
はじめに
今回は、「ちょっと自然言語処理やってみたいな」という方へ、Pythonによる自然言語処理のさわりの部分をご紹介していきたいと思います。
”ちょっと”なのでそこまでスペックが高いPCは使用しません。「処理能力が高いサーバーを用意できない」「クラウドにはデータをアップロードできない」といった課題をお持ちの方もご参考にして頂ければ幸いです。
自然言語処理をする内容としてはTwitterのデータでの感情分析に挑戦します。
環境について
今回使用するPC環境は以下になります。
- プロセッサ:Intel(R)Core(TM)i5-6300U CPU@2.4GHz 2.4GHz
- 実装メモリ(RAM):8.00GB
- システムの種類:64ビットオペレーティングシステム
- OS:Windows7 Professional
使用するソフトウェアは、プログラム言語Python+形態素解析エンジンMeCab(*1)で行います。どちらもインストーラをダウンロードし、ソフトウェアをインストールする事で使えるようになります。私はAnaconda(*2)でPython環境を構築しました。
MeCabはインストールした後、Pythonから呼び出せるように設定する必要があります。64ビット版のMeCabインストーラを作ってくださっている方がいましたので、今回私はそちらを使用させて頂いています。なお、64ビット版のMeCabではCaboCha(*3)が使えないようなのでご注意ください。
PythonからMeCabを呼び出せるようにする方法はインターネットで”Python MeCab”などで検索すると沢山記事が出てきますのでそちらをご参照ください。
*1:MeCabはオープンソースの形態素解析エンジンで、文章を意味を持つ最小の単位(単語)に分解できます。
*2:AnacondaはPythonおよびRのディストリビューションです。
*3:CaboChaは日本語係り受け解析器で、「主語と述語」や「修飾語と非修飾語」のような関係性を解析できます。
使用するデータ
今回は自然言語処理により、オリンピックに関するTweetについて感情分析をしたいと思います。Tweetの記載と感情を表す日本語表現をマッチングして、そのTweetにはどの様な感情が含まれているかを分類します。
分析対象のデータについて、今回はサンプルとしてTwitterのデータ7,756件、約1.6MBのCSVファイル(文字コードUTF-8)を用意しました。今回使用するデータはTwitterで”オリンピック”と検索した結果のTweetデータです。
ファイル名はall_olympic_2019-07-07.csvとしています。Twitterのデータ取得はAPIを利用しました。Twitter APIによるデータ取得はインターネットで検索すると沢山記事が出てきますので、そちらをご参考にしてください。
どのような日本語表現がされているとどのような感情を持っていると考えられるかを判断する元のデータとして、今回は、長岡技術科学大学 電気電子情報工学専攻 自然言語処理研究室の皆様が公開してくださっている日本語感情辞書を使用させて頂きます。
- 長岡技術科学大学 電気電子情報工学専攻 自然言語処理研究室(2020年3月末に閉鎖されるそうです。)
まずはTwitterデータを確認します。

このような文章が沢山あるため、全て読んで感情を分類するのは困難なので、自然言語処理により感情分析を試そうと思います。
次に日本語感情辞書を確認します。Excelファイルの中身は感情分類シートと作業者シートで構成されています。
最初に作業者シートを確認します。作業者シートは3名分ありますが、今回は1名分の「作業者C」のみ使用します。作業者シートには、感情の表現が記載されいてるWord項目と、読み方が書いてあるKatakana項目、感情を表しているEmotionが記載されています。
<作業者シート>

