こんにちは、戎谷です。今回はAmazon Athenaを使ってみたいと思います。
目次
Amazon Athenaとは
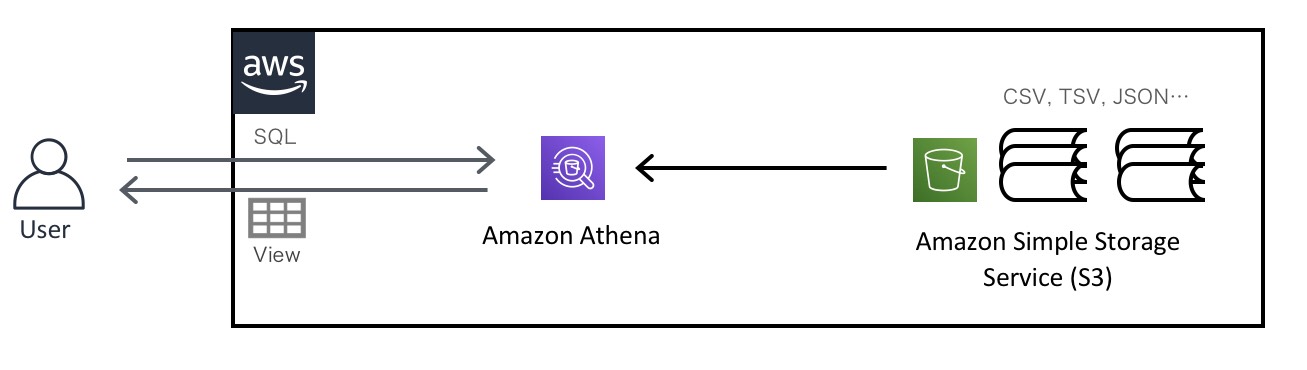
Amazon Athenaとは、Amazon Web Services(AWS)のサービスの一つで、「標準 SQL を使用して Amazon Simple Storage Service (S3) でのデータの直接分析を簡易化するインタラクティブなクエリサービス」です。
つまり、AWSのS3ストレージに置いてあるCSVファイルやJSONファイルに対して直接SQLを発行し、クエリの結果を得ることができるサービスです。
Amazon Athenaを使ってみよう
実際に使ってみましょう。
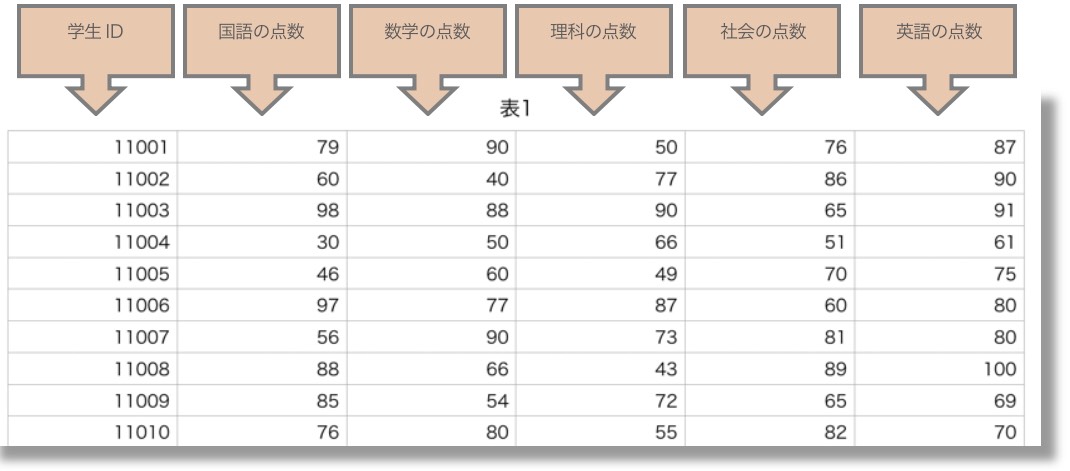
