目次
はじめに
この記事では強化学習における基本的な内容の解説および、強化学習の手法の1つであるQ学習を使ったプログラムの作成を行います。プログラムのお題は崖を避けながらゴールを目指す「崖歩き問題」です。本稿を通して、強化学習に関する基本的な用語や主要な手法を把握し、Q学習を使った簡単なシミュレーションから強化学習の一連の流れを理解していただけると幸いです。
強化学習の目標は、環境から得られる報酬の合計が最大になる行動の選び方を獲得することです。より良い行動を選択するためには現在の状況や行動を評価することが重要になります。そこで、現在の状況や行動がどれだけ良いかを数値化した状態価値と行動価値について説明し、これらの推定方法として主要な手法を紹介します。紹介した手法の中で特に重要とされているQ学習を崖歩き問題(崖を避けながらゴールを目指す問題)に適用してみます。最後にQ学習における問題点を解消する方法として深層強化学習を紹介します。
強化学習とは
強化学習とは、機械学習の一種です。試行錯誤を繰り返しながら適切な制御方法を獲得する手法で、エージェントと環境が相互にやり取りを行いながら学習を進めます。エージェントは環境から状態と呼ばれる現在の状況のようなものを観測して、何かしらの行動を選択します。環境はエージェントの行動を受けて状態を変化させると同時にエージェントに報酬を渡します。このようなやり取りをエピソードと呼ばれる期間繰り返します。エピソードは有限長の場合もあれば無限長の場合もあります。
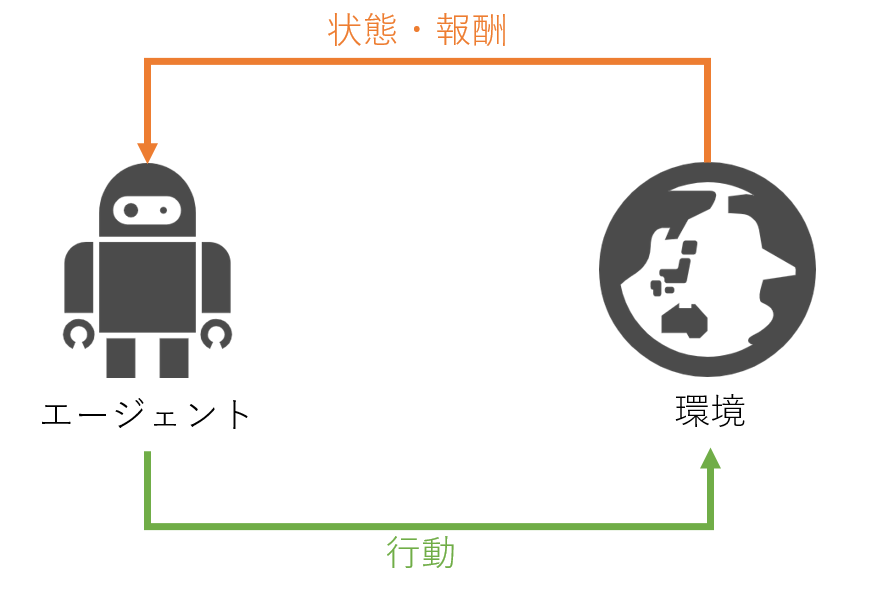
エージェントの目標は1回のエピソードで得られる報酬の合計が最大になるような行動の選び方(方策)を学習することです。
このような方策を得るためには、例えば各状態に対して将来どれくらい報酬が貰えそうか(状態価値)を計算して、その値が高い状態をたどるように行動を選択する方法が考えられます。また、各行動に対して将来どれくらい報酬が貰えそうか(行動価値)を計算して、その値が高い行動を選ぶようにするという方法も考えられます。
いずれの方法に対しても基本となる概念である収益について説明した後に、状態価値と行動価値の定義を紹介します。
収益
環境から得られた報酬の合計を収益と呼びます。ただし、遠い未来に得られる報酬は小さくなるように修正します。次の式はt回目の行動時の収益を表しています。
![]()
Rは環境から得られた報酬を表します。また、γは修正用のパラメータで時間割引率と呼び、0から1の間の値を取ります。時間割引率を使う理由の一つは、収益は一般には無限に報酬が加えられるため、値が大きくなりすぎることを避けるためです。また、行動経済学の観点から、同じ報酬であっても遠い未来よりも直近に得られる報酬の方が大きく見えるという性質を反映していると解釈できます。
収益という概念を使うことで、環境から観測される状態やエージェントが選択する行動に対して価値を定めることができます。状態や行動の価値を適切に評価できるように学習を進めることで、最適な行動方策を獲得できるようになります。
状態価値
状態価値とは、ある状態に到達したときに最終的にどれくらいの収益が得られそうかを表した値です。ある状態にいるときに現在の方策に従って行動したときの収益の期待値で定義します。
![]()
sは状態、πは方策を表しています。この値を使うことで、どの状態に移行すれば高い収益が得られそうかわかるようになります。
行動価値
行動価値とは、エージェントがある行動を選択したときに最終的にどれくらいの収益が得られそうかを表した値です。ある状態である行動を選択し、以降は方策に従って行動したときの収益の期待値で定義します。
![]()
aは行動、sは状態、πは方策を表しています。この値を使うことで、どの行動を選択すれば高い収益が得られそうかわかります。
主要な学習手法
状態価値や行動価値を正しく評価できるように学習することで、最適な行動方策を獲得できます。しかし、状態価値や行動価値を定義通り計算しようとすると、期待値を計算することになるために一般には計算量が膨大になってしまいます。そこで、効率良くこれらの価値を学習する主要な手法として、動的計画法、モンテカルロ法、TD法を紹介します。特にTD法の中でも行動価値を推定する代表的な手法としてSARSAとQ学習についても紹介します。