このシートのWord部分をTweetとの比較に、Emotionは感情分類シートとの突合せに使います。
*感情分類シートにも別項目としてEmotion項目があるので、混乱しないように注意しましょう。
次に、感情分類シートを確認します。このシートは、感情一覧が記載されているEmotion項目と、その感情を1文字で表すSymbol項目があります。感情分類シートのSymbol項目と作業者シートのEmotionをキーとして、どのような表現にどのような感情があるかを紐付けることができます。
<感情分類シート>
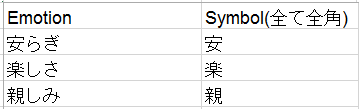
今回、感情分類シートについて、少し手を加えます。後々プログラム上で使いやすいように項目名のSymbol(全て全角)から、(全て全角)部分を削除しておきます。
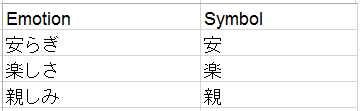
これだけでも感情分析はできますが、今回はさらにデータを追加加工して、Tweetの内容がPositiveなのか、Negativeなのかを分析できるように、感情分類のシートのEmotionにPositive/Negativeの項目を追加したいと思います。新たにPosNegという項目を追加して、Emotionに対してPositive/Negativeを付けました。

これらの2つのシートを後々プログラムから使いやすいように、文字コードがUTF-8のCSVファイルにそれぞれ分けて保存します。私は、作業者シートをD18-2018.7.24.csv、感情分類シートをPositiveNegativeSymbol.csvとして進めます。ここまで出来たら事前準備は完了なので、次からようやく自然言語処理を始めます。
自然言語処理
ここから自然言語処理を、以下の順番で処理を行っていきます。
- Twitterデータの形態素解析
- 日本語感情辞書の形態素解析およびWordとEmotionの紐付け
- 形態素解析済みTwitterデータと、形態素解析済み日本語感情辞書のマッチング
今回はJupyter Notebook上で処理を行っていきます。まずはPythonからMeCabを呼び出せることを確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
## 初回は mecab-python-windows と pandas をインストール !pip install mecab-python-windows !pip install pandas ## 必要なライブラリをインポート import MeCab import pandas as pd import csv ## 今回使用するMeCabの出力フォーマット m = MeCab.Tagger('-F"%f[6] " -U"%m " -E"') ## その他のフォーマット # m = MeCab.Tagger("-Owakati") # m = MeCab.Tagger("-Ochasen") # m = MeCab.Tagger() ## MeCabの動作確認 m.parse('この竹垣に竹立てかけたのは竹立てかけたかったから竹立てかけた') |
さて、ここまででMeCabの動作結果が確認できるので、一度動かしてみます。すると以下のように返ってきました。
![]()
無事に形態素解析する事ができました。
今回使用したフォーマットは形態素解析した結果の単語ごとにダブルクォーテーション(“)で区切っています。なお、最後の方にある”竹”立てかける”た”ですが、これは元の文章の”竹立てかけた”を形態素解析した際、”立てかけた”という過去形を、正規系に直したものになります。これにより、文章中の単語の変化形も変化前の単語と同じように扱うことができます。
ちなみに、MeCabの出力フォーマットを指定しない場合、以下の様になります。

こちらは単純に形態素解析した情報や、品詞種別、形態素解析したものを正規化した情報など多くの情報が有りますが、そのままでは扱いづらいため、今回はMeCabの出力フォーマットを指定しています。
PythonからMeCabを呼び出す事ができるのを確認したので、早速Twitterデータを形態素解析したいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
## ## Tweetデータの形態素解析処理 ## ## Tweetの読み込み df_data = pd.read_csv("all_olympic_2019-07-07.csv") ## データの中身を確認 df_data.head() |

Tweetが取り込めていることが確認できました。次にこのTweetを形態素解析していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
## Tweet内容を形態素解析する ## あわせて、"区切りされている記載のためSplitでの分割 ## 先頭と末尾に不要なデータが入るので削除 td = [] for i in df_data['Tweet']: ## ダブルクォーテーション区切りする temp = m.parse(i).split('"') ## 先頭と末尾の不要なデータを削除 del temp[0] del temp[-1] ## データの追加 td.append(temp) ## 形態素解析されたことを確認 pd.DataFrame(td[0]).T |

