
Watson Discovery について
IBM Cloudの提供するWatson Discoveryとは、IBMの開発するAI、Watsonを利用した検索エンジンです。膨大なテキストデータを分析し、情報の検索や分析を支援してくれるサービスです。大量のデータの中から質問に対する回答を見つけたり、関連度の高いデータを探したりすることができます。また、Watson Discoveryに対して「この質問に対する回答はこれが適切/これは関係ない」というデータを与えトレーニングすることで、回答の精度を上げることができます。
IBM Cloudの各種サービスのAPIを使用するためのライブラリが各言語・環境向けに提供されており、ユーザーは自由にUIを開発することができます。
今回はNode.js向けのライブラリ、watson-developer-cloud を使ってWatson DiscoveryのAPIを叩き、コレクションの状態を取得したり、データを検索するサーバ/クライアント構成のWebアプリを作ってみたいと思います。
Watson Discoveryの準備
まずはIBM Cloud上にWatson Discoveryのインスタンスを作成します。ダッシュボードの[Create resource]をクリックし、フィルターに「ディスカバリー」と入力します。日本語環境だと”Discovery”と入力しても検索に引っかかりませんでした。
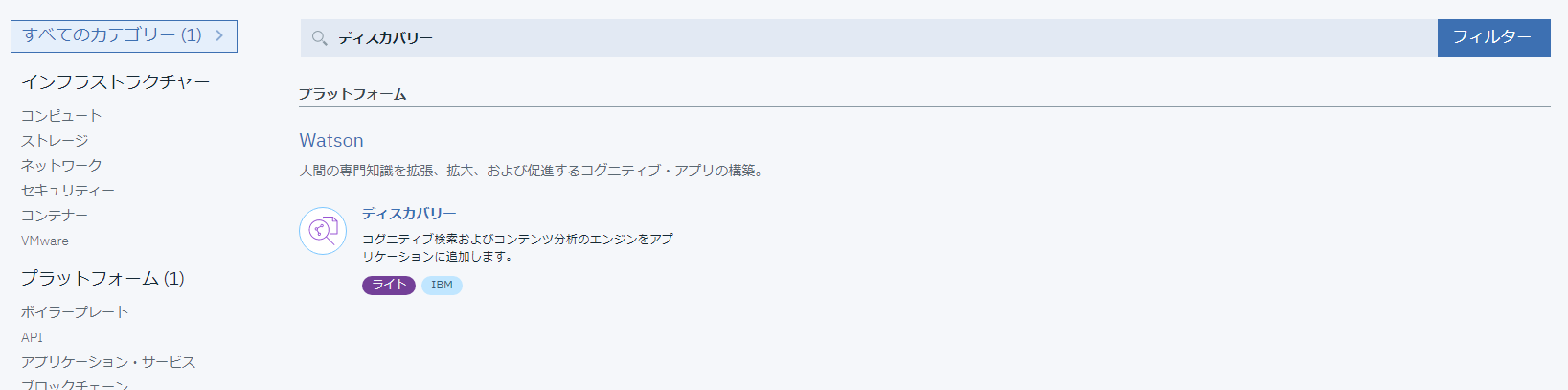
サービス名を適当に入力し、[作成]クリックでインスタンスが立ち上がります。
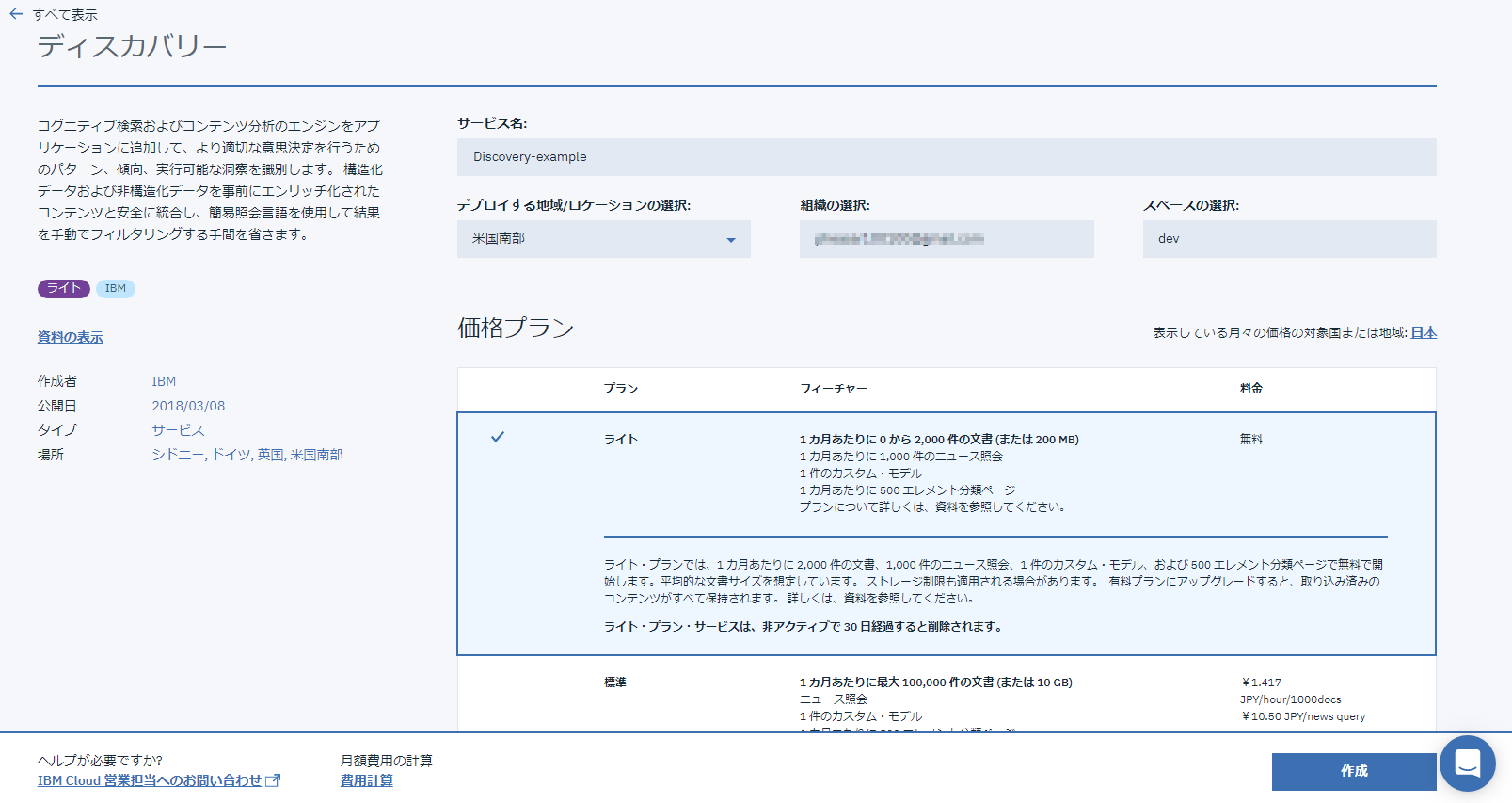
作ったインスタンスの認証情報を確認します。インスタンスの管理画面で、左側のメニューから[サービス資格情報]を選択し、ページ下部の[資格情報の表示]をクリックすると認証情報が表示されます。
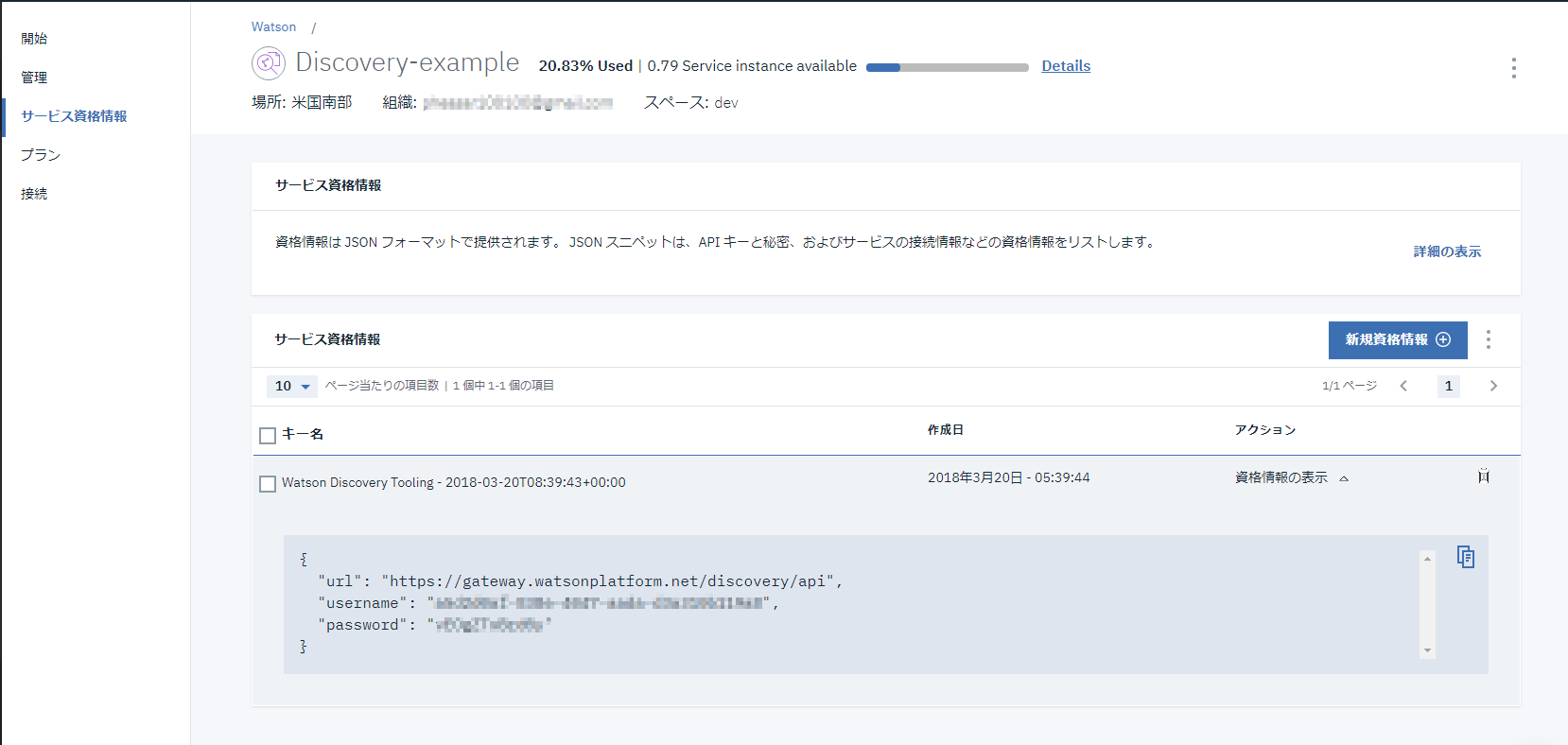
このうち”username”と”password”をメモしておきます。
次に、「コレクション」を作成します。コレクションとは、分析するドキュメントの保存場所のことです。作成したWatson Discoveryのコンソールで[Create a data collection]をクリックし、任意のコレクション名を入力 => [Create]です。
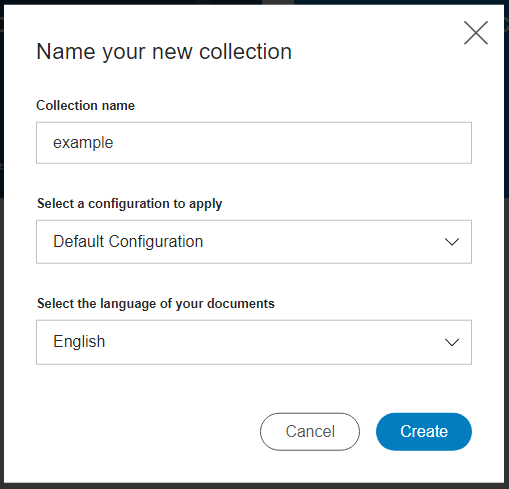
そのままコレクションの画面に遷移するので、画面にある[Use this collection in API]をクリック、表示された”Collection Id”と”Environment Id”をそれぞれメモしておきます。
コレクションにデータを投入します。サンプルとして、Twitterで「情報技術開発」というワードで検索したときの結果を、JSONファイルとして500件弱用意しました。
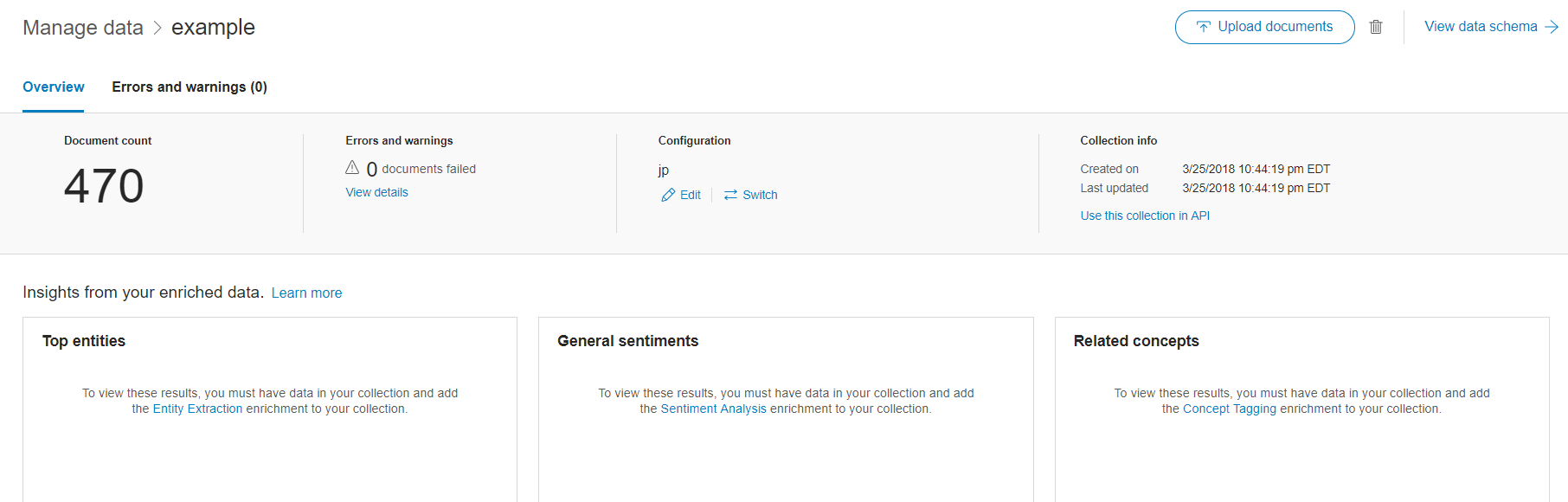
これでWatson Discovery側の準備は完了です。
Webアプリ開発
今回は、以下の動作が可能なアプリを作成することにします。
- コレクションの状態を確認
コレクションに格納されているドキュメントの数、トレーニングの状況等の情報を確認 - コレクションに対してクエリを投げ、結果を表示
自然言語照会(話し言葉)での質問に対する回答候補を表示 - コレクションのトレーニング
クエリと結果の関連度(トレーニングデータ)をWatson Discoveryに保存
APIを叩くサーバーサイドでは、Expressを使います。フロントエンド側は特に凝ったことをしないので、手軽に導入できるVue.jsを使います。