動的計画法
動的計画法では状態価値(行動価値)の計算を切り分けて、1ステップの計算に着目し、それ以降のステップの計算は後回しにする手法です。しかし、計算を切り分けているとは言え、ある状態からある状態へ変化する確率(状態遷移確率と呼びます)や報酬関数といった環境の情報を使用するため、これらの情報が必要です。
モンテカルロ法
動的計画法を使うためには状態遷移確率や報酬関数が必要です。しかし、一般的には環境モデルが未知な状況もあるので、状態遷移確率や報酬関数を使わない学習手法が必要になります。モンテカルロ法では、エピソード終了までエージェントに環境とのやり取りを繰り返し実施させて、得られた経験を使って状態価値(行動価値)を推定します。なお、モンテカルロ法は強化学習特有の用語ではなく、データのサンプリングを繰り返して、その結果から推定する手法の総称です。
TD法
モンテカルロ法は状態価値(行動価値)の推定に環境モデルの情報を必要としませんが、エピソードが終了して収益が確定しなければ状態価値(行動価値)の更新ができないという問題点があります。この問題を回避する手法としてTD法(Temporal Difference法)があります。この手法では、一定ステップの情報に限定して計算を進める動的計画法の考え方と、実際に経験した値を使うというモンテカルロ法の考え方を併せた手法です。TD法の中でも行動価値を推定する代表的な手法であるSARSAとQ学習を紹介します。
SARSA
SARSAは行動価値の推定量Q(s, a)を更新する手法で、更新のために行動を選択したときの報酬および次の状態と方策に従った行動を取得します。
![]()
SARSAという名前は学習に使用するデータ(s, a, R, s’, a’)から名付けられています。
Q学習
Q学習でも行動価値の推定量Q(s, a)を更新しますが、次ステップにおける行動価値の中で最大値を使用します。
![]()
SARSAとは違い、遷移した状態での最も良い行動を使っているため更新に使う行動と実際に選択する行動は異なることに注意してください。
Q学習の実装
ここでは後述するDQNなどに発展する重要な手法であり、強化学習の手法の1つであるQ学習を使ったプログラムの実装をします。問題設定としては崖歩き問題(Cliff Walking)を考えます。崖歩き問題とは、エージェントが毎時刻上下右左のいずれかに進みながらスタートから崖を避けつつゴールを目指す問題で、ルールは次の通りです。
- エージェントは「上、下、右、左」の4つの行動をとることができる
- エージェントは選択した方向に1マス進む
- エージェントが崖に移動すると、-100の報酬を得てエピソードが終了する
- エージェントがゴールに移動すると、1の報酬を得てエピソードが終了する
- エージェントが1マス進み、ゴールや崖でなければ-1の報酬が得られる
- エピソード終了後には、エージェントは初期位置に戻り、次のエピソードを開始する
まずは必要なモジュールをインポートします。
|
1 2 3 |
import numpy as np import pandas as pd import matplotlib.pyplot as plt |
グリッドワールドの定義
今回の問題に使用するグリッドワールドを定義します。グリッドワールドは縦10マス、横20マスとします。スタートは青い丸で、ゴールは橙の四角で、崖は赤いバツで表します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