無事に形態素解析する事が出来ました。この時点で満足してしまうかもしれませんが、まだ続きます。
ここで実際に感情分析をしようと思ってもまだ課題が有ります。はたして日本語感情辞書は形態素に分かれているのでしょうか?それを確認するために、試しに日本語感情辞書の内容も形態素解析したいと思います。
*分析する方法としては日本語感情辞書に含まれる単語を辞書に登録する方法もありますが、今回は日本語感情辞書を形態素解析する方式で進めます。
実際に日本語感情辞書の内容を形態素解析してみます。形態素解析する対象は作業者シートをCSV化したもの(D18-2018.7.24.csv)のWord項目になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
## ## 日本語感情辞書の形態素解析 ## ## 日本語感情辞書の読み込み df = pd.read_csv("D18-2018.7.24.csv") pn_df = pd.read_csv("PositiveNegativeSymbol.csv") ## 読み込んだ日本語感情辞書の確認 ## Word : 表現の仕方 ## Emotion : どのような感情をシンボル化されたデータ #作業者シートの確認 df.head() |
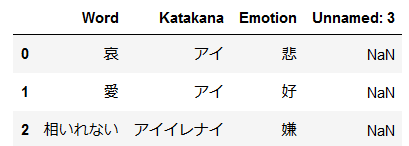
まずは作業者シートが取り込める事を確認します。Unnamed:3という列が出来ていますが今回は使用しないため、スルーします。
続いて感情分類シートも取り込めているか、確認します。
|
1 2 3 |
#感情分類シートの確認 pn_df.head() |
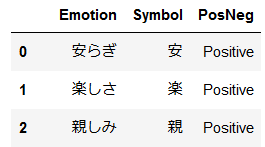
問題なく取り込むことが出来ています。次は日本語感情辞書の内容を形態素解析します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
## 日本語感情辞書を形態素解析する ## 作業者シートのEmotionと感情分類のSymbolを紐付けて、 ## Wordの形態素解析結果, Emotion, PosNegのデータを作る pnWord_dic=[] ## 形態素解析対象のループ for i in range (0,len(df),1): temp = [] tempEmotion = [] tempPosNeg = [] ## Wordの形態素解析結果をダブルクォーテーション区切りにする temp.append(m.parse(df['Word'][i]).split('"')) ## Wordの先頭と末尾の不要なデータを削除 del temp[0][0] del temp[0][-1] ## 作業者シートのEmotionが複数の感情を持つデータ用にループ for j in range(0, len(df['Emotion'][i]),1): ## 作業者シートのEmotionが感情シートのSymbolに無い場合のエラー回避 if (len(pn_df[pn_df.Symbol==df['Emotion'][i][j]])!=0): ## 感情分類シートのEmotionとPosNeg抽出 tempEmotion.append(pn_df[pn_df.Symbol==df['Emotion'][i][j]].values[0][0]) tempPosNeg.append(pn_df[pn_df.Symbol==df['Emotion'][i][j]].values[0][2]) temp.append(tempEmotion) temp.append(tempPosNeg) ## Emotionと形態素解析したWordを変数に代入 pnWord_dic.append(temp) pnWord_dic = pd.DataFrame(pnWord_dic, columns=['Word','Emotion','PosNeg']) ## 結果の確認 pnWord_dic.loc[12:14] |
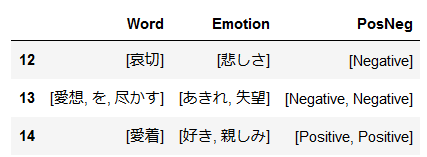
これでTwitterと日本語感情辞書はどちらも同じ形態素解析エンジンで分解されたので、内容の比較ができます。また、Wordに対してPositive/Negativeの紐付けもできました。ちなみに、結果の確認をpnWord_dic.loc[12:14]で指定しているのは、pnWord_dic.head()では形態素解析されるWordが表示されなかったため、形態素解析される「愛想を尽かす」を確認するためです。
では次にTweetの内容に対して、日本語感情辞書の内容をマッチングしましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
temp = ['Tweet','Positive Flag','Negative Flag','Emotion','Word'] results = [] results.append(temp) for j in range(0,len(td),1): temp = [] ## PositiveまたはNegativeな表現が含まれている場合、Trueにするフラグ positiveFlag = False negativeFlag = False Exp = [] emotion = [] ## 日本語感情辞書をループ for i in range(0,len(pnWord_dic),1): ## 日本語感情辞書の内容がTweetに含まれる場合 if (set(pnWord_dic['Word'][i]).issubset(td[j])): ## 紐づいたEmotionがPositiveかチェックして、Trueならフラグを立てる。どのような感情を持っているか抽出 if ("Positive" in pnWord_dic['PosNeg'][i]): positiveFlag = True ## 紐づいたEmotionがNegativeかチェックして、Trueならフラグを立てる。どのような感情を持っているか抽出 if ("Negative" in pnWord_dic['PosNeg'][i]): negativeFlag = True ## 感情を表現している言葉とその感情の抽出 Exp.append(pnWord_dic['Word'][i]) emotion.extend(pnWord_dic['Emotion'][i]) ## データレコードの生成 temp.append(df_data['Tweet'][j]) temp.append(positiveFlag) temp.append(negativeFlag) temp.append(emotion) temp.append(Exp) results.append(temp) ## 処理終了確認用のprint文 print('Complete') ## CSVファイルに出力 with open("test_results.csv", "w", newline="")as f: writer = csv.writer(f) writer.writerows(results) ## 処理終了確認用のprint文 print('Complete') |
さて、ここまで来てようやくTweetと感情表現のマッチングができました。ここで内容を見てみましょう。
|
1 2 3 4 5 |
tt = pd.DataFrame(results, columns=['Tweet','Postive Flag','Negative Flag', 'Emotion', 'Word' ]) ## 176番目~177番目のデータが見やすいので、そこに表示を限定しています。 tt.drop(0).loc[176:177] |