プロジェクトのファイル構成はこんな感じです。express-generatorが吐き出す構成を基本に、app配下にフロントエンド側のコードを配置しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
├─ bin │ └─ www ├─ app.js ├─ routes │ └─ api │ └─ discovery.js ├─ views │ ├─ error.jade │ ├─ index.jade │ └─ layout.jade ├─ public │ ├─ javascripts │ │ └─ bundle.js │ └─ stylesheets │ └─ style.css ├─ app │ ├─ src │ │ └─ javascripts │ │ ├─ components │ │ │ └─ Discovery.vue │ │ └─ index.js │ └─ config │ └─ webpack.config.js ├─ package.json └─ yarn.lock |
環境設定
Watson DiscoveryのAPIを叩くには、先ほどメモした4つの情報が必要です。
- username
- password
- environment_id
- collection_id
これらを環境変数として設定します。システムの環境変数は汚したくないので、dotenvを使います。(Project root)/.envにそれぞれ記述します。
|
1 2 3 4 |
USERNAME=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx PASSWORD=xxxxxxxxxxxx ENVIRONMENT_ID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx COLLECTION_ID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx |
サーバーサイド実装
Watson DiscoveryのAPIは基本的に公式のドキュメントを見ればよいですが、一部更新が追いついていないものもあるので、そちらについてはソースコードを読んで目的のAPIを探す必要があります。
エンドポイントは以下のように設定します。
| メソッド | エンドポイント | 機能 |
|---|---|---|
| GET | /api/discovery/status | コレクションの状態を確認 |
| GET | /api/discovery/query | クエリを発行 |
| POST | /api/discovery/training | トレーニングデータを追加 |
|
1 2 3 4 5 6 7 8 9 |
... const discovery = require('./routes/api/discovery') ... app.use('/api/discovery', discovery) ... |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
const express = require('express') const router = express.Router() const Promise = require('bluebird') const DiscoveryV1 = require('watson-developer-cloud/discovery/v1') require('dotenv').config() const discoveryAuth = new DiscoveryV1({ username: process.env.USERNAME, password: process.env.PASSWORD, url: 