
はじめに
自然言語は、一定の文明的背景を持つ人たちがコミュニケーションをとるために自然に発展してきた言語であり、それをコンピュータに処理させる一連の技術は自然言語処理(Natural Language Processing、略称:NLP)と呼ばれています。近年、流行のAI技術の中でも、コンピュータに自然言語を理解させる技術(いわゆるNatural Language Understanding、略称:NLU)は難易度の高い分野として知られています。
Stanford Parserを使ってみる
自然言語処理について
どの自然言語処理でも大抵、形態素解析、構文解析、文脈解析、意味解析に分けられます。高理解度の文脈解析と意味解析の精度はまだ高くありませんが、形態素解析と構文解析は近年大学やAI研究機構の研究開発で高い精度の結果が得られています。今回、実際にアメリカのStanford大学が開発したStanford Parserを使って、形態素解析、構文解析がどこまで進化してきたかを体験してみました。
Stanford大学がStanford Parserの解析結果を視覚的に確認できるサイトを公開しています。
(http://corenlp.run/)
では、下記のごく普通の英語例文をStanford Parserで形態素解析と構文解析について解析してみます。
Mr. Smith put his dogs on the table.
形態素解析
形態素解析では下記の図のように各単語の品詞を解析結果として返します。この例ではNNP(固有名詞)、VBD(過去形動詞)、PRP$(所有代名詞)、NNS(複数名詞)、IN(前置詞)、DT(限定詞)、NN(名詞)などが並んでいます。これらの品詞情報が後ほどの構文解析の結果を大きく左右します。

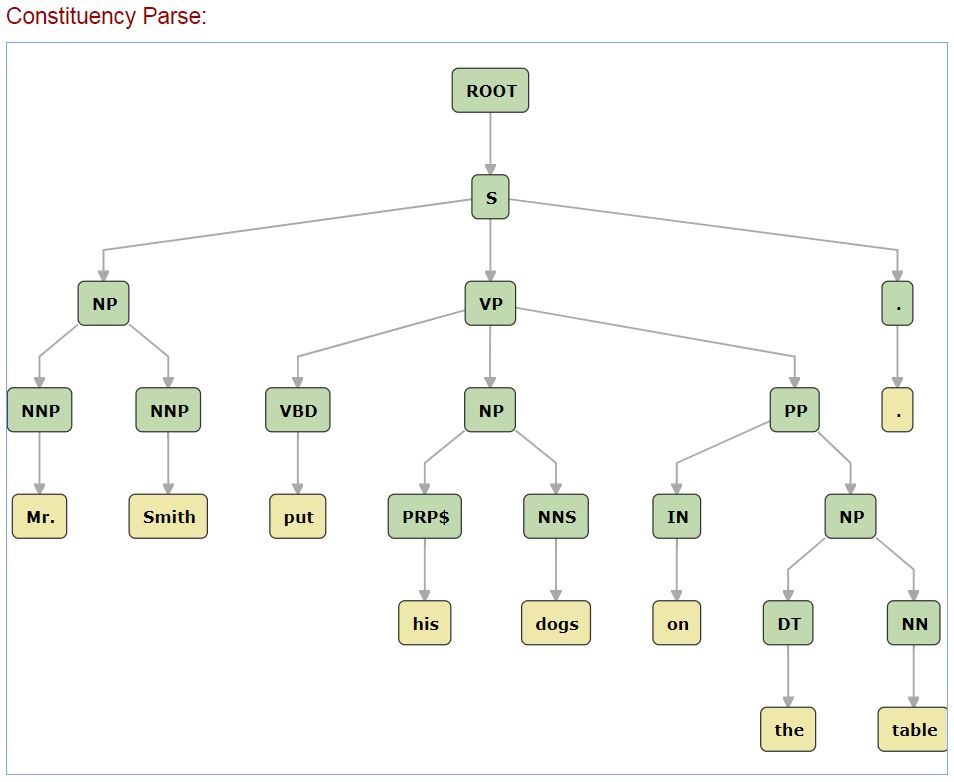
構文解析
構文解析器(Parser)が各単語の品詞に基づき、英語の文法規則に従って、解析結果を構文木で表します。下図の構文木を見ると、一部単語がクループ化されることが分かります。グループ化された単位が節(Phrase)と呼ばれ、文法では大きな意味を持ちます。例えば、[Mr.] と [Smith]という固有名詞(NNP)を組み合わせた名詞節(NP)が主語<S>となり、動詞(VBD)[put] と名詞節(NP)[his dogs] と前置節(PP)[on the table]が組み合わせた動詞節(VP)が、それぞれ、動詞<V>、目的語<O>、補語<C>の役割を担います。この結果、中学で学んだ英語の基本文型の一つであるSVOCになります。この構文木があれば、コンピュータは文法的に言語を解釈することができるようになります。
構文解析応用例
文章要約
今回最も皆さんに紹介したいのはもう一つの構文木です。ここでは仮に、依存木(Dependency Tree)と呼ぶこととします。下記の図のように単語間の係り受け関係(Dependency)がこの依存木に含まれています。例えば、固有名詞(NNP)[Smith] と過去形動詞(VBD)[put] の間には主語と述語の修飾関係(nsubj)、過去形動詞(VBD)[put] と名詞(NNS)[dogs]の間には述語と直接目的語の修飾関係(dobj)があります。この依存木の情報から簡単に文章を要約できることが分かります。こちらの例文では「スミスは犬を置く」に要約されます。

