
目次
はじめに
近年、「データの民主化」という言葉を目にする機会が増えました。「データの民主化」とは、「社内の誰もが簡単にデータを利用できるような環境」を構築することを意味しています。
最近では、「BIツールを用いて社内に溜まっているデータを活用しよう!」「新たな戦略を立てたりデータを可視化したりして新しいビジネス価値の発見をしよう!」といったように、データを活用する機会が増えたのではないでしょうか。Power BI Desktop(以下Power BI)に代表されるBIツールを使用することで、ローコードゆえに専門家なしで早く・簡単にそのような環境を準備することができるようになりました。今回は、Power BIを使ってデータの可視化に取り組んでいる方に向けた記事です。
誰もがデータを活用することができるようになった今、新たにこのような問題に直面した方はいませんでしょうか?
- Power BIを使ってダッシュボードを作ってみたが、データが多いと挙動が重くなってしまう
- データを速く更新したいのに、待機時間がとても長い
- Power Queryのデータ処理後、ダッシュボード反映に時間がとてもかかる
このような課題はPCスペックに依存する部分もありますが、データ処理の手順を変えるだけで変わる部分があることも事実です。Power BIのパファーマンスを最大限に引き出すためには、データの前処理方法と適切なモデリングがカギを握ります。今回は、Power BIのデータ処理を高速化するPower Queryデータ処理Tipsを紹介します。
Power BIのパフォーマンスはPower Queryのデータ処理の順番にかかっている
データを効率的に処理するために、最適な順序を理解することがPower BIでの作業効率を向上させるうえで非常に重要です。こちらの画像の右側の赤で囲われた部分がPower BIのPower Queryのデータ処理手順が記録されているものです。
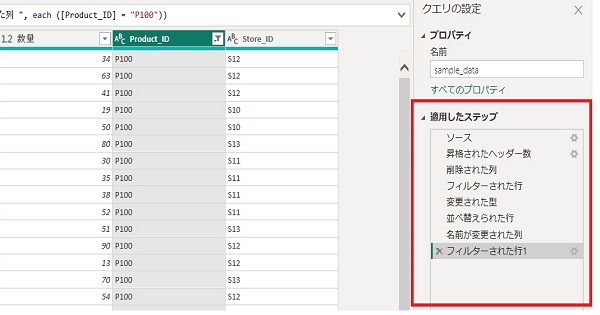
この「適用したステップ」の記録が多いほど、多くの処理を実施しているため時間がかかります。また、その処理の順番が効率的でないとさらに無駄に時間がかかってしまいます。例えば、目的のデータ可視化に不要な行が処理中にずっと残っていると、後続の処理でもその不要な行が使用されてしまいます。
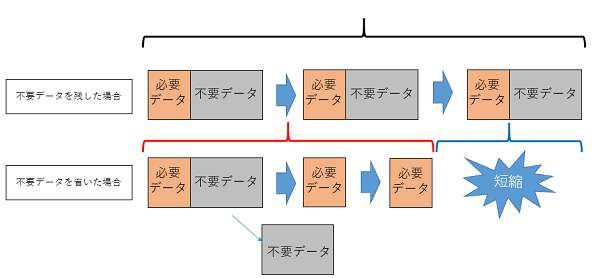