例えば、S3に次のような生徒ごとの5教科のテスト結果の点数が書かれたcsvファイルがあるとします。このcsvファイルがAmazon Athenaからどう見えるか、みてみましょう。
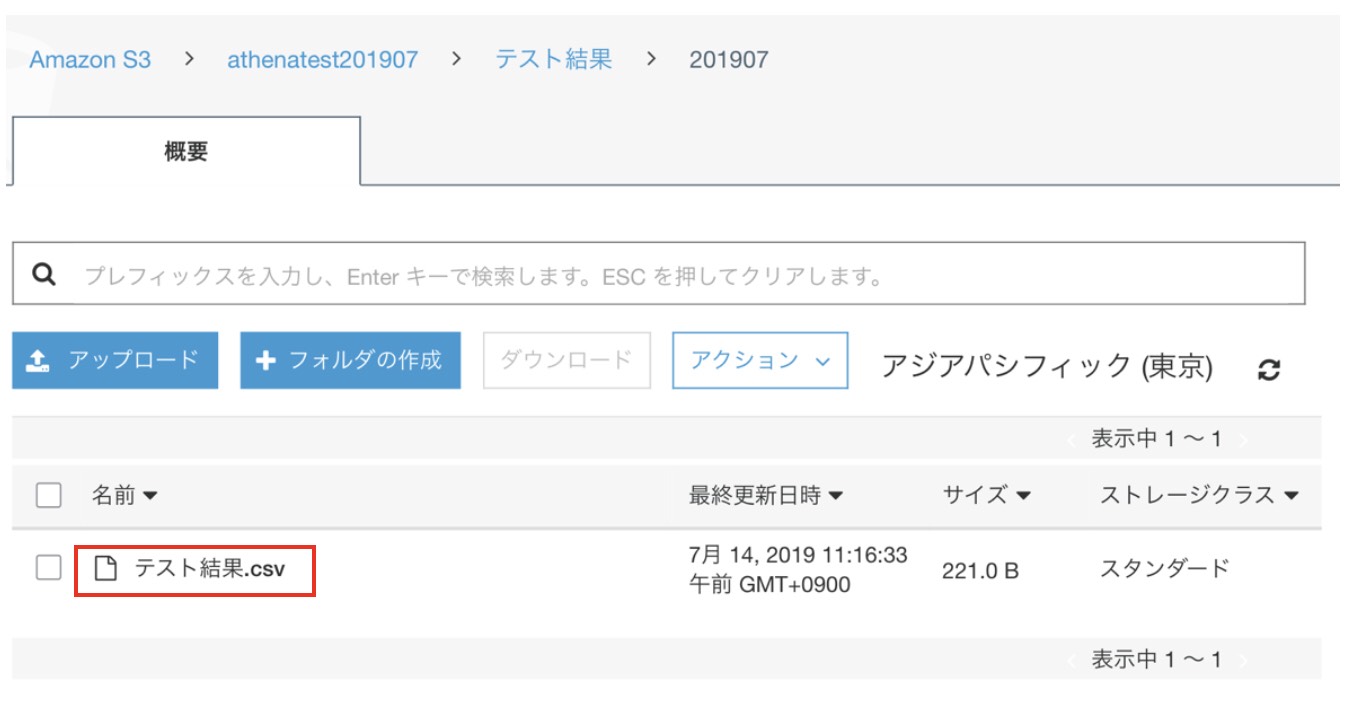
まずはS3にバケット・フォルダを作成し、Amazon Athenaからクエリアクセスしたいファイルを配置します。
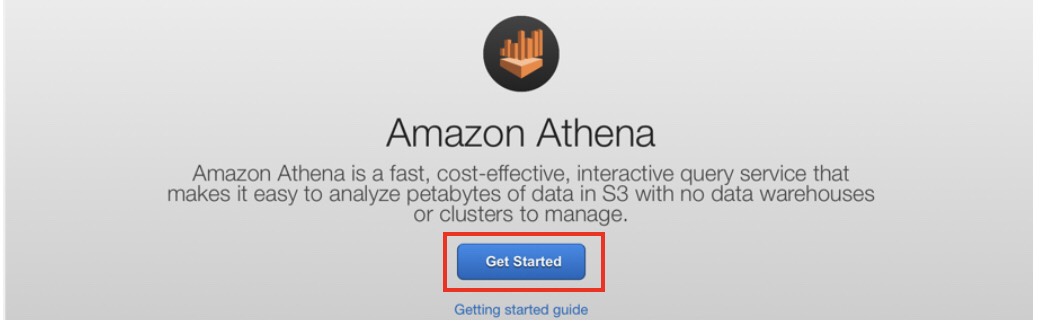
ここからはAmazon Athenaサービスを設定していきます。 「Get Started」ボタンから始めます。
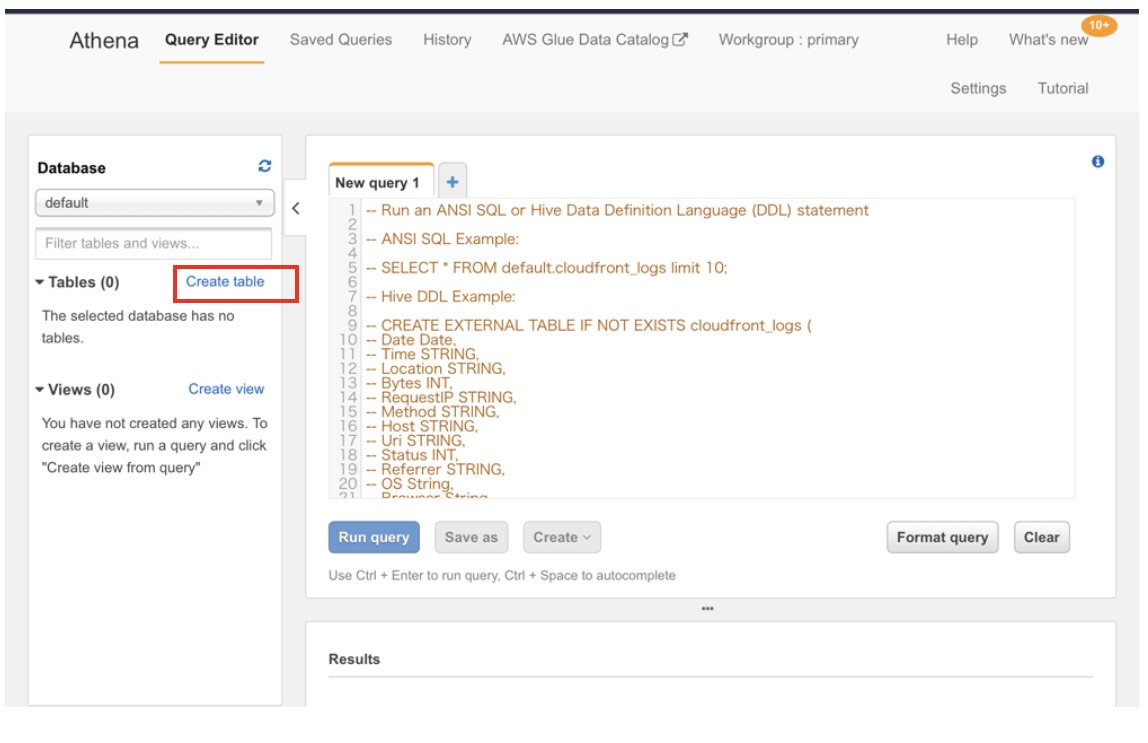
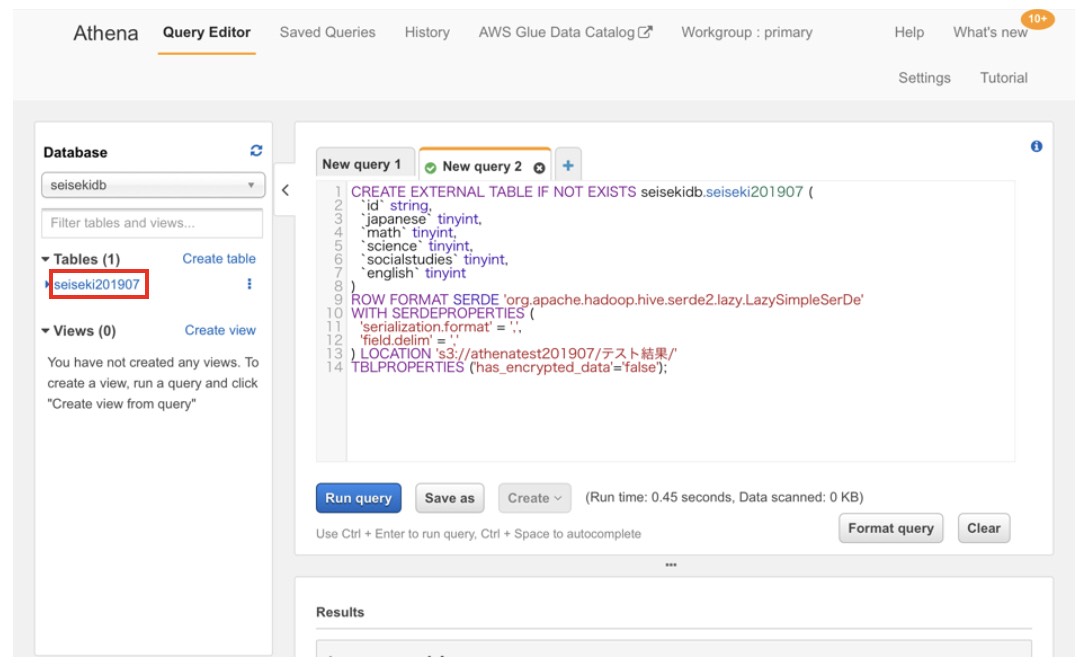
次に、CSVを見るためのスキーマを定義していきます。「Create table」を押します。