'https://gateway.watsonplatform.net/discovery/api/', version: '2017-09-01', }) const discovery = Promise.promisifyAll(discoveryAuth) const env = { environment_id: process.env.ENVIRONMENT_ID, collection_id: process.env.COLLECTION_ID, } router.get('/status', async (req, res, next) => { try { const result = await discovery.getCollectionAsync(env) res.json(result) } catch (error) { res.status(500).json(error) } }) router.get('/query', async (req, res, next) => { try { const reqParam = JSON.parse(JSON.stringify(env)) reqParam.query = req.query.keyword const result = await discovery.queryAsync(reqParam) res.json(result.results) } catch (error) { res.status(500).json(error) } }) router.post('/training', async (req, res, next) => { try { const params = req.body.params const relevance = params.relevance ? 10 : 0 const keyword = params.keyword const example = { document_id: params.id, relevance: relevance, } // すでに同じ質問データがないか検索 const result = await discovery.listTrainingDataAsync(env) const queryId = result.queries .filter((query) => query.natural_language_query === keyword) .map((query) => query.query_id) if (queryId.length !== 0) { // データがあれば、exampleを追加する const reqParam = JSON.parse(JSON.stringify(env)) reqParam.query_id = queryId reqParam.document_id = example.document_id reqParam.relevance = example.relevance const result = await discovery.createTrainingExampleAsync(reqParam) } else { // データが無ければ、新規追加 const reqParam = JSON.parse(JSON.stringify(env)) reqParam.natural_language_query = keyword reqParam.examples = [example] const result = await discovery.addTrainingDataAsync(reqParam) } res.json(result) } catch (error) { res.status(500).json(error) } }) module.exports = router |
