください。
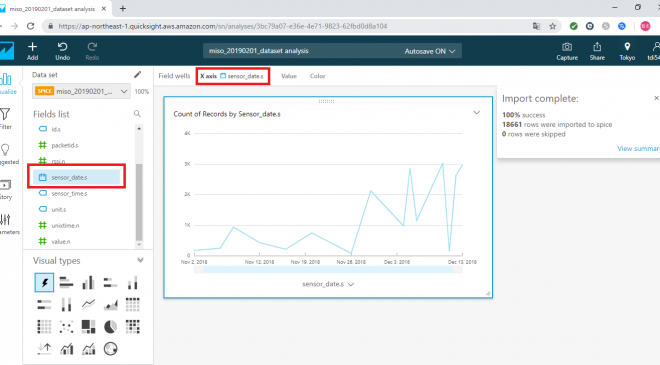
次に、同じく「Fields list」から value.n を選択すると、今度は下の図のように日ごとのvalueのカウントされた状態のグラフが生成されます。グラフ上部にある「Field wells」のValuesに選択した value.n(Sum)が設定されることを確認してください。
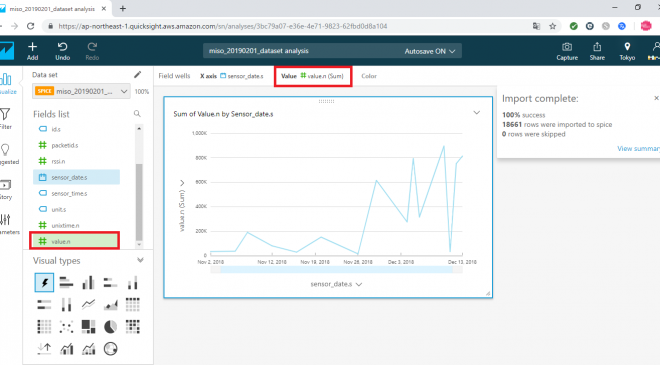
次に、今回取り込んだデータから不要なデータを除外するためのフィルターを設定します。
画面左の「Filter」ボタンを押下すると以下のような画面になります。「Applied filters」にリンクで「Create one…」と表示され、クリックするとフィールドの一覧が表示されるので、一覧から id.s を選択してください。
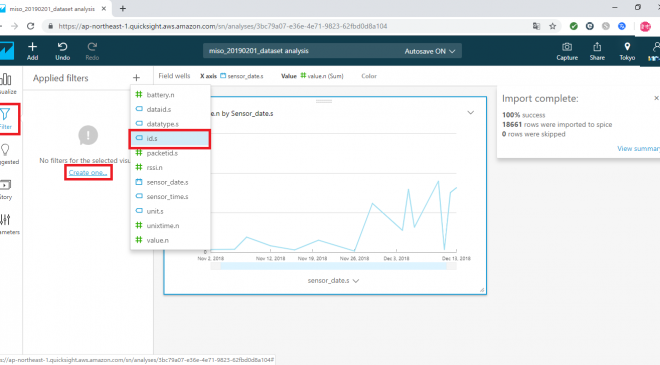
すると、id.s 列に対するフィルター設定が可能になります。今回は「Filter type」を「Filter list」にし、アップロードしたidのデータのうち、末尾が03、04のデータのみを表示対象とするフィルター設定をしました。
準備ができたら、「Apply」ボタンで確定します。
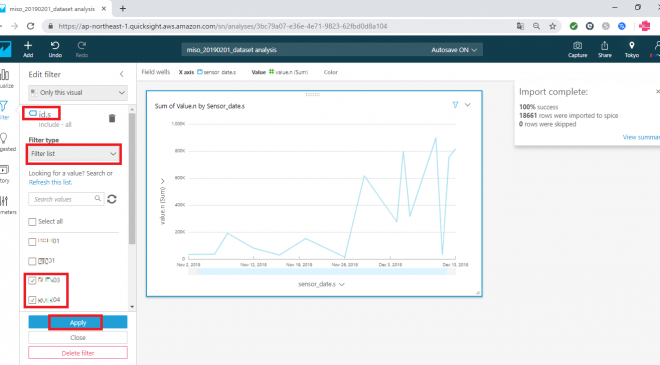
フィルターが適用され以下のようなグラフが表示されました。(若干、グラフの形状が変わっていることが確認できます)
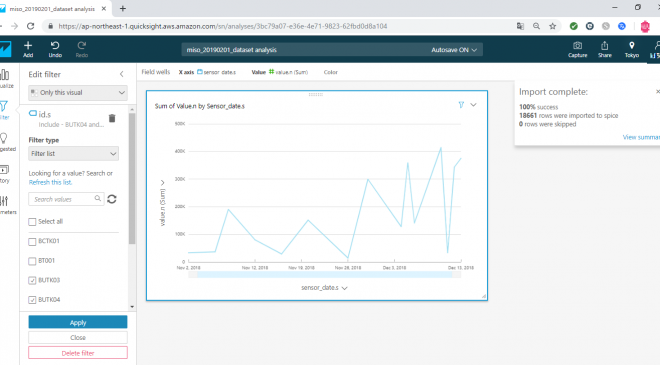
ここまでで、フィルターを使用して必要なデータのみに絞って可視化させることができました。しかし、この時点ではまだ value がカウントになってしまっているため、次に日ごとの平均の推移になるようvalueの集計方法を変更します。
まず、グラフ上部にある field wells をクリックすると、現在グラフで設定された軸が確認できます。
次に value を選択するとプルダウンリストが表示されるので、その中の Aggregate「SUM」を「Average」に変更します。
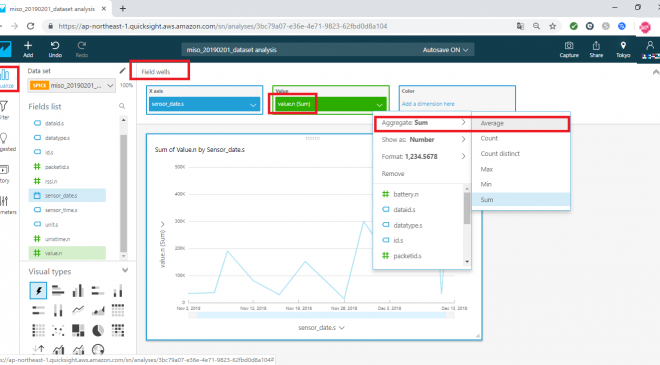
すると、日ごとのvalueの平均が表示されるようになります。(なお、グラフを上にマウスオーバーすることで内容の確認も可能です)
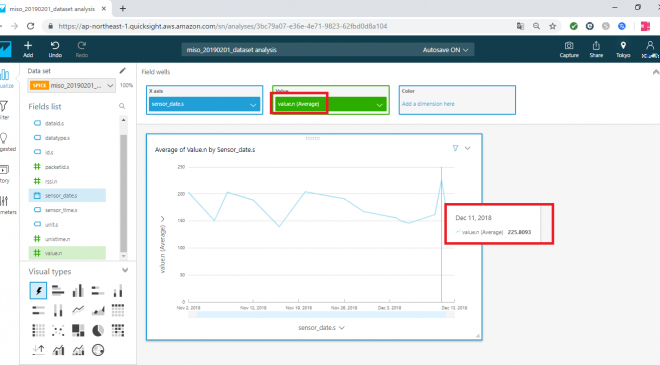