def plot_world(steps=[]): fig = plt.figure(figsize=(10, 5)) ax = plt.gca() # 描画範囲を指定 ax.set_xlim(0, 20) ax.set_ylim(0, 10) # グリッドの間隔を指定 x_line = np.linspace(0, 20, 21) y_line = np.linspace(0, 10, 11) ax.set_xticks(x_line) ax.set_yticks(y_line) # マーキング _ = ax.plot([0.5], [0.5], marker="o", markersize=20, c="b") # エージェント _ = ax.plot([19.5], [0.5], marker="D", markersize=15, c="orange") # ゴール # 崖の描画 for i in range(15): _ = ax.plot([3.5+i], [0.5], marker="x", markersize=20, c="r") _ = ax.plot([3.5+i], [1.5], marker="x", markersize=20, c="r") for i in range(20): _ = ax.plot([0.5+i], [8.5], marker="x", markersize=20, c="r") _ = ax.plot([0.5+i], [9.5], marker="x", markersize=20, c="r") bad_points_x = [9.5, 4.5, 14.5] bad_points_y = [2.5, 6.5, 6.5] for x, y in zip(bad_points_x, bad_points_y): _ = ax.plot([x], [y], marker="x", markersize=20, c="r") _ = ax.plot([x+1], [y], marker="x", markersize=20, c="r") _ = ax.plot([x], [y+1], marker="x", markersize=20, c="r") _ = ax.plot([x+1], [y+1], marker="x", markersize=20, c="r") for s in steps: x_agent = s % 20 y_agent = s // 20 _ = ax.plot([0.5+x_agent], [0.5+y_agent], marker="o", markersize=12, c="b") # エージェント plt.grid() plt.show() |
引数のstepにエピソード内の状態の履歴を渡すことで、エージェントが移動した経路を表示できるようにしてあります。定義したグリッドワールドを表示させてみます。
|
1 |
plot_world() |
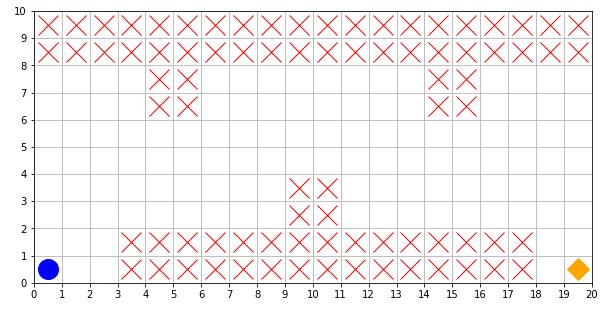
エージェントの目標は、青い丸から橙の四角へと赤いバツを避けながら移動するための行動方策を学習することになります。エピソードを終了させる状態を定義します。そのためにグリッドワールドの一つ一つのマスに対して次のようにして番号を振り分けます。
- 左下を0番とする
- N番の右隣にマスがある場合は、右隣のマスをN+1番とする
- N番の右隣にマスがない場合は、一番左に戻って一つ上をN+1番とする
このルールで番号を振り分けると、初期位置は0番でゴールは19番、初期位置の上は20番になります。番号が状態としてエージェントに観測されます。崖のマスに対応する番号とゴールに対応する番号をdone_pointsというリストに格納します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# エピソードを終了させる状態(崖とゴールの状態)を定義 done_points = [] for i in range(15): done_points.append(i+3) done_points.append(i+3+20) for i in range(20): done_points.append(20*8+i) done_points.append(20*9+i) point_x = [9, 4, 14] point_y = [2, 6, 6] for x, y in zip(point_x, point_y): done_points.append(20*y+x) done_points.append(20*y+(x+1)) done_points.append(20*(y+1)+x) done_points.append(20*(y+1)+(x+1)) # ゴール done_points.append(19) |