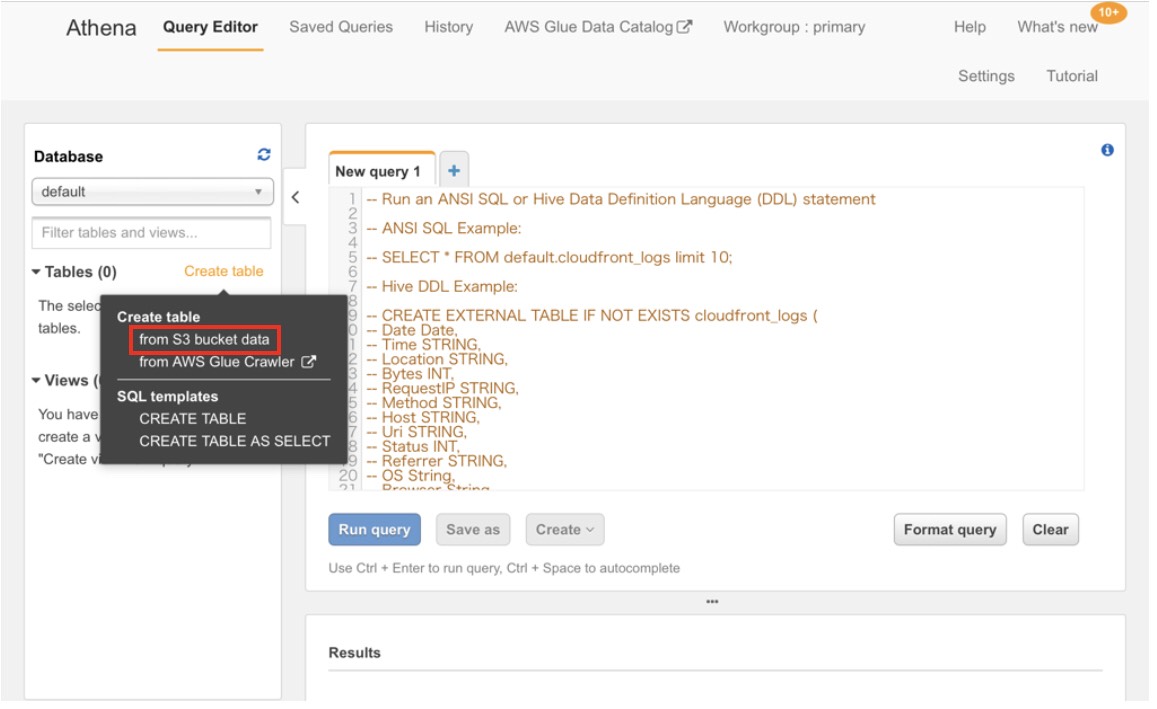
「from S3 bucket data」を選びます。
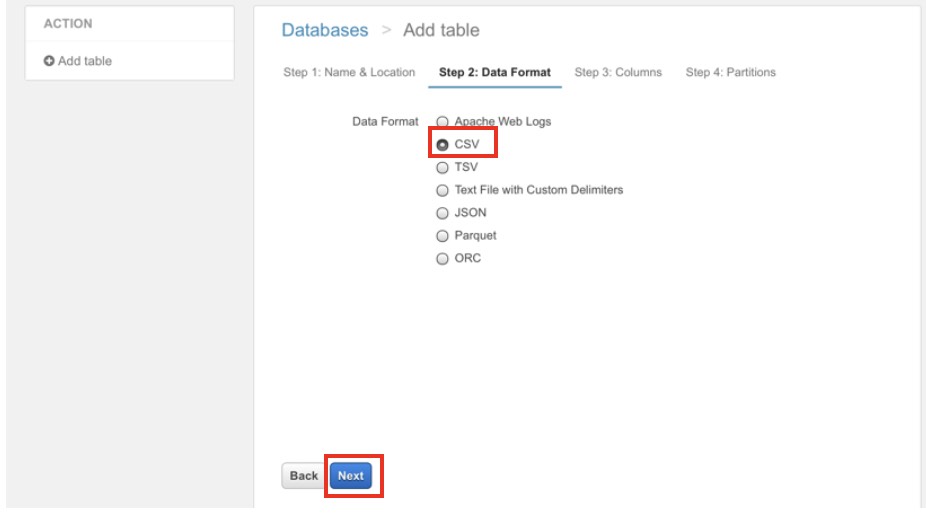
次にスキーマ定義を行います。
データフォーマットを「csv」に指定し、「Next」ボタンで進みます。
次にカラム(列)を指定します。
カラム名と属性を指定し、「Add a column」ボタンでカラムを追加していきます。
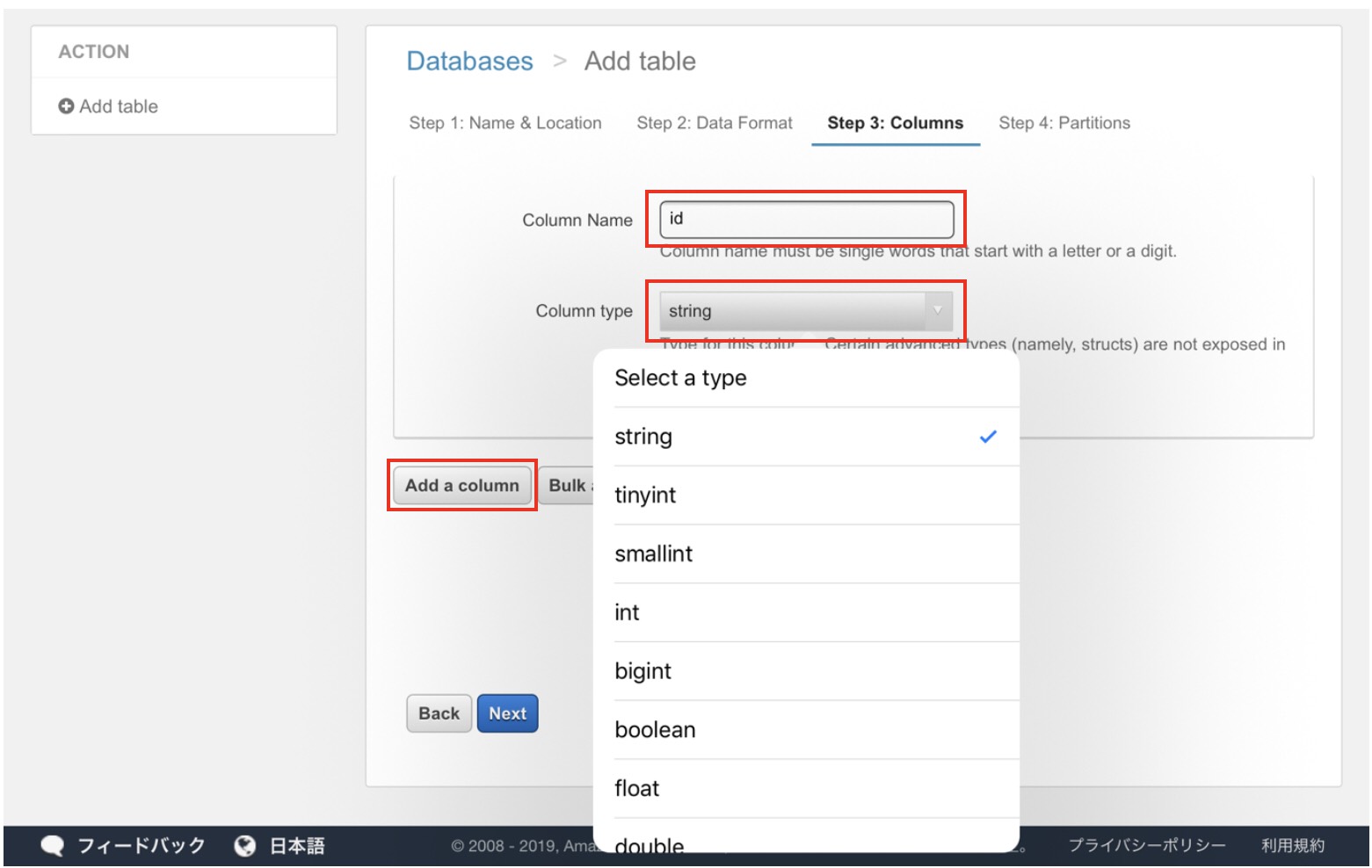
これを繰り返し、下記のように、カラムと属性を指定しました。

「Next」ボタンで進みます。
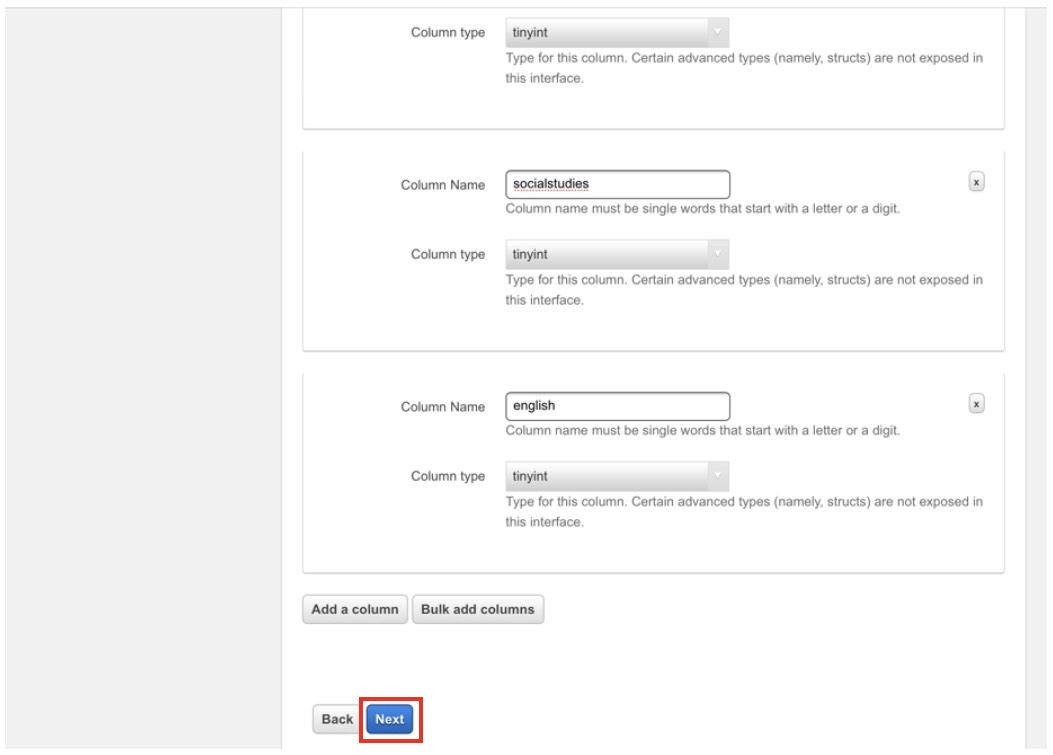
※なお、カラム定義は下記のように「Bulk add columns」で下記のように指定することでカラムの一括定義もできます