さて、Positive FlagがTrueになっているデータを見ると、「尊敬」や「楽しさ」という感情が現れています。実際にこれらの感情は「見事」や「楽しむ」という表現が使われていますね。この「楽しむ」については、Tweet中に記載されている「楽しみ」を正規化した「楽しむ」が当たっています。
ここまでやってきて簡単にですが、感情分析ができる事が分かったかと思います。ですが、実はこの方法にはまだまだ問題が3つほど有ります。解決方法自体は次の機会で紹介したいと思いますので、今回は問題点の紹介だけにしておきます。
問題点
問題点1:形態素解析エンジンが単語を正しく認識できない
日本語感情辞書に「にやり」という喜びを表現する言葉が含まれています。今回、日本語感情辞書も形態素解析しているので、この「にやり」が、「に」と「やる」に分かれてしまいます。
つまり、形態素解析した結果が「に」と「やる」に分かれてしまうような例、例えば「一緒にやる」が喜びと分類されてしまいます。これは形態素解析エンジンに単語を登録する事で解決できるように思えますが、登録する単語は選定する必要があります。今回は日本語感情辞書も形態素解析しているので、動詞の変化形などを気にせずに抽出する事ができていますが、辞書に単語を登録するとその単語は形態素解析されなくなるため、動詞の変化形なども全て登録する必要が生じます。
他にも「にやり」を登録してしまうと、次は「一緒にやります」が「一緒」「にやり」「ます」と解析されるようになります。
問題点2:出現する語順を考慮していない
今回、Tweetの内容に対して日本語感情辞書の内容をマッチングする際、以下のように処理しています。
プログラムより抜粋
===================================
## 日本語感情辞書の内容がTweetに含まれる場合
if (set(pnWord_dic[‘Word’][i]).issubset(td[j])):
===================================
ここで、issubsetを使っています。これは何をしているか簡単に説明すると、「Tweetを形態素解析した結果の中に、日本語感情表現辞書を形態素解析した結果が含まれるか、語順は無視して比較」をしています。
具体的にどのような問題が起こるか見てみましょう。例えば以下の文章をご覧ください。(末尾の??は絵文字が文字化けしています。)
![]()
この文章の評判表現はどのようになっているでしょうか。
|
1 |
pd.DataFrame(tt.loc[11]).T |