ただし、今回対象とした末尾が03、04のセンサーデータの平均となってしまうため、各センサーデータごとの平均値が確認できるようにします。
左の「Fields list」よりid.sを選択します、するとグラフ上部の「Field wells」の Colorに id.sが設定され、各センサーごとの平均が確認できるようになります。
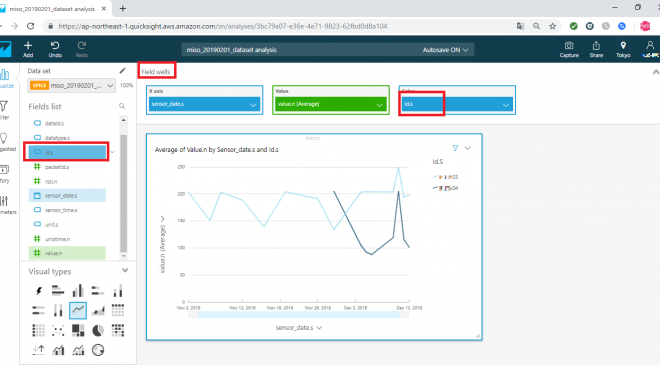
これで、センサーの種別(id)毎に、時系列(sensor_date)毎に値(value)の平均の推移をみていくグラフが作成されました。基本的にはGUIベースで列をドラック&ドロップすることで簡単にデータの可視化ができるようになっており、比較的ライトにデータの中から気づきを得ることが可能かと思います。
また、上記のグラフでは時系列や値の書式などが英語表記になってしまいましたが、各フィールドから書式の変更が可能で、外部展開用のレポートなども作成ができるかと思います。
最後に以下の図は、上記の内容やタイトルも編集した最終形のグラフのイメージです。書式やタイトルをローカライズすることで、報告用のレポートにも適用することは十分可能ですので、まずは手を動かして色々な記述方法やレポートを作成してみるのもよいかと思います。
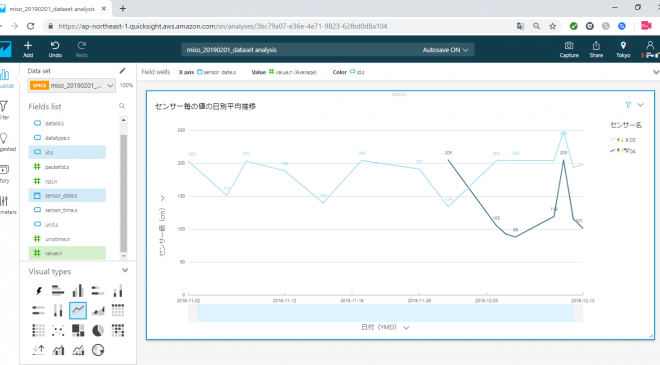
まとめ
前回、今回でセンサーデータを用いてデータの取得、格納、加工、可視化という一連の流れがAWS上で比較的簡単に、短時間にできることが確認できました。データの可視化に関して、今回はQuickSightで素早く可視化することに重点を置いたため、S3上のファイルをいったんダウンロードしてQuickSightに読み込みませましたが、システムとして検討するのであれば、S3上のファイル群を直接QuickSightに読み込ませる方法(別途、S3マニフェストファイルが必要)がよいかと思います。
また、QuickSightではS3上のファイルだけでなく、それ以外にも
- Amazon RedShiftクラスタ
- データベースインスタンス
MySQL(5.1以上)、PostgreSQL(9.3.1以上)、MariaDB(10.0以上)、Aurora(Amazon RDSのみ)、Microsoft SQL Server(2012以上) - テキストファイル
CSV(*.csv)、TSV(*.tsv)、ログファイル(*.clf、*.elf)などが対応可能 - SaaSのデータソース
Salesforce等
といった様々な形式に対応しております。