選択可能な行動の定義
各状態において、エージェントが選択できる行動を定義します。状態は200種類あり、各状態において4種類の行動があるので、200×4の行列で表現します。選択できる行動は1が、選択できない行動はnp.nanが入るようにします。例えば、状態0から19では下方向に移動できないため、それぞれの状態において下方向を表す箇所にはnp.nanが入ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 状態と行動の表 # theta_0[状態, 行動] = 1 or np.nan # 行動は0:上に移動、1:右に移動、2:下に移動、3:左に移動を表す # theta_0の値が1なら行動選択可能、np.nanなら行動選択不可を表す theta_0 = np.ones((10*20, 4)) # 選択不可能の行動を設定 for i in range(20): theta_0[i][2] = np.nan # 状態0~19(下端)では下移動を選択できない theta_0[-(i+1)][0] = np.nan # 状態180~199(上端)では上移動を選択できない for i in range(10): theta_0[i*20][3] = np.nan # 左端では左移動を選択できない theta_0[i*20+19][1] = np.nan # 右端では右移動を選択できない |
学習用関数の定義
先ほど定義した選択可能な行動を行動選択確率に変換する関数を定義します。初期状態では行動価値が未定なので、各行動に対して平等に確率を設定します。
例えば、初期状態では上方向と右方向のみ移動可能なので、上を選択する確率を50%、右を選択する確率を50%、他の行動は0%になるようにします。
|
1 2 3 4 5 6 7 8 9 10 |
# thetaを行動選択確率に変換 def theta2pi(theta): a, b = theta.shape pi = np.zeros((a, b)) for i in range(a): pi[i] = theta[i] / np.nansum(theta[i]) # np.nanを0に変換 return np.nan_to_num(pi) |
次に行動を選択する関数を定義します。今回はε-greedy法を採用しており、εに設定した確率で学習した価値に関わらずランダムに行動を選択します。このようにすることで様々な行動を試すようになります。
|
1 2 3 4 5 6 7 8 9 |
def get_action(s, Q, epsilon, pi): # Q関数から行動を選択 # epsilonの確率でランダムに行動を選択 if np.random.rand() < epsilon: action = np.random.choice(np.arange(4), p=pi[s]) else: # 一番価値が高い行動を選択 action = np.nanargmax(Q[s]) return action |
選択した行動に応じて状態を変化させる関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def get_next_state(s, a): # 行動から状態を変化させる if a == 0: # 上に移動 next_state = s + 20 elif a == 1: # 右に移動 next_state = s + 1 elif a == 2: # 下に移動 next_state = s - 20 else: # 左に移動 next_state = s - 1 return next_state |
行動価値関数を更新する関数を定義します。ゴール時には次の状態がないため条件分岐をして計算式を変えています。
|
1 2 3 4 5 6 7 |