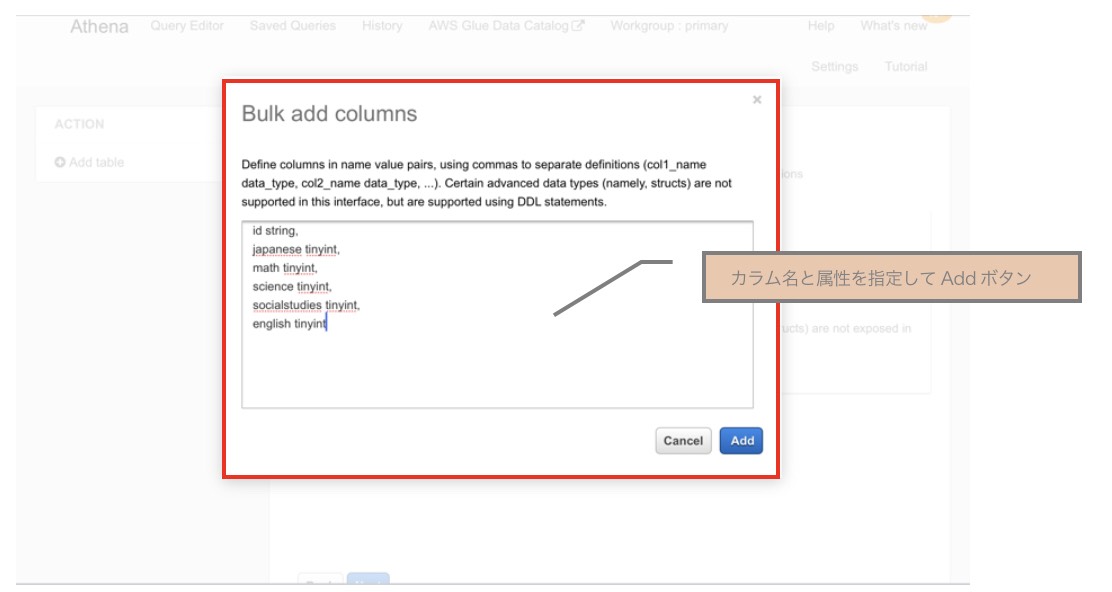
「Create table」ボタンを押下します。
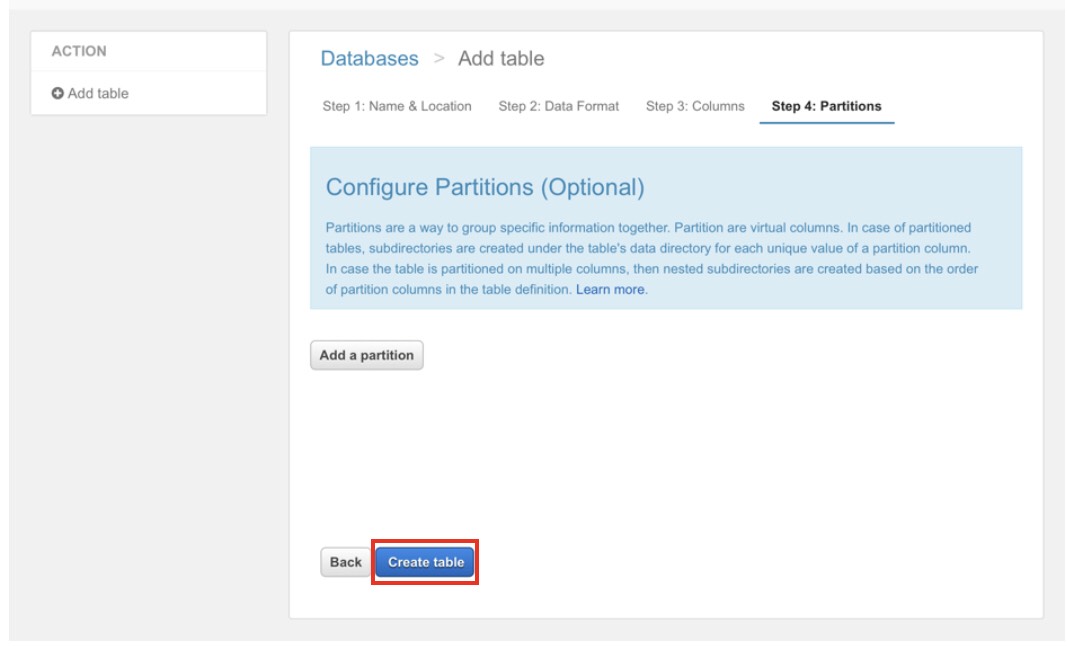
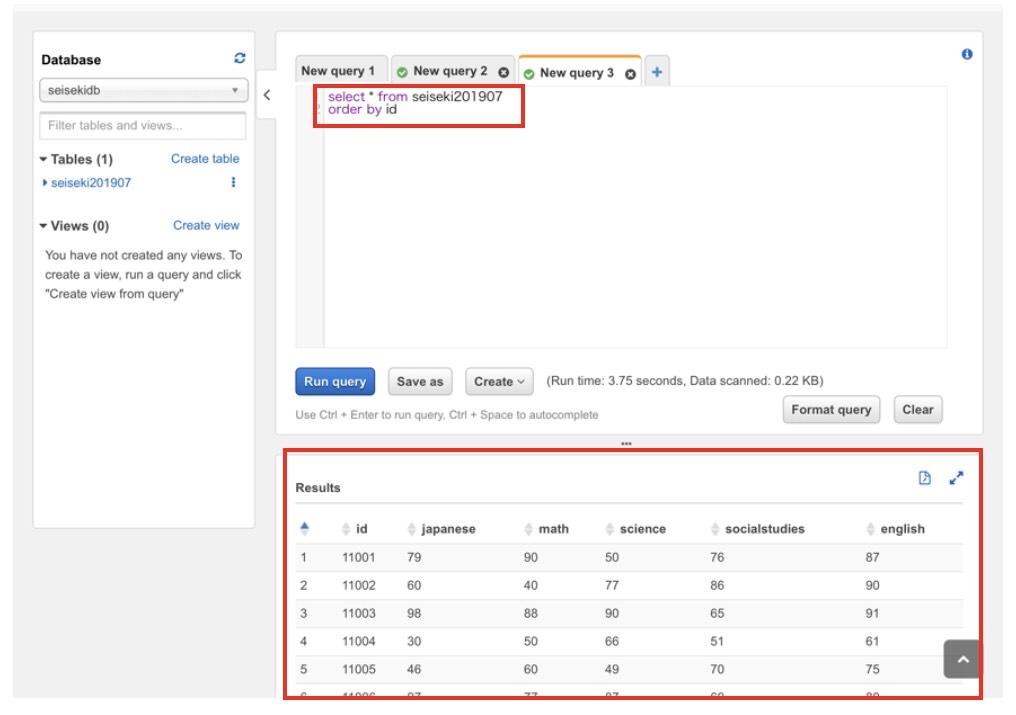
テーブルが作成されました。
SQLを発行し、 csvファイルの内容が表示できることが分かると思います。 使い方は簡単ですね。COUNTなどの関数や複数テーブルのJOINも行えます。
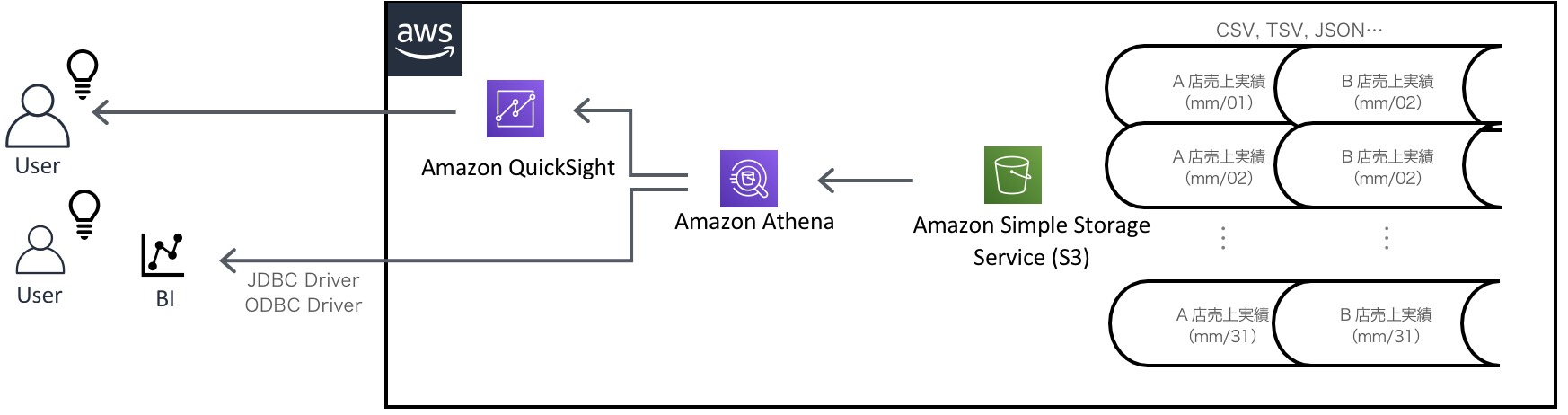
Amazon Athenaの使いどころ
このサービスは、S3のファイルを手軽に集計・分析したい時に役に立ちます。 例えば、下記のような用途で使えるのではないかと思います。
- 日別・店舗別の売上実績ファイル群の集計や分析
- システムのアクセスログの集計や分析