分析自体もGUIベースで比較的簡単に可視化ができるので、AWSリソースとの親和性を考えると、エンジニアやアナリスト以外のライトユーザーへの結果の共有ツールとしてAWSユーザーにとって大いに期待できるのではないかと思います。AWSのサービスは日々進化しており、今回行った時系列の分析であれば新たにAmazon TimestreamやAmazon Forecastといったサービスも提供され始めてきており、より一層タイムリーな対応が要求されてくることでしょう。
これからのエンジニアはこういったサービスの仕組みを理解し、TPOに合わせてソリューションの提供などを検討する必要が出てくると思いますので、これからも注力しながら日々精進していければと思います。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 社内の開発プロジェクトやクラウド・データ活用の技術サポートを担当しています。データエンジニアリングやシステム基盤づくりなど、気づけばいろんなことに首を突っ込んできましたが、やっぱり「まずは試してみる」がモットー。最近は、ローカル生成AIやコード生成AIといった、開発現場ですぐ役立つ生成AIの活用にハマり中。もっと楽に、もっとスマートにものづくりできる世界を目指して、あれこれ奮闘しています。
この執筆者の最新記事
 Pick UP!2025年7月15日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (②性能指標とログの取り方編)
Pick UP!2025年7月15日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (②性能指標とログの取り方編) Pick UP!2025年5月19日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (①環境構築編)
Pick UP!2025年5月19日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (①環境構築編) Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――後編
Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――後編 Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――前編
Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――前編