def Q_learning(s, a, r, s_next, lr, gamma, done): # 行動価値関数の更新 if done: Q[s, a] = Q[s, a] + lr*(r - Q[s, a]) else: Q[s, a] = Q[s, a] + lr*(r + gamma*np.nanmax(Q[s_next]) - Q[s, a]) return Q |
1エピソード学習させる関数を定義します。状態が19に遷移すると報酬を1だけ与えループを抜けるようにし、19以外のエピソードを終了させる状態に遷移すると報酬を-100与えループを抜けるようにしています。また、それ以外の状態では報酬を-1与えるようにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def run(Q, epsilon, lr, gamma, pi, done_points): s = 0 # 初期位置 a_next = get_action(s, Q, epsilon, pi) # 状態の遷移を記録 state_history = [] while True: a = a_next s_next = get_next_state(s, a) if s_next == 19: # ゴールに遷移した場合 r = 1 a_next = np.nan done = True elif s_next in done_points: # ゴール以外の終了ポイントに遷移した場合 r = -100 a_next = np.nan done = True else: r = -1 # 次の行動を取得 a_next = get_action(s_next, Q, epsilon, pi) done = False # Q関数を更新 Q = Q_learning(s, a, r, s_next, lr, gamma, done) state_history.append(s) if done: state_history.append(s_next) break else: s = s_next return state_history, r |
実行
|
1 2 3 4 5 6 7 8 9 |
# ハイパーパラメータの設定 lr = 0.1 gamma = 0.9 epsilon = 0.5 episode = 1000 # 行動価値と方策を初期化 Q = np.random.rand(*theta_0.shape) * theta_0 pi_0 = theta2pi(theta_0) |
今回は1000エピソード学習させます。また、ε-greedy法に使用するεは徐々に小さくするようにします。このようにすることで最初はランダムに行動を選択して、徐々に学習した価値に基づき行動を選択するようにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
steps = [] rewards = [] for episode in range(episode): if epsilon < 1e-100: epsilon = 0.0 else: epsilon /= 4 h, r = run(Q, epsilon, lr, gamma, pi_0, done_points) steps.append(len(h)) rewards.append(r) |
結果確認
|
1 2 3 4 5 6 7 8 9 10 11 |
# ゴールしたエピソードと崖に落ちてしまったエピソードの取得 goal_episode = np.where(np.array(rewards)>0, 1, np.nan) nongoal_episode = np.where(np.array(rewards)<0, 1, np.nan) # 可視化 fig = plt.figure(figsize=(20, 10)) plt.scatter(x=np.arange(len(steps)), y=steps*goal_episode, c="b", s=15, label="success") plt.scatter(x=np.arange(len(steps)), y=steps*nongoal_episode, c="r", s=15, label="failed") plt.grid() plt.legend(fontsize=30) plt.show() |
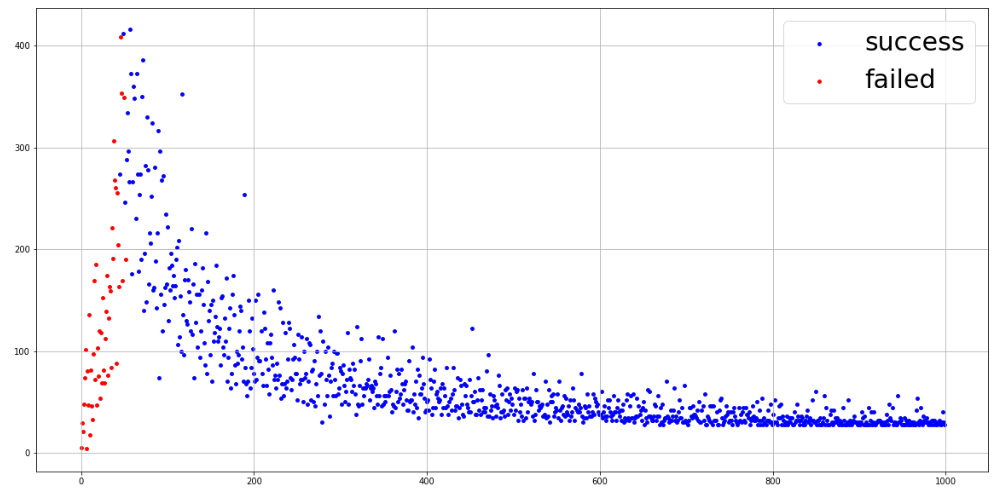