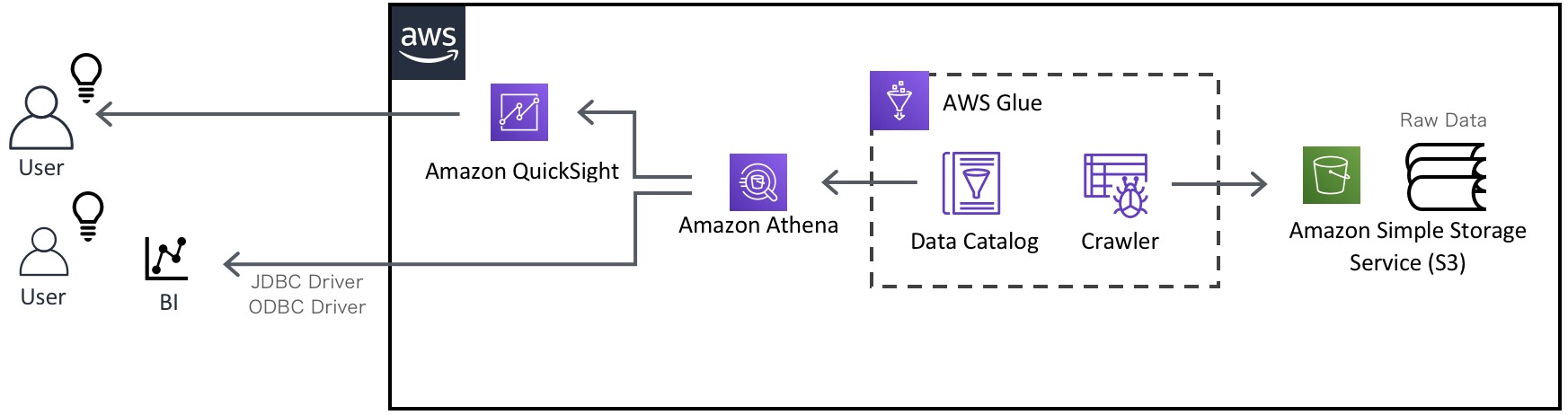
S3のバケット・フォルダを対象としているため、そのバケット・フォルダに新たに格納されたファイルはAmazon Athenaから見ることができます。本来データベースならばデータロード処理が必要になりますが、Amazon Athenaはデータロード処理は不要です。
Amazon Athenaの結果をレポートにまとめたいとき
クエリの結果を手作業でレポートにまとめてもよいですが、Amazon QuickSightなどのAWSのBIサービスや、AWSが公開しているJDBCドライバ・ODBCドライバを経由して、オンプレミスのBIツールと連携したりして、傾向分析を行うこともできます。
JDBCドライバ:https://docs.aws.amazon.com/ja_jp/athena/latest/ug/connect-with-jdbc.html