watson-developer-cloudのAPIはコールバック形式の関数なので、可読性と保守性のためにbluebirdでPromise化して使っています。Promise化した関数は、本来の関数名に”Async”を付加すると使えます。使っているAPIは以下の3つです。
|
1 2 3 4 5 6 7 8 9 |
router.get('/status', async (req, res, next) => { try { const result = await discovery.getCollectionAsync(env) res.json(result) } catch (error) { res.status(500).json(error) } }) |
Watson Discoveryから、以下のような形式のJSONが返されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
{ "collection_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "name": "democollection", "description": "this is a demo collection", "created": "2015-08-24T18:42:25.324Z", "updated": "2015-08-24T18:42:25.324Z", "status": "available", "configuration_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "language": "en", "document_counts": { "available": 1000, "processing": 20, "failed": 180 }, "disk_usage": { "used_bytes": 260 }, "training": { "total_examples": 54, "available": true, "processing": false, "minimum_queries_added": true, "minimum_examples_added": true, "sufficient_label_diversity": false, "notices": 13, "successfully_trained": "2017-02-08T14:18:22.786Z", "data_updated": "2017-02-10T14:18:22.786Z" } } |
今回はそのままフロントにレスポンスしていますが、本番運用では”collection_id”や”configuration_id”を除く等、必要なデータだけを返却するようにサーバ側で処理したほうがよいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
router.get('/query', async (req, res, next) => { try { const reqParam = JSON.parse(JSON.stringify(env)) reqParam.query = req.query.keyword const result = await discovery.queryAsync(reqParam) res.json(result.results) } catch (error) { res.status(500).json(error) } }) |
フロントからリクエストデータ”keyword”を受け取り、パラメータに付加してクエリを投げます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