上の図のように、不要なデータを残したまま処理を続けると、無駄な処理時間がかかってしまっています。また、データ処理の順番を間違えれば、不必要に時間がかかってしまいます。早い段階で不要なデータを除外すれば、後続の処理でメモリも時間も節約することができます。
押さえておきたいデータ前処理Tips4選
それでは、データ処理を効率化する前処理Tipsを4つ紹介します。上から順に実施することをお勧めいたします。
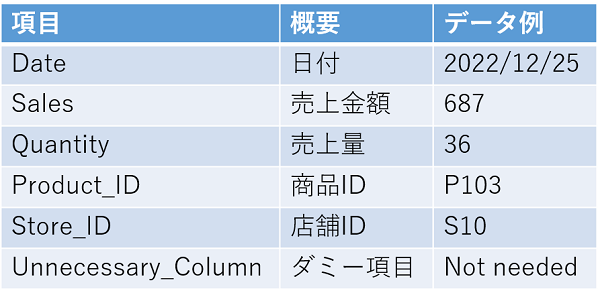
今回は、「店舗・商品別売り上げ」のテストデータを使用します。データ内容は以下のようになっています。
Tips1 : 不要な列の削除は初期の段階で
初期段階で不要なデータを削除しておくことで、後続の処理負荷を軽減できます。今回は、以下の図のようなテストデータを準備して実施します。
左端のindexが入ったカラムを削除します。
カラム名をクリック→「列の削除」をクリックします。
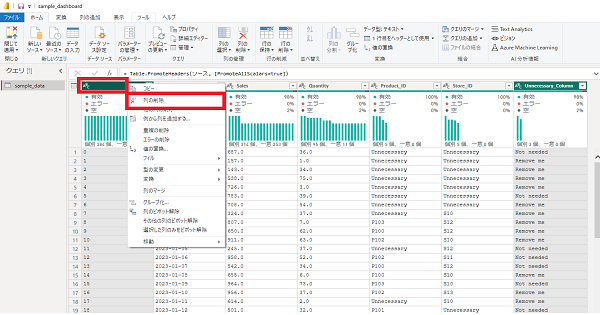
同様に「Unnessesary_Column」も削除します。
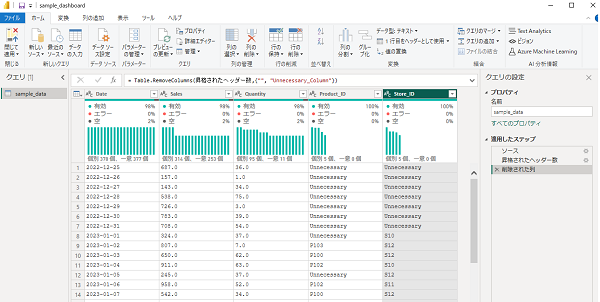
これで不要な列を削除することができました。
Tips2 : 事前フィルタリングは超重要
必要なデータのみを対象に処理を行うことで、効率性を向上できます。
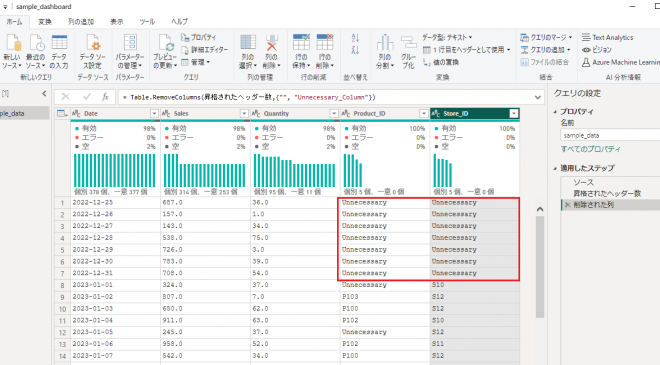
先ほど列を削除しましたが、「Product_ID」「Store_ID」には「Unneccesary」というデータが含まれています。これを含んだ行を削除します。
カラム名の横「▼」をクリックするとそのカラムに含まれるユニークなデータが表示されます。その中で今回不要である「Unneccesary」の項目のチェックを外します。
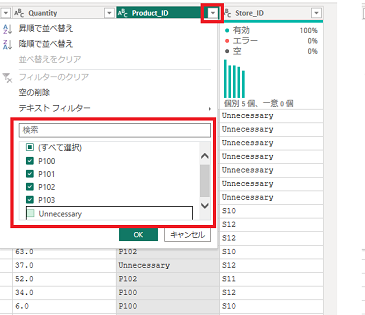
「Store_ID」も同様に実施します。
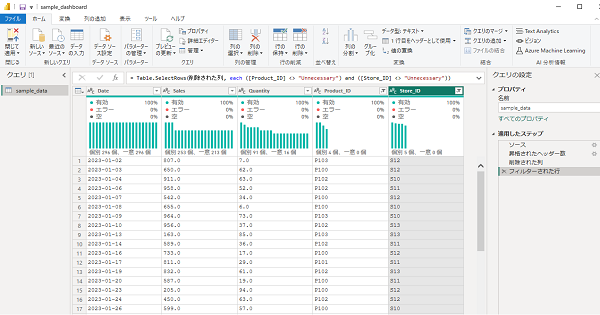
これでUnneccesaryを含む行を削除できました。
Tips3 : データ型の選択は丁寧に
データ型はメモリ使用量に直接影響します。適切な方を選択することで、最低限必要なメモリだけを使用して処理を実施できます。
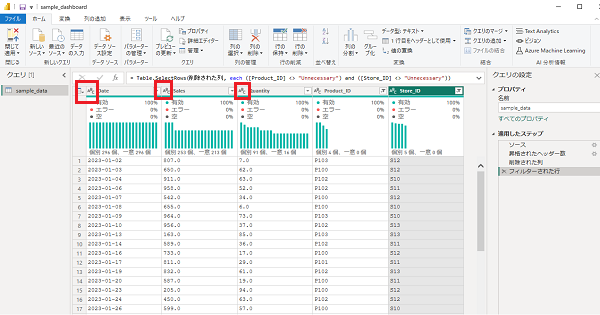
現在のデータ型を確認してみると「Date」「Sales」「Quantity」がすべて文字列型になっています。本来はDate型、数値型など適切に変更するべきです。
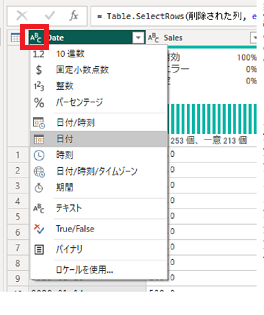