縦軸は1エピソードでのステップ数を表し、横軸はエピソード番号を表しています。赤い点は崖に侵入してしまったエピソードで、青い点はゴールに到達することができたエピソードを表しています。60エピソードごろからゴールできるようになり、少しずつゴールまでに要したステップ数が減っています。
最後に最終エピソードでのエージェントの移動経路を確認してみます。
|
1 |
plot_world(h) |
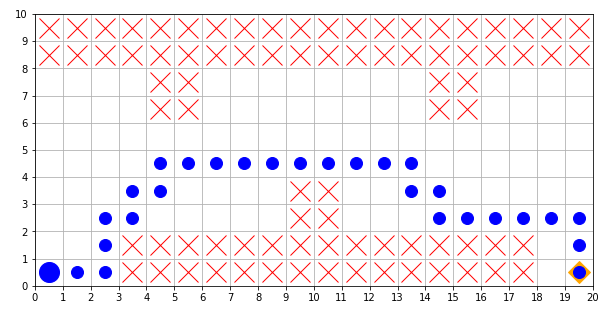
青い丸はエージェントが通った経路を表しています。崖を避けながらゴールに到達していることが確認できます。また、崖が近くにあったとしても、スタートからゴールまで最短経路で進んでいます。これはQ学習の特徴の一つで、価値関数の更新の際に価値が最大になる行動を使うことにより、崖に落ちて報酬が小さくなることよりもできるだけ早くゴールして高い報酬を貰うことを優先します。一方で今回は実装しませんでしたが、SARSAでは安全策を採用して罰則を避ける特徴があります。
深層強化学習
Q学習は、状態と行動のすべての組み合わせに対し価値を保持しているため、これらの組み合わせが少ない問題に対してのみ適応することができます。一方で現実はより複雑で、状態と行動の組み合わせが膨大になる可能性があります。例えば空調を強化学習で制御することを考えると、室温や湿度などを状態として使うことが考えられますが、これらは連続値のため状態の数だけでも膨大になってしまいます。
そこで、状態と行動すべての組み合わせに対して価値を保持するのではなく、ニューラルネットワークを使って関数として近似する手法が考えられました。このような関数近似を使った強化学習を深層強化学習と呼びます。ここでは深層強化学習のアルゴリズムをいくつか紹介します。
DQN
DQNはDeep Q Networkの略で、行動価値関数をニューラルネットワークに置き換えて、Q学習を実施する手法であり、学習を安定させるためにいくつかの工夫を施しています。
学習の安定化のための工夫の一つとして、経験再生(Experience Replay)が挙げられます。ニューラルネットワークを各ステップでその内容を学習させようとすると、時間的に近い情報は相関が大きいため、学習が安定しないという問題があります。そこで経験再生では、エージェントが経験した情報をメモリに保存しておき、メモリからランダムに取り出した情報を使ってネットワークを学習させます。
また、DQNではターゲットネットワークと呼ばれる工夫も採用しています。Q学習では、行動価値関数の更新時に次の時刻の状態に対する価値の評価が必要になりますが、更新対象のネットワークと評価値計算用のネットワークを同じにしてしまうと学習が不安定になるという問題が発生します。そこで、評価用の行動価値関数として少し前のネットワークを使用します。この評価用のネットワークをターゲットネットワークと呼びます。
DDQN
DDQNはDouble DQNの略で、DQNの学習をより安定させる工夫を取り入れた手法です。DQNではターゲットネットワークの最大値を教師信号として使用しますが、DDQNでは行動選択用のネットワークにおける最善の行動を使ってターゲットネットワークの値を計算して、教師信号を定義します。
まとめ
今回は強化学習の基礎と、崖歩き問題へのQ学習の適用例を紹介しました。この記事ではQ学習を用いましたが、アルゴリズムによって得られる行動方策は異なります。また、状態と行動の組合せ数が膨大なる場合には深層強化学習の利用も考えなければなりません。このことから、問題設定や理想とする結果から手法の選択をする必要があります。


執筆者プロフィール

- tdi AI&データマネジメント推進部
-
以前からAIに興味があり、独学で勉強してきました。
現在AIエンジニアを担当しています。
自然言語処理、信号処理、強化学習など幅広く勉強しています。