router.post('/training', async (req, res, next) => { try { const params = req.body.params const relevance = params.relevance ? 10 : 0 const keyword = params.keyword const example = { document_id: params.id, relevance: relevance, } // すでに同じ質問データがないか検索 const result = await discovery.listTrainingDataAsync(env) const queryId = result.queries .filter((query) => query.natural_language_query === keyword) .map((query) => query.query_id) if (queryId.length !== 0) { // データがあれば、exampleを追加する const reqParam = JSON.parse(JSON.stringify(env)) reqParam.query_id = queryId reqParam.document_id = example.document_id reqParam.relevance = example.relevance const result = await discovery.createTrainingExampleAsync(reqParam) } else { // データが無ければ、新規追加 const reqParam = JSON.parse(JSON.stringify(env)) reqParam.natural_language_query = keyword reqParam.examples = [example] const result = await discovery.addTrainingDataAsync(reqParam) } res.json(result) } catch (error) { res.status(500).json(error) } }) |
Watson Discoveryをトレーニングするために必要なデータは、検索した語句・検索結果のドキュメントID・関連度の3つです。関連度は数値で表現され、数値が大きいほど質問と回答の関連が高いことを表します。今回は単純に、関連がある(10)/ない(0)の2通りの関連度を設定することにします。フロント側からはBoolean値が送られてくるので、それに応じてWatson Discoveryへ送信するパラメータを設定します。
最終的に送信するデータは以下のような形式になります。
|
1 2 3 4 5 6 7 8 9 |
{ "natural_language_query": "質問文", "examples": [ { "document_id": "検索結果(ドキュメント)のID", "relevance": 関連度(0 or 10) } ] } |
また、Watson Discoveryでは、同一の質問(natural_language_query)に対するトレーニングデータは重複登録できず、一度登録した質問に対しては、以降examplesを追加していく形になります。そのため、データの追加前に既存のデータを検索し、質問が見つかった場合はexampleをマージするAPIを使っています。
以上でサーバ側の実装は完了です。エラー処理が雑ですが、本筋ではないのでこのまま進めます。
フロントエンド実装
簡単なアプリなので、コード量も少ないです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