適切に型を変更しましょう。「Date:日付」「Sales:10進数」「Quantity:10進数」に変更してください。
これで、適切なデータ型に変更することができました。
Tips4 : ディメンションテーブルの作成は「参照」で
Power BIでは”スタースキーマ”が基本です。 スタースキーマについてはこちらの公式ドキュメントをご参照ください。
ファクトテーブルをコピーしてディメンションテーブルを作成しますが、その時にデータのコピー方法に「参照」と「複製」があります。「参照」と「複製」の違いは以下の表のとおりです。
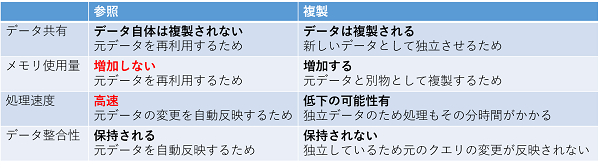
簡単にまとめると、
「複製」を選択すると、元のデータを複製し別データとして扱うので、メモリ使用量がその分増え、処理時間も増えてしまいます。
「参照」の場合は、元データをそのまま引き継ぎ変更を自動反映するので、追加のメモリ使用がありません。また、一度の処理時間ですべて反映されるのでパフォーマンスも向上します。
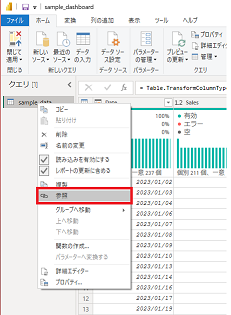
特に大規模なデータセットの場合はこの小さな注意でパフォーマンスに大きく影響します。ディメンションテーブルは事実データを分析するために多様なデータが必要ですので、参照後さらに重複を削除する処理を入れる必要があります。
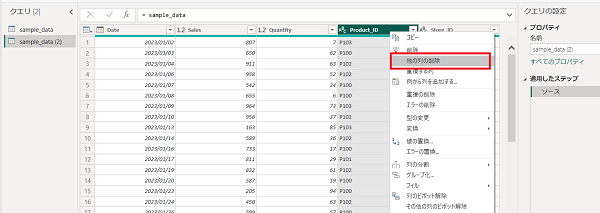
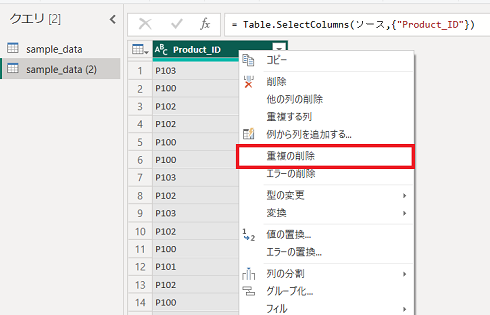
Product_IDのみのディメンションテーブルを作成するために、「他の列の削除」→「重複の削除」を実施します。
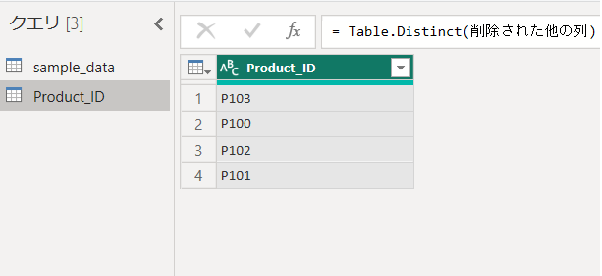
出来ました。テーブルも適切な名前に変更してあげましょう。
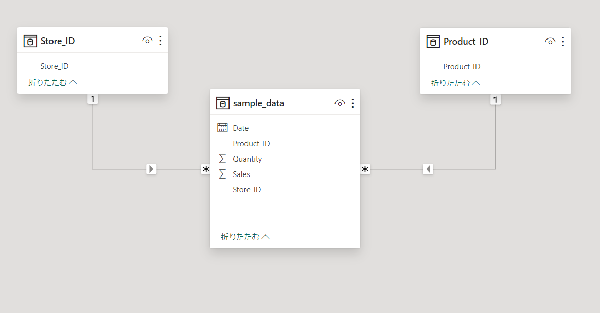
Store_IDにも同様の処理を実施してスタースキーマを作成します。
完成です。
最後に
今回はPower BIのデータ処理で実施したい4つのTipsを紹介いたしました。いかがでしたでしょうか。
普段何となくデータ前処理を実施し想像以上に処理時間がかかっている方はぜひ、上記のTipsを実践してみてください。

執筆者プロフィール

- AI & データマネジメント推進部
-
データ分析やAI、統計などの領域が好きです。
BIツールの導入支援やAIサービスのPoC・開発を仕事にしています。