ODBCドライバ:https://docs.aws.amazon.com/ja_jp/athena/latest/ug/connect-with-odbc.html
Amazon Athenaで取り扱うファイルが非整形のとき
Amazon Athenaで取り扱うデータは整形されていることが前提となります。例えば1行目にヘッダ行が付いているようなデータはAmazon Athenaではヘッダ行もデータとして扱われるため、都合が悪くなります。
そのように、取り扱うファイルがもし非整形ファイル(生データのまま)だったとしても、例えばAWS GlueなどのETLサービスで整形化し、データカタログ化することで、Amazon Athenaで取り扱うことができます。
AthenaとAWS Glueを併用する際のベストプラクティス :https://docs.aws.amazon.com/ja_jp/athena/latest/ug/glue-best-practices.html
Amazon Athenaの料金とコスト削減・パフォーマンス向上方法
料金を見てみましょう。※リージョンはアジアパシフィック(東京)
Amazon Athenaに固定料金はなく、課金はクエリでスキャンされたデータに対する課金のみで、1TBあたり5USDです。 これを基準にスキャンデータ10MB単位で按分した金額が課金されます。例えば、10MBのデータに1000回アクセスした場合、料金は5円程度となります。
Amazon AthenaはS3に直接データをクエリアクセスするため、Amazon Athena自身のストレージ料金はありません。 また、DDLに関するSQL(CREATE TABLE文、ALTER TABLE文など)や、失敗したクエリは課金対象外です。
料金:https://aws.amazon.com/jp/athena/pricing/
もし、取り扱うデータ量が多い場合の料金面・パフォーマンス面への考慮も紹介したいと思います。Amazon Athenaでは、gzipなどの圧縮方式をサポートしているため、S3のコストを削減することができます。
また、パーティション分割したり、ファイル形式を列指向ストレージ形式(Apache Parquet形式など)に変更することで、Amazon Athenaのパフォーマンス向上とコスト削減を実現することができます。詳しくはまたの機会で紹介したいですね。
Amazon Athena、いかがでしたでしょうか。Amazon AthenaはS3のファイルを手軽にビジネス戦略に活かすことができるかもしれません。

執筆者プロフィール

- tdi パナソニック事業部
- 「IT技術もエンジニアも日々進化」がモットー。趣味は登山とドライブ。最近の癒しは海遊館のワモンアザラシ。