<template> <div class="main"> <div class="discovery-status"> <button @click="getStatus">Check Status</button> <table> <tbody> <tr> <th>状態</th> <td>{{status.status}}</td> </tr> <tr> <th>ドキュメント数</th> <td>{{status.document_counts.available}}</td> </tr> <tr> <th>トレーニングデータ数</th> <td>{{status.training_status.total_examples}}</td> </tr> <tr> <th>トレーニング結果の利用</th> <td>{{status.training_status.available ? 'OK' : 'NG'}}</td> </tr> </tbody> </table> </div> <div class="discovery-query"> 検索 <input type="text" v-model="keyword" @keyup.enter="search" /> <p>結果:</p> <ul class="query-results"> <li class="query-result" v-for="result in results"> <p>{{result.text}}</p> <div class="training-buttons" v-if="!result.trained"> <button @click="training(result, true)">関係あり</button> <button @click="training(result, false)">関係なし</button> </div> <hr /> </li> </ul> </div> </div> </template> <script> import axios from 'axios' export default { data() { return { status: { status: '?', document_counts: { available: 0, }, training_status: { total_examples: 0, available: '', }, }, keyword: '', results: [], } }, methods: { async getStatus() { const res = await axios.get('/api/discovery/status') this.status = res.data }, async search() { const res = await axios.get('/api/discovery/query', { params: { keyword: this.keyword, } }) this.results = res.data.map((result) => { result.trained = false return result }) }, async training(result, relevance) { await axios.post('/api/discovery/training', { params: { keyword: this.keyword, id: result.id, relevance: relevance, } }) result.trained = true }, }, mounted: function () { this.getStatus() } } </script> <style scoped lang="scss"> .discovery-status { table { margin-top: 10px; border-collapse: collapse; th, td { padding: 5px; border: 1px solid; text-align: left; } td { width: 50px; } } } .discovery-query { margin-top: 20px; } </style> |
画面はこんな感じになります。

語句を入力し、Enterで検索できます。テンプレートの以下の部分で、検索用のボックスと、検索結果のテキスト・トレーニング用のボタンを表示しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="discovery-query"> 検索 <input type="text" v-model="keyword" @keyup.enter="search" /> <p>結果:</p> <ul class="query-results"> <li class="query-result" v-for="result in results"> <p>{{result.text}}</p> <button @click="training(result.id, true)">関係あり</button> <button @click="training(result.id, false)">関係なし</button> </li> </ul> </div> |
以下は、画面表示 > 検索 > トレーニングボタンクリック > ステータス更新 の様子です。

トレーニング後、[トレーニングデータ数]欄の数字が増えているのがわかります。また、[トレーニング結果の利用]欄は、トレーニングを行った結果が検索に反映されているかどうかを表示しています。
この反映基準についてですが、公式ドキュメントによると、
Discovery が評価の適用を開始するためには、トレーニングが以下の最小要件を満たす必要があります。
・最低限 49 個、できればもっと多くの照会をトレーニングする必要があります。Watson は、トレーニングのためにもっと多くの照会が必要な場合、フィードバックで知らせます。
・使用可能な評価
RelevantおよびNot relevantの両方を結果に適用する必要があります。Relevant文書のみを評価すると、必要なデータが提供されません。
とのことで、少なくとも検索 > 評価を49回繰り返し、データが溜まるまで結果は反映されないようです。
49回分のデータが追加され、トレーニングが完了すると、Watson Discoveryのコンソール上の3つのチェックリストが埋まります。
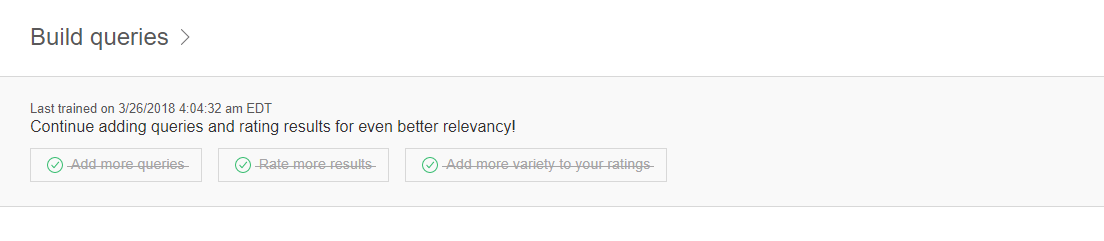
このようにしてトレーニングを繰り返すことで、検索に対する回答の精度が向上していきます。
最後に
今回はNode.jsからの利用でしたが、他にもPython、Swift、Java、.NET等、さまざまな環境で利用できるSDKが開発されています。使い方も単純で、ドキュメントの日本語化も日々進んでいるようですので、取っ掛かりはつかみやすいと思います。
また、まだ日本語には対応していませんが、Watson Discoveryにはテキストデータから感情を読み取ったり、性格を分析することのできる機能もあります。
これらが日本語に対応すれば、例えば顧客のアンケートデータから感情を抽出し、隠れた需要を見出す等といったこともWatson Discoveryで実現できるようになるかもしれません。

執筆者プロフィール

- tdi ソリューション企画部
- DAiS Signage、手続きNavi等の開発に携わっているバック/フロント両刀のWebエンジニア。好きなものは自動化で、最近はホームオートメーションに興味あり。