木構造のデータモデルは取り扱いにくいイメージが強いですが、実際に依存木を求めるときに、Stanford Parserから下記のようなフラットな構造のレスポンスが得られますので、容易にアプローチすることができます。
root ( ROOT-0 , put-3 )
compound ( Smith-2 , Mr.-1 )
nsubj ( put-3 , Smith-2 )
nmod:poss ( dogs-5 , his-4 )
dobj ( put-3 , dogs-5 )
case ( table-8 , on-6 )
det ( table-8 , the-7 )
nmod:on ( put-3 , table-8 )
係り受け解析
また、数字などに敏感な方にはこんな使い方でもできます。下記の例文をStanford Parserで解析してみました。
That table is at least 60 cm in length, but it is not less than 10 kg in weight.
単純な数字だけでなく、[at least]、[not less than] などの範囲まで認識が可能になります。また、各数字が修飾する対象がどんな内容なのかは、依存木の情報から得られます。その結果、[60 cm] が修飾しているのは [weight] ではなく、[length] であること、また、文脈解析で後半の [it] が [That table] を指していることが分かります。

実は最近私が参画していたプロジェクトでは、Stanford Parserの繊細な構文解析処理を用いて、いくつもの難題を解かせたことで、Stanford Parserのすごさを実感しました。そして、自然言語処理にはまだ発見できていない価値がきっとあると思います。MISOで自然言語処理について発信することにより、新たな価値が皆さんの知恵によって発見されることを願っています。
さいごに
自然言語は非常に自由度の高いものであり、時間と共に進化し続けています。新しい単語の出現、変則な文法で組み立てられた言葉、そして解釈によって二つ以上の意味を持つ文章、例えば、[Colorless green ideas sleep furiously]問題など、自然言語理解にはまだ様々な課題が残っています。近年、解析の過程に機械学習(Machine Learning)が組み込まれ、一部の課題が改善されましたが、依然として曖昧性など完全に解決することはできないものもあります。それは自然言語の特徴でもあります。これからも自然言語処理がAIの一つの分野として、人類にさらなる貢献をし続けると信じています。

執筆者プロフィール

- tdi AI・コグニティブ推進部
- AI技術に興味を持ち始め、ソリューションコンサルティング部へ。IBM Watson、自然言語処理に関する仕事を経て、企業向けIoTの仕事もするようになりました。マイハウスのIoT化も着々進めております。最近ではデザインシンキングに興味を持ち始めました。