感情として「喜び」になっています。そしてこのWordの[に,やる]という内容があります。しかし、この文章にはそのような表現はありません。
次にこの文章がどのように形態素解析されているかを確認します。ここでは、各単語がどのように分解されているかと、その単語の正規化されたものの両方を確認したいと思います。
まずは各単語がどのように分解されるかを確認します。
|
1 2 3 4 |
## 見やすいようにMeCabの出力フォーマットで別の指定をしたものを用意して結果の確認 adMeCab = MeCab.Tagger("-Owakati") adMeCab.parse('やべっちかスパサカでなでしこリーグやってくれたら、東京オリンピック盛りがる一因になると思うと。あっおやすみ??') |
![]()
![]()
今回使用したフォーマットは単語をスペース区切りにしてかつ区切った後の単語を正規化しないものです。
次に、これらの単語がどのように正規化されているかを確認します。これは先ほどTwitter分析をした際の内容が残っているのでそちらを再利用します。
![]()
![]()
![]()
表示されるフォーマットが異なり見づらいですが、使えないことは無いのでこのまま進めます。
さて、この文章に対して感情分析した際の結果、[に,やる]を確認したいと思います。まずは正規化されたものから「に」と「やる」を探します。
![]()
![]()
![]()
この時点で語順を考慮しなかった場合の問題に気づいた方もいるかも知れませんが、話を続けます。
次に、この「に」と「やる」が原文のどこに対応するかを見たいと思います。文章を各単語に分けただけのものを確認します。
![]()
![]()
このように評判とはまったく関係ない単語を拾ってきています。これを回避するには語順を考慮した処理にする必要があります。
問題点3:日本語感情辞書の正規化による重複
これは前2つに比べてさほど大きな問題ではありませんが記載しておきます。今回は日本語感情辞書を形態素解析しています。これにより、単語の重複が発生しています。以下がその例になります。
日本語感情辞書に「諦め」と「諦める」がそれぞれ登録されています。これらを形態素解析して正規化するとどのように解析されるか確認します。
|
1 2 |
print(m.parse('諦め')) print(m.parse('諦める')) |
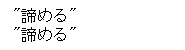
このようにどちらも「諦める」となります。結果、プログラム上で日本語感情辞書の内容がTweetに含まれるか確認するときに、「諦める」が2回当たります。これに関しては日本語感情辞書を正規化した後のデータを重複削除する事で解決できます。
終わりに
長くなりましたが、今回は自然言語処理のさわりとして記事を書かせて頂きました。今回やったことをまとめると以下になります。
- Pythonを使って少し言語処理に挑戦しました。
- ターゲットはTwitterを自然言語処理して感情分析です。
自然言語処理のさわりやイメージが何となくでも伝われば幸いです。また機会があれば、自然言語処理について記事を書きたいと思います。
以上です。ありがとうございました!
※TWITTER、TWEET(ツイート)、RETWEET(リツイート)、Twitter のロゴはTwitter, Inc.またはその関連会社の登録商標です。

執筆者プロフィール

- tdi AI・コグニティブ推進部
-
自然言語処理技術を用いた電子文書データの活用をテーマに日々活動しています。
最近は自然言語処理だけでなく、数値系データにも手を出しつつあります。
この執筆者の最新記事
 AI2019年9月17日Pythonでちょっとだけ自然言語処理に挑戦
AI2019年9月17日Pythonでちょっとだけ自然言語処理に挑